
Statische Datenmaskierung für Amazon Redshift

Einführung
Die digitale Ära ist in vollem Gange, mit 67% der Weltbevölkerung, die jetzt das Internet nutzen. Diese weit verbreitete Adoption hat einen signifikanten Wandel hervorgerufen, von zahllosen Prozessen und Dienstleistungen online verlagert und wie wir leben, arbeiten und interagieren verändert. Organisationen müssen den Nutzen von Daten mit regulatorischer Compliance und Datenschutz ausgleichen. Eine wirksame Lösung ist die statische Datenmaskierung für Amazon Redshift. Diese Technik hilft dabei, vertrauliche Daten zu schützen und gleichzeitig ihre Verwendbarkeit für Entwicklung und Testing zu erhalten.
Lassen Sie uns untersuchen, wie die statische Datenmaskierung zur Sicherung Ihrer Amazon Redshift-Umgebung beitragen kann.
Verständnis für die statische Datenmaskierung
Was ist statische Datenmaskierung?
Die statische Datenmaskierung ist ein Prozess, der eine separate, maskierte Kopie von sensiblen Daten erstellt. Dieser Ansatz stellt sicher, dass die originalen Daten unverändert bleiben, während eine sichere Version für Nichtproduktionsumgebungen bereitgestellt wird.
Warum statische Datenmaskierung verwenden?
- Regulatorische Compliance
- Verringertes Risiko von Datenverstößen
- Sicherere Entwicklung und Testumgebungen
- Datenintegrität erhalten
Amazon Redshift-Funktionen für die statische Datenmaskierung
Amazon Redshift bietet integrierte Funktionen und nutzerdefinierte Funktionen (UDFs), um die Datenmaskierung zu implementieren. Lassen Sie uns einige Schlüsselfunktionen betrachten.
Die oben genannten Beispiele zeigen Datenmaskierungstechniken, erstellen jedoch keine separaten Tabellen mit maskierten Daten. Diese Methoden ähneln denen, die in der nativen dynamischen Datenmaskierung verwendet werden. Zum Erstellen von dauerhaften verschleierten Tabellen, verweisen Sie auf den Abschnitt ‘Implementierung der statischen Datenmaskierung’ weiter unten.
Eingebaute Funktionen
Redshift bietet mehrere integrierte Funktionen für grundlegende Maskierungsoperationen. Eine häufig verwendete Funktion ist REGEXP_REPLACE.
Beispiel:
SELECT REGEXP_REPLACE(email, '(.*)@', '****@') AS masked_email FROM users;
Bei dieser Abfrage wird der lokale Teil von E-Mail-Adressen maskiert, indem er durch Sternchen ersetzt wird.
Nutzerdefinierte Funktionen (UDFs)
Für komplexere Maskierungsanforderungen ermöglicht Redshift die Erstellung von UDFs mithilfe von Python. Hier ist ein Beispiel für eine UDF, die E-Mail-Adressen maskiert:
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;So verwenden Sie diese Funktion:
SELECT email, f_mask_email(email) AS masked_email FROM MOCK_DATA;
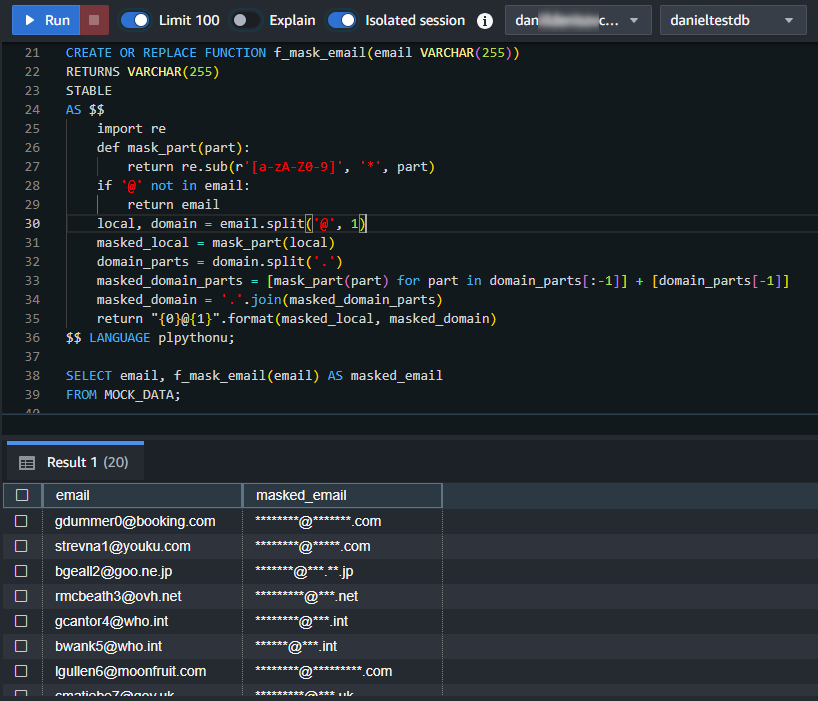
Python-Funktionen erweitern die Maskierungs- und Datenverarbeitungsfunktionen von Redshift erheblich. Sie ermöglichen die Implementierung von formatgerechter Verschlüsselung und komplexen Maskierungsverfahren. Mit Python können Sie benutzerdefinierte Maskierungsalgorithmen erstellen, die auf Ihre speziellen Bedürfnisse zugeschnitten sind.
Implementierung der statischen Datenmaskierung in Redshift
Nun, da wir die Grundlagen verstanden haben, betrachten wir, wie man statische Datenmaskierung in Redshift implementiert.
Schritt 1: Sensible Daten identifizieren
Identifizieren Sie zuerst, welche Spalten sensible Informationen enthalten, die maskiert werden müssen. Dies kann beinhalten:
- Persönlich Identifizierbare Informationen (PII)
- Finanzdaten
- Gesundheitsakten
Schritt 2: Maskierungsfunktionen erstellen
Entwickeln Sie Maskierungsfunktionen für jeden Datentyp, den Sie schützen müssen. Wir haben bereits ein Beispiel für E-Mail-Adressen gesehen.
Schritt 3: Maskierte Tabelle erstellen
Erstellen Sie eine neue Tabelle mit maskierten Daten:
CREATE TABLE masked_mock_data AS SELECT id, f_mask_email(email) AS email, first_name, last_name FROM Mock_data;
Schritt 4: Überprüfen der maskierten Daten
Überprüfen Sie die Ergebnisse, um sicherzustellen, dass die Maskierung korrekt ist:
SELECT * FROM masked_mock_data;
Statische Datenmaskierung mit DataSunrise
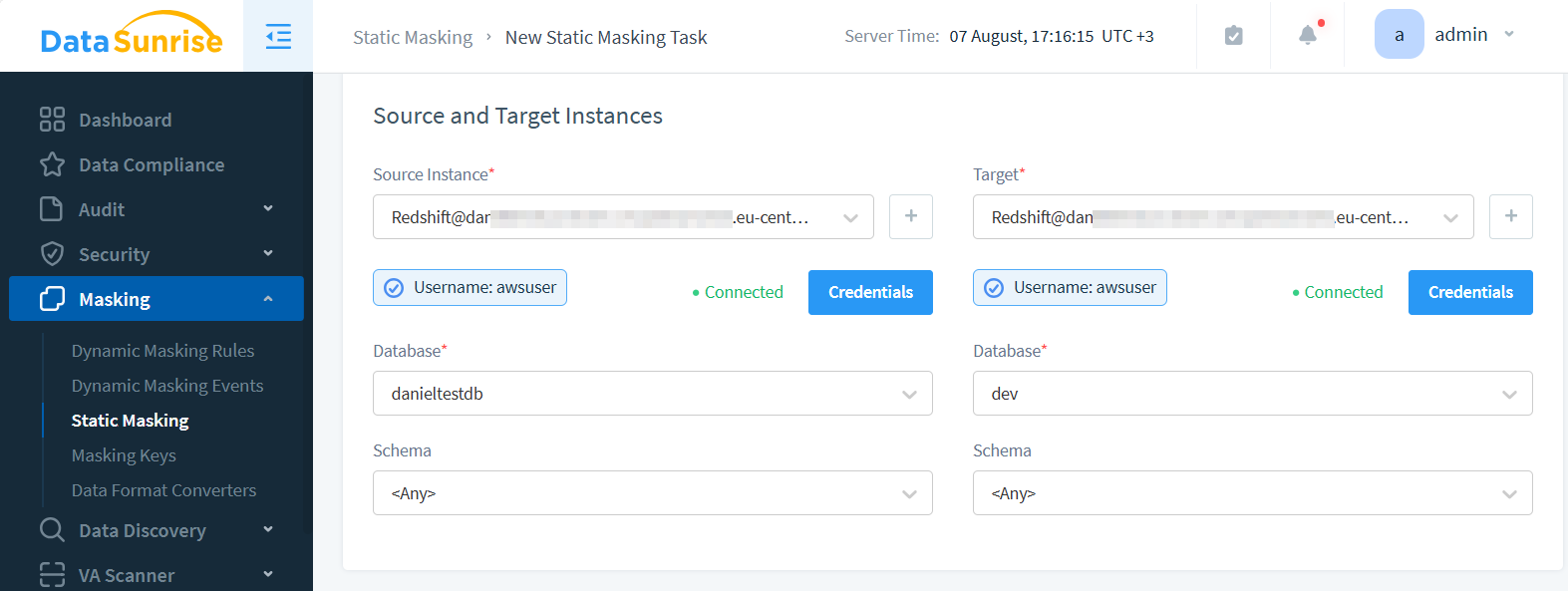
Zur Verwendung von DataSunrise für statisches Maskieren:
- Konfigurieren Sie die Verbindung zu Ihrem Redshift-Cluster
- Erstellen Sie in der Web-UI eine Maskierungsaufgabe
- Wählen Sie Quell- und Zieldatenbanken aus.
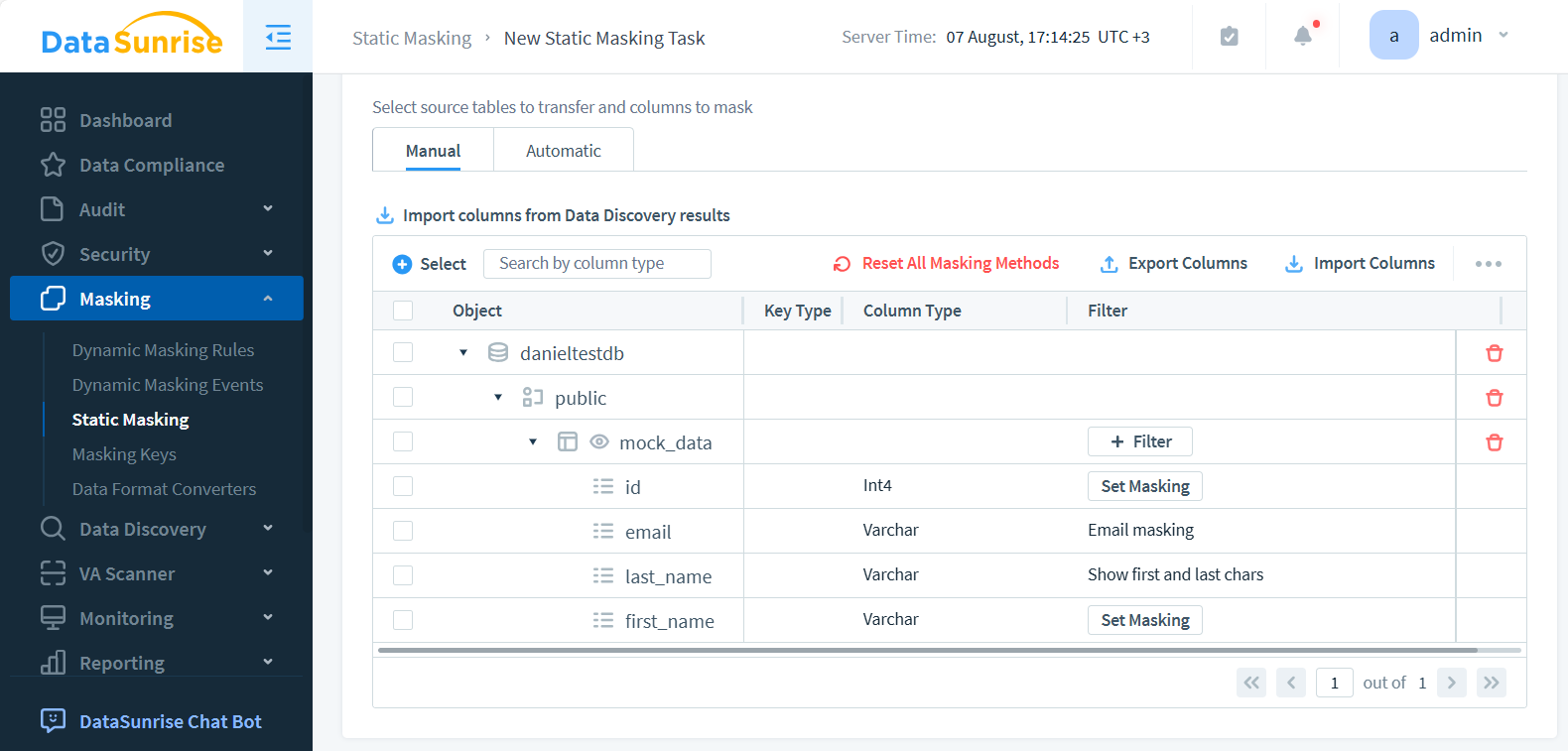
- Wählen Sie Ihre Zieldatenbankobjekte aus, die maskiert werden sollen
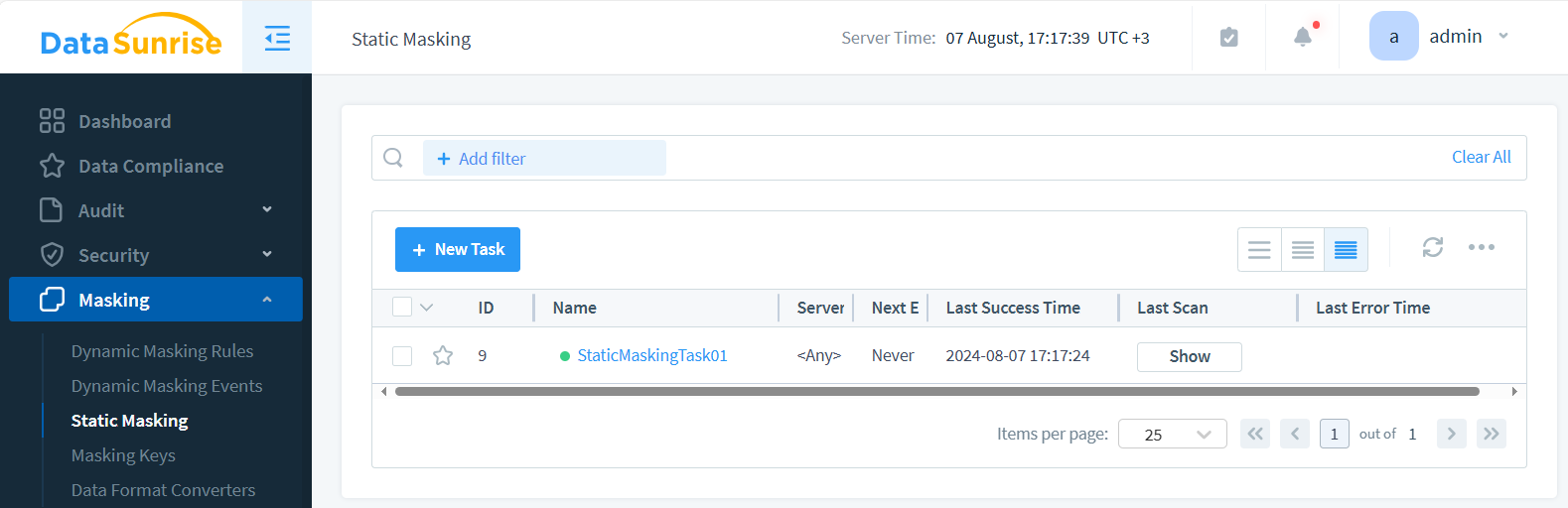
- Speichern und starten Sie die Aufgabe
Das Ergebnis in der Ziel-Tabelle sieht vielleicht folgendermaßen aus (abgefragt in DBeaver):
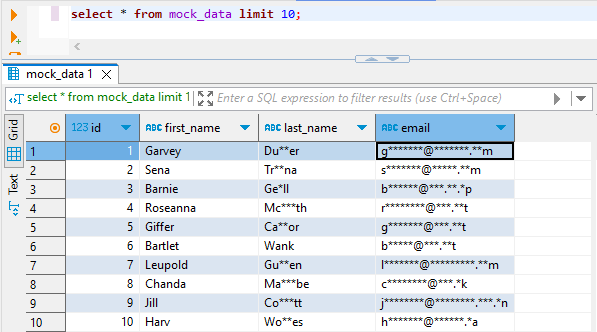
DataSunrise Maskierungsmethoden
DataSunrise bietet eine umfassende Auswahl an Datenmaskierungstechniken. Lass uns einige der mächtigsten und am häufigsten verwendeten Methoden untersuchen:
- Formatbeibehaltende Verschlüsselung behält das Originaldatenformat bei und verschlüsselt es gleichzeitig und stellt sicher, dass die Daten nach der Verschlüsselung weiterhin verwendbar sind. Das bedeutet, dass die verschlüsselten Werte immer noch ähnlich wie die Originaldaten aussehen, wodurch es leichter wird, mit ihnen zu arbeiten und sie zu analysieren. Dies ist besonders nützlich in Situationen, in denen das Format der Daten für die Verarbeitung oder Anzeige wichtig ist.
- Festgelegter String-Wert ist eine Technik, die verwendet wird, um sensible Daten mit einem vordefinierten String zu ersetzen. Dies kann für die Maskierung sensibler Informationen wie Kreditkartennummern oder Sozialversicherungsnummern nützlich sein. Das Ersetzen der tatsächlichen Daten durch einen festen String schützt die sensiblen Informationen vor unbefugtem Zugriff oder Anzeige.
- Nullwert ist eine weitere Methode zum Schutz sensibler Daten, indem sie mit einem NULL-Wert ersetzt wird. Dadurch werden sensible Informationen aus dem Datensatz entfernt, sodass niemand auf die Originaldaten zugreifen oder sie abrufen kann. Diese Methode behält möglicherweise nicht das Datenformat wie die formatbeibehaltende Verschlüsselung bei, hält jedoch effektiv sensible Informationen sicher.
DataSunrise bietet eine breite Palette von Maskierungsmethoden, die Ihnen flexible Optionen zur Verfügung stellen, um Ihre Daten zu schützen, ohne die Benutzerfreundlichkeit zu opfern. Mit über 20 verschiedenen Techniken, können Sie Ihre Datenschutzstrategie fein abstimmen, um spezifische Anforderungen zu erfüllen.
Vorteile der statischen Datenmaskierung für Amazon Redshift
Die Implementierung der statischen Datenmaskierung in Redshift bietet mehrere Vorteile:
- Verbesserter Datenschutz/li>
- Vereinfachte regulatorische Compliance
- Reduziertes Risiko einer versehentlichen Datenexposition
- Verbesserte Entwicklungs- und Testprozesse
- Erhaltene Datenverwendbarkeit
Durch das Maskieren sensibler Daten können Sie Informationen sicher in Ihrer Organisation teilen, ohne die Sicherheit zu gefährden.
Herausforderungen und Überlegungen
Obwohl die statische Datenmaskierung vorteilhaft ist, gibt es einige Herausforderungen zu beachten:
- Leistungsauswirkungen während des Maskierungsprozesses
- Wahrung der Referenzintegrität in maskierten Daten
- Sicherstellung konsistenter Maskierung über verwandte Tabellen hinweg
- Ausgleichen der Datenverwendbarkeit mit Sicherheitsanforderungen
Die Bewältigung dieser Herausforderungen erfordert sorgfältige Planung und Implementierung.
Schlussfolgerung
Die statische Datenmaskierung für Amazon Redshift ist ein leistungsstarkes Werkzeug zum Schutz sensibler Daten. Organisationen können integrierte und benutzerdefinierte Funktionen verwenden. Diese Funktionen helfen dabei, sichere und versteckte Kopien ihrer Daten zu erstellen. Dies ist nützlich für Test- und Entwicklungszwecke.
Denken Sie daran, dass der Datenschutz ein fortlaufender Prozess ist. Überprüfen und aktualisieren Sie Ihre Maskierungsstrategien regelmäßig, um sich den sich entwickelnden Bedrohungen und Compliance-Anforderungen zu stellen.
Wer auf der Suche nach fortschrittlicherem, Echtzeitschutz ist, bietet Lösungen wie DataSunrise Datenmaskierungsfunktionen. DataSunrise bietet benutzerfreundliche und hochmoderne Werkzeuge zur Datenbanksicherheit, einschließlich Audit und Data Discovery Funktionen. Um mehr darüber zu erfahren, wie DataSunrise Ihre Datenschutzstrategie verbessern kann, besuchen Sie unsere Webseite für eine Online-Demo.
