Umfassender Leitfaden, wie man nach sensiblen Daten in Bildern sucht, die auf AWS S3 gehostet werden
Um unseren Kunden ein leistungsstarkes Tool zur Datenentdeckung bereitzustellen, haben wir kürzlich die OCR-Funktion (Optical Character Recognition) in unser Data Discovery-Modul integriert. Diese Funktion ermöglicht es Ihnen, nach sensiblen Daten wie persönlichen Daten, Kreditkartennummern, Führerscheinen usw. in Bilddateien zu suchen. Der Entdeckungsprozess wird automatisch ohne menschliche Eingriffe durchgeführt. OCR Data Discovery funktioniert derzeit nur mit AWS S3.
DataSunrise’s OCR DD basiert auf der Tesseract-Engine, die neuronale Netztechnologie zur Zeichenerkennung verwendet. Tesseract verwendet die Leptonica-Bibliothek, um Bilder in einem der folgenden Formate zu lesen:
- PNG
- JPEG
- TIFF
- JPEG 2000
- GIF
- WebP (einschließlich animierter WebP)
- BMP
- PNM
Wie es funktioniert
Sobald eine OCR Data Discovery-Aufgabe gestartet wird, durchläuft der Entdeckungsprozess die folgenden Phasen:
- DataSunrise durchsucht den Inhalt des angegebenen S3-Buckets nach Bildern.
- Der Vorprozessor der OCR-Engine bereitet erkannte Bilder für die weitere Verarbeitung vor, indem er sie kontrastreicher und schärfer macht.
- DataSunrise erkennt mit Hilfe der Tesseract OCR-Technologie unstrukturierten Text in Bildern und wendet die Data Discovery-Algorithmen bezüglich dieses Textes gemäß den Einstellungen Ihrer Data Discovery-Aufgabe an.
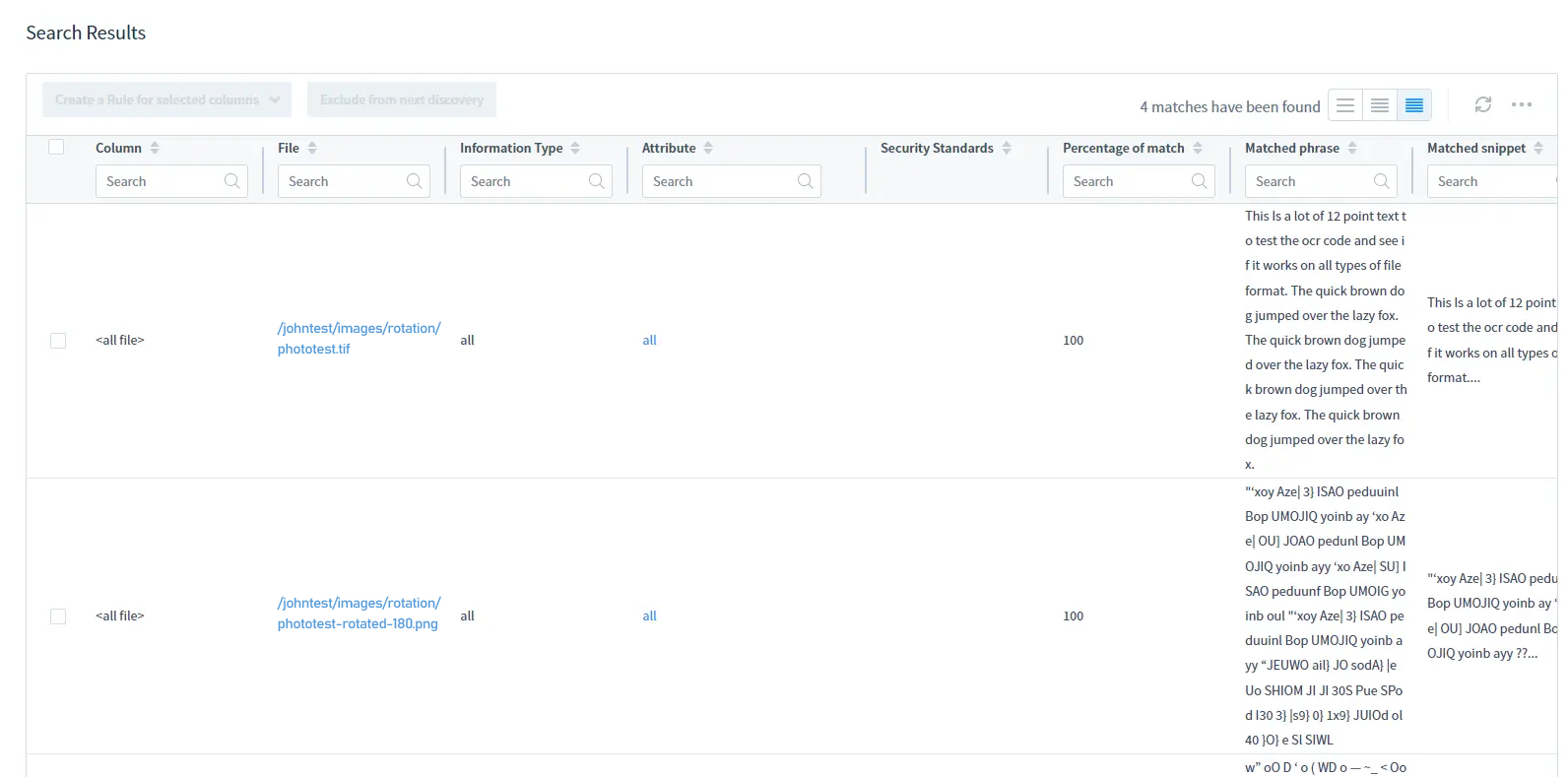
Als Ergebnis erhalten Sie die Namen und den Standort von Bilddateien, die sensible Daten enthalten, sowie diese Daten in einem DD-Bericht.
Konfigurieren einer OCR-Aufgabe in DataSunrise
Werfen wir nun einen Blick auf den Prozess der Erstellung einer OCR Data Discovery-Aufgabe.
Beachten Sie zuerst, dass OCR Data Discovery mit NLP Data Discovery Java 1.8+ erfordert.
Um OCR Data Discovery zu nutzen, müssen Sie Folgendes tun:
- Bevor Sie zum nächsten Schritt übergehen, erstellen Sie eine S3 DB-Instanz in DataSunrise (siehe Benutzerhandbuch von DataSunrise für Details).
- Navigieren Sie zu Data Discovery → Periodic Data Discovery
- Erstellen Sie eine Data Discovery-Aufgabe für Ihren S3-Bucket:
Füllen Sie die Allgemeinen Einstellungen aus:

- Benennen Sie die Aufgabe
- Wählen Sie den DS-Server aus, auf dem die Aufgabe gestartet werden soll
- Wenn Sie Data Discovery für mehrere DB-Instanzen durchführen möchten, aktivieren Sie das entsprechende Kontrollkästchen und wählen Sie die interessierten Instanzen aus
- Aktivieren Sie das Kontrollkästchen Berichte erzeugen, um einen Bericht entweder im PDF- oder CSV-Format zu erstellen.
In der Sektion Suchparameter:
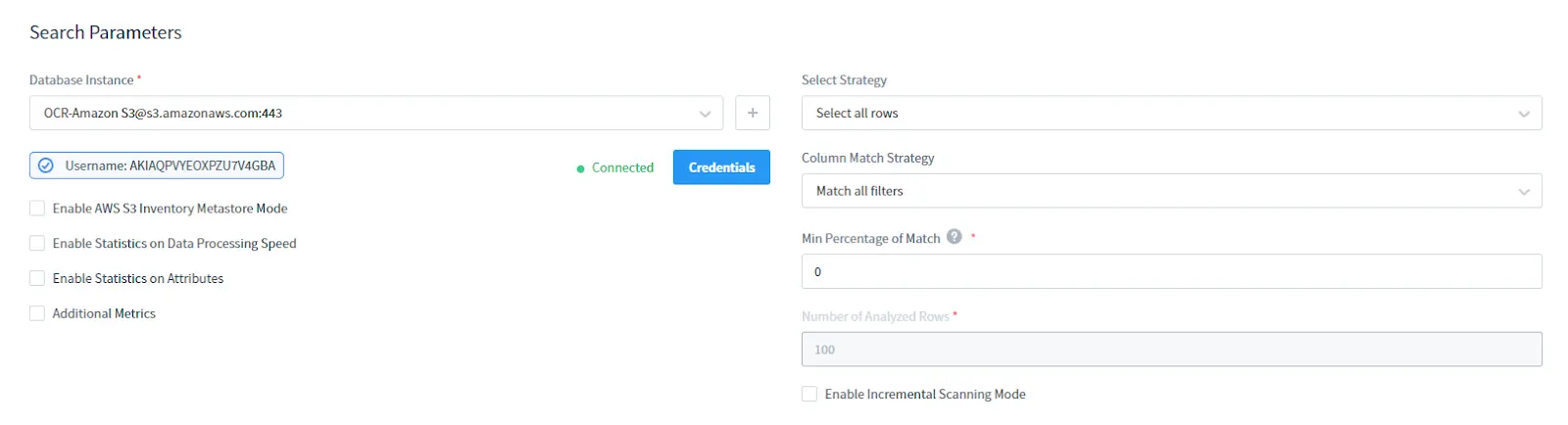
- Wählen Sie Ihre AWS S3 DB-Instanz. Geben Sie die Anmeldeinformationen für Ihr S3 an
- Wählen Sie Auswahlstrategie: Alle Zeilen auswählen oder nur obere Zeilen
- Wählen Sie Spaltenabgleichstrategie: Spaltenfilterungstyp
- Legen Sie den Mindestprozentsatz für Übereinstimmungen fest: Es ist der Mindestprozentsatz der Zeilen in einer Spalte, die den Suchfilterbedingungen entsprechen, um die Spalte als enthaltend die erforderlichen sensiblen Daten zu betrachten
- Wählen Sie die Anzahl der analysierten Zeilen: Anzahl der analysierten Zeilen, die ausgewählt werden sollen
In den Multiprozess Parameter:

Wählen Sie Ausführungsstrategie: Einzelner DS-Server oder mehrere DS-Server für parallele Berechnungen
Wählen Sie DB-Objekte aus, die durchsucht werden sollen:

Verwenden Sie den Objektbaum, um Objekte anzugeben, die während der Ausführung der Aufgabe durchsucht werden sollen.
Sie können bestimmte Objekte von der Suche ausschließen, indem Sie den entsprechenden Objektbaum verwenden:

In den Such Einstellungen:
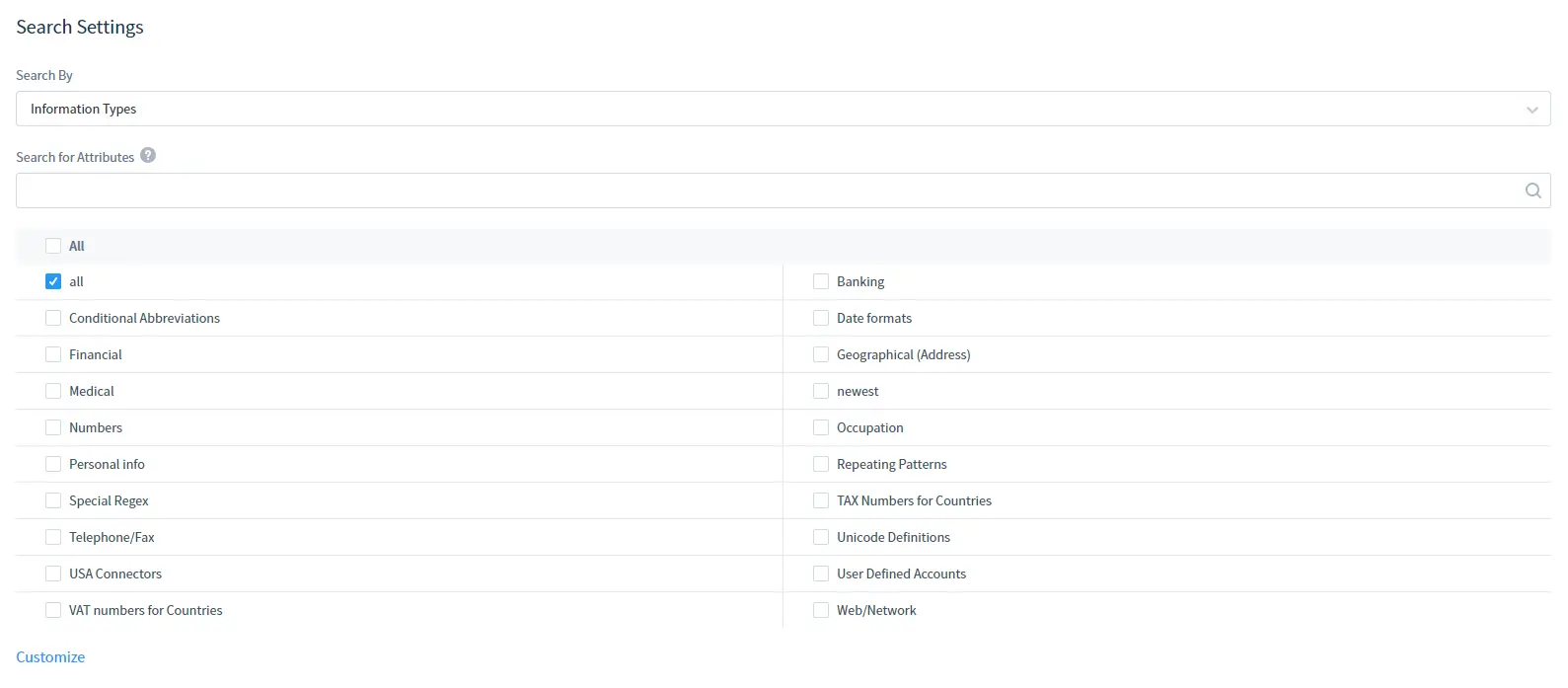
Wählen Sie den Informationstyp oder Sicherheitsstandards aus, nach denen gesucht werden soll. Beachten Sie, dass Sie auch die Attributsuche verwenden können, um einen Informationstyp oder Sicherheitsstandard anhand eines Attributs zu finden.
Unter Startfrequenz:
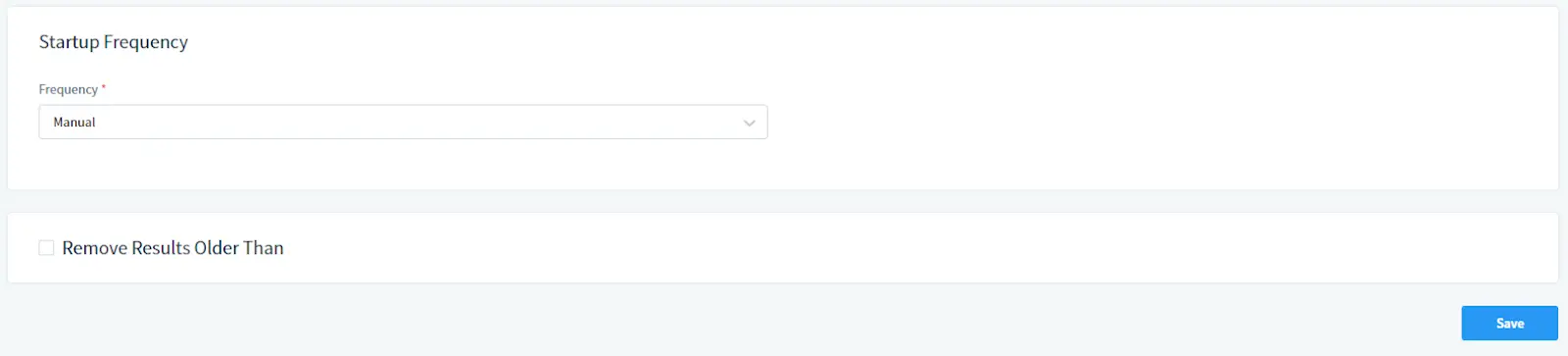
Wählen Sie die Frequenz der Aufgaben aus. Wählen Sie manuell für manuellen Beginn oder legen Sie einen Zeitplan fest.
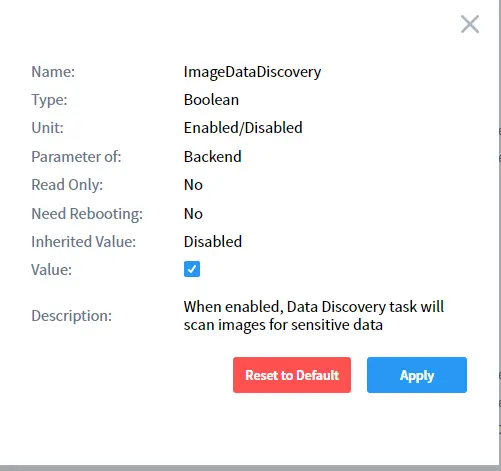
Wichtig: Sie müssen den zusätzlichen Parameter imageDataDiscovery vor dem Ausführen der Aufgabe aktivieren. Sie können dies in den Zusätzlichen Parametern (Systemeinstellungen -> Zusätzliche Parameter) oder im Abschnitt Benutzerdefinierte Zusatzeinstellungen auf der Aufgaben-Seite tun.
Wählen Sie imageDataDiscovery in der Liste aus und aktivieren Sie es, wie unten gezeigt:
Führen Sie die Aufgabe manuell oder nach Zeitplan aus und DataSunrise führt die OCR-Erkennung automatisch durch:

Beziehen Sie sich für Suchergebnisse auf die Suchergebnistabelle: