In-place Data Masking
Eine der Möglichkeiten, sensible Daten in Datenbanken zu schützen, ist die Datenmaskierung. In diesem Artikel werden wir mehr über In-place Data Masking und die Schritte zur Maskierung Ihrer Daten an Ort und Stelle mit DataSunrise Database Security erfahren.
Statische Maskierung und In-place Maskierung
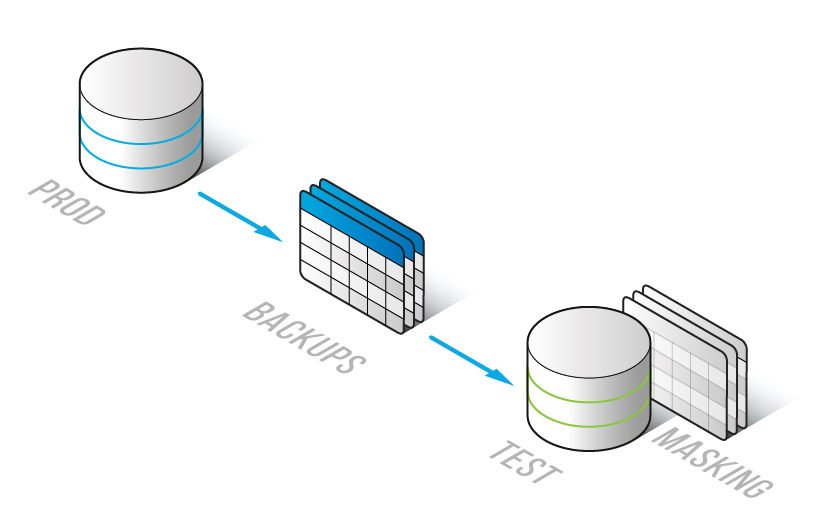
In-place Maskierung ähnelt der statischen Maskierung, da maskierte Daten dauerhaft maskiert werden und dieser Prozess nicht umkehrbar ist.
Der Unterschied zwischen In-place Maskierung und statischer Maskierung besteht darin, dass wir bei der statischen Maskierung zwei Datenbanken haben:
- Quell-Datenbank mit Originaldaten
- Ziel-Datenbank mit maskierten Daten
Im Falle der In-place Maskierung haben wir nur eine Datenbank, die gleichzeitig Quelle und Ziel ist.
Die In-place Maskierung wird am besten als Teil eines hybriden Datenbankschutzansatzes verwendet, bei dem verschiedene Datenbanken mit unterschiedlichen Maskierungstypen geschützt werden:
- statische Maskierung
- In-place Maskierung
- dynamische Maskierung
Diese Maskierungstypen sind alle in der DataSunrise Database Protection Suite verfügbar, um sicherzustellen, dass Ihre Datenbanken jederzeit geschützt sind.
In-place Maskierung in der Praxis
Manchmal ist die statische Maskierung keine gute Option:
- es verursacht zusätzliche Belastung der Produktionsdatenbank.
- es erfordert Zugriff auf die Produktionsumgebung von der Testumgebung. In einigen Systemarchitekturen ist dies physisch nicht möglich.
In diesem Fall können Daten mithilfe von Backups der Produktionsdatenbank in die Testumgebung repliziert werden. Backups jeder Produktionsdatenbank werden regelmäßig erstellt. Also brauchen wir nur:
- die Datenbank in der Testumgebung wiederherstellen
- Daten in unserer Testumgebung maskieren, wobei die ursprünglichen sensiblen Daten verloren gehen, da sie durch maskierte Daten ersetzt werden
Diese Methode der Maskierung wird als „In-place Maskierung“ bezeichnet, weil die Daten dort maskiert werden, wo sie sich befinden. Verwenden Sie diese Methode nur in nicht-produktiven Datenbanken.
DataSunrise versucht, alle eindeutigen Einschränkungen, Fremdschlüssel, Indizes, Prüfeinschränkungen und Standardwerteinschränkungen in einer Datenbank zu erhalten (nachdem sie maskiert wurden). Dies ist jedoch nicht immer möglich. Auto-Inkrement-Zähler werden ebenfalls beibehalten (außer für Redshift-Datenbanken).
Das In-place Tabellenfiltern funktioniert genauso wie bei der statischen Maskierung, das heißt, Daten, die die Filterbedingungen nicht erfüllen, werden dauerhaft gelöscht.
Schritte der In-place Maskierung von DataSunrise
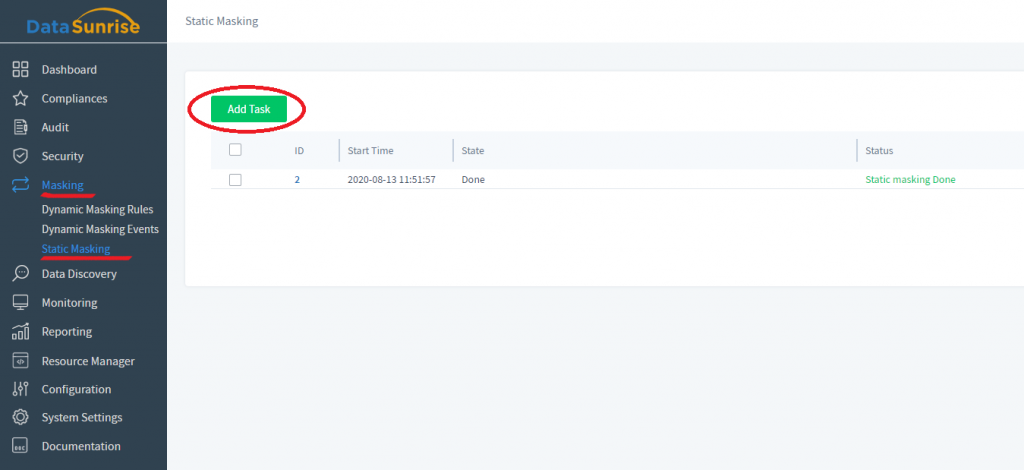
1) Wenn Sie Daten an Ort und Stelle maskieren möchten, wählen Sie im linken Bereich der DataSunrise-Benutzeroberfläche Masking → Statische Maskierung. Klicken Sie dann auf Aufgabe hinzufügen. Alle vorherigen In-place Maskierungsaufgaben werden hier zu Ihrer Referenz gespeichert.
2) Wählen Sie anschließend die Quellinstanz aus. Im Feld Zielinstanz wählen Sie Mask in Place. Bitte vergessen Sie nicht, Ihre Daten zu sichern, da die Originaldaten durch die In-place Maskierung dauerhaft durch maskierte Daten ersetzt werden. Wählen Sie danach die Datenbank aus, die Sie vor Ort maskieren möchten, und ein Schema. In dem folgenden Bild wird diese Datenbank „sales_summer” genannt und das Schema ist „public”. Im Abschnitt Übertragene Tabellen unten werden einige Kontrollkästchen automatisch aktiviert, um eine bessere Maskierung zu gewährleisten.
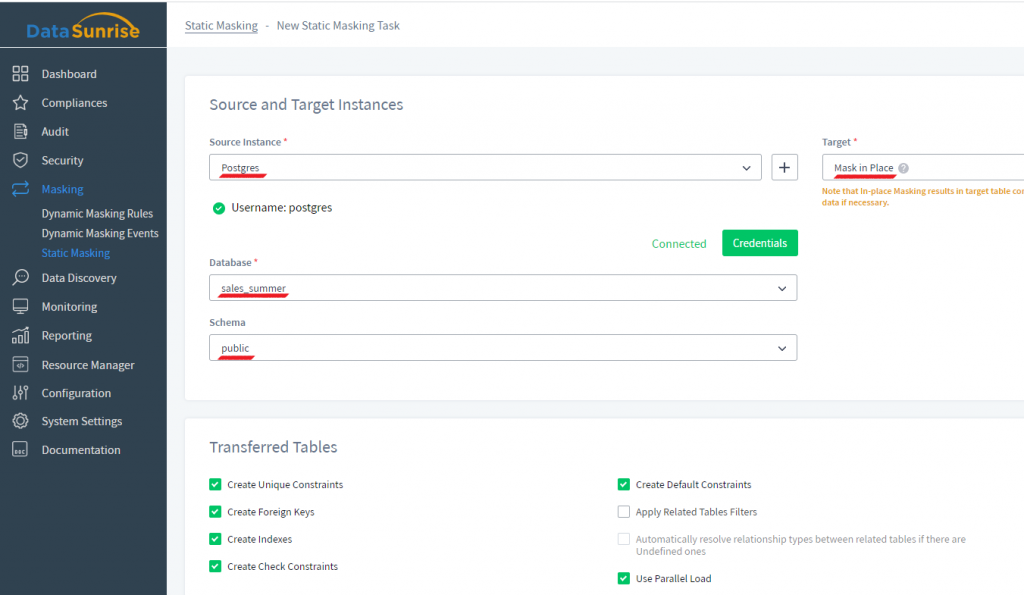
Hier ist, was diese Kontrollkästchen bewirken:
- Create Unique Constraints, Create Foreign Keys, Create Indexes, Create Check Constraints, Create Default Constraints bedeuten, dass diese Elemente im maskierten Schema, soweit möglich, neu aufgebaut werden.
- Use Parallel Load – erhöht die Maskierungsgeschwindigkeit für große Tabellen.
- Apply Related Tables Filters – der Filter wird nicht nur auf eine bestimmte Tabelle angewendet, sondern auch auf die mit dieser Tabelle über Fremdschlüssel verbundenen Tabellen.
- Automatically resolve relationship types between related tables if there are Undefined ones – bedeutet, dass verwandte Tabellen nicht nur vom Tabellenbeziehungstool (Konfiguration → Tabellenbeziehungen in der DataSunrise-Benutzeroberfläche), sondern auch basierend auf einem Algorithmus unter Verwendung indirekter Tabellenbeziehungen entdeckt werden.
3) Scrollen Sie nach unten und klicken Sie unter dem Abschnitt Übertragene Tabellen auf Auswählen.
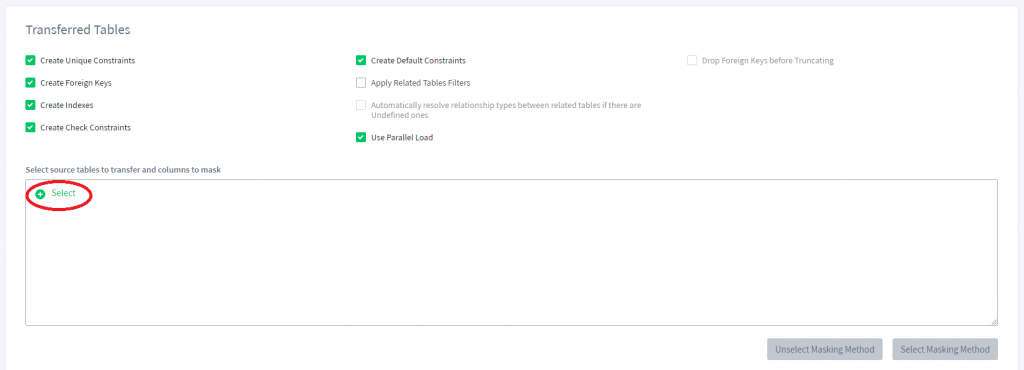
4) Wählen Sie nun das gesamte Schema aus, in dem wir mehrere Tabellen auswählen möchten (für uns ist es das „public” Schema), und klicken Sie auf Fertig.
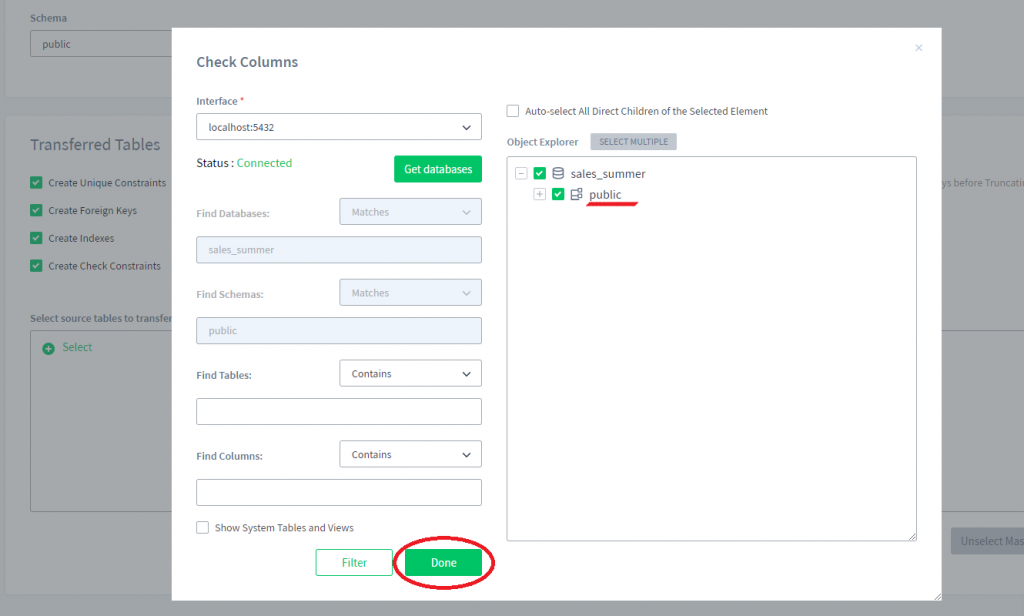
5) Nun können wir das ausgewählte „public” Schema erweitern und Spalten zur Maskierung auswählen.
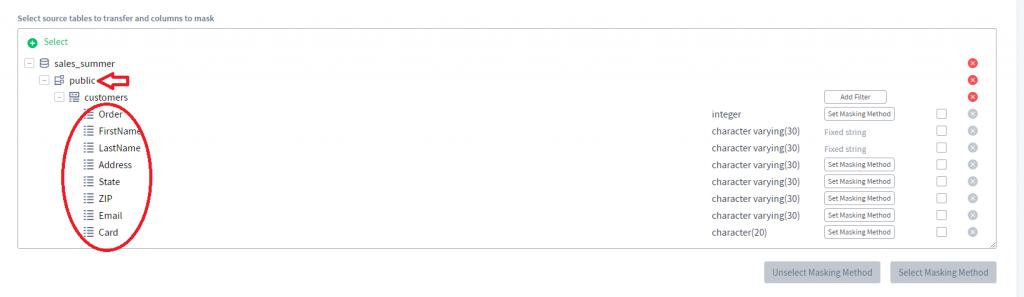
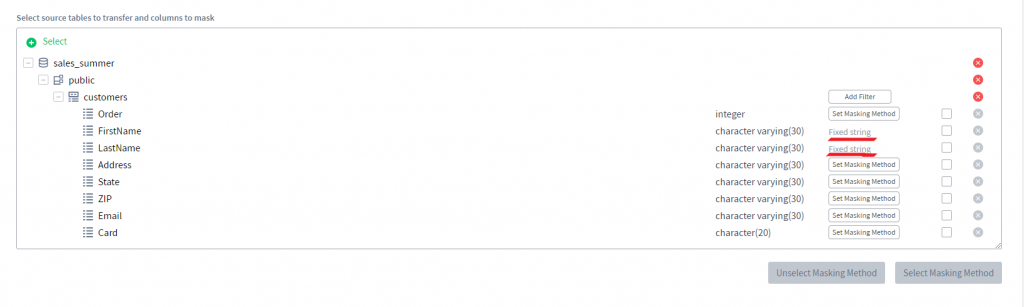
6) Für jede der Spalten können Sie eine Maskierungsmethode festlegen, indem Sie auf die Schaltfläche Maskierungsmethode festlegen klicken. Lassen Sie uns die Spalten FirstName und LastName mit einer festen Zeichenkette maskieren.
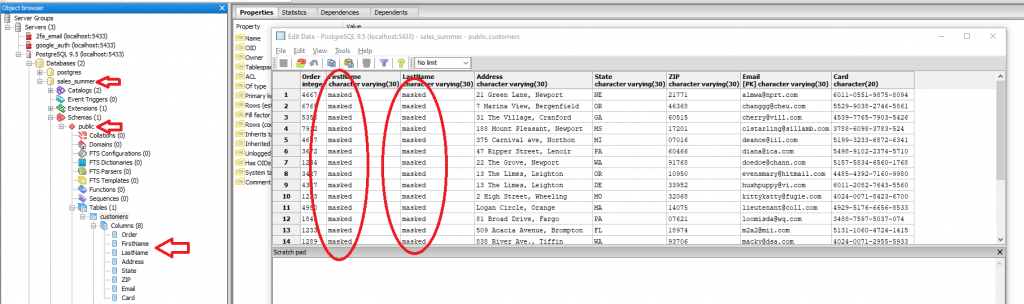
Im Bild unten können Sie sehen, wie unsere Daten jetzt in unserer PostgreSQL-Tabelle aussehen. Wie Sie sehen können, sind die Spalten FirstName und LastName nun maskiert.
In-place Maskierung von DataSunrise ist ein sehr praktisches Werkzeug, um Ihre sensiblen Daten jederzeit maskiert und unter Kontrolle zu halten.