
Ausführung von DataSunrise auf Kubernetes mit dem Helm-Chart
Die Bereitstellung von Anwendungen in Kubernetes kann komplex sein und erfordert detaillierte Kenntnisse über dessen verschiedene Komponenten und deren Funktionen. Helm vereinfacht diesen Prozess und macht die Kubernetes-Bereitstellung übersichtlich und handhabbar. Anstatt manuell mehrere YAML-Manifeste für jedes Kubernetes-Objekt zu erstellen und zu pflegen, fasst Helm alles in ein einziges Paket zusammen, das einfach auf Ihren Kubernetes-Cluster bereitgestellt werden kann. Dies reduziert die Zeit und Komplexität, die beim Verwalten von Kubernetes-Anwendungen erforderlich ist, erheblich.
DataSunrise hat ein Helm-Chart erstellt, um die einfache Installation und den Betrieb von DataSunrise auf Kubernetes zu erleichtern. Helm rationalisiert das Management von Kubernetes-Anwendungen, vereinfacht und vereinheitlicht den Bereitstellungsprozess für DataSunrise. Mit Helm können Sie DataSunrise bei Bedarf einfach in jedem Ihrer Kubernetes-Umgebungen installieren und aktualisieren, einschließlich der Cloud-Anbieter AWS EKS, Azure AKS und Google Cloud GKE-Clusters. Das Chart unterstützt mehrere Anwendungsfälle basierend auf den bereitgestellten Werten.
Zu den Schlüsselfunktionen des DataSunrise Helm Charts gehören die Proxy-Funktionalität, bei der ein Proxy auf jedem Knoten verwendet wird und Kubernetes das Load Balancing zwischen ihnen verwaltet. Es unterstützt auch das automatische Skalieren, nutzt die leistungsstarke Erkennung sensibler Daten, um automatisch neue Pods zum Cluster hinzuzufügen, wenn die Lastspitzen erreicht sind. Darüber hinaus kann das Helm Chart einfach über die Artifact Hub-Anwendung installiert werden, wodurch die Bereitstellung und das Management von DataSunrise auf Kubernetes vereinfacht wird.
Voraussetzungen
Unser Helm-Chart funktioniert sowohl mit Vanilla Kubernetes als auch mit verwalteten Kubernetes-Diensten wie AWS EKS, Azure AKS und Google Cloud GKE. Für diesen Artikel verwenden wir AWS EKS, um die weiteren Schritte zu demonstrieren.
Wir benötigen die folgenden Komponenten in unserer Umgebung. Sie können auch die Befehle finden, die zur Installation der erforderlichen Komponenten im nächsten Abschnitt verwendet werden.
- Erstellen Sie einen EKS-Cluster und Pods in Ihrem AWS.
- Helm 3.6+
- Kubernetes 1.21+ – Dies ist die früheste getestete Version von Kubernetes. Es ist möglich, dass dieses Chart auch mit früheren Versionen funktioniert.
- Externe Datenbanken für Produktionslasten und HA-Modus
Warum benötigen wir externe Datenbanken im HA-Modus?
DataSunrise verwendet zwei Schlüsseltypen von Datenbanken, um seine Betriebsdaten zu speichern: die Audit-Datenbank und die Wörterbuch-Datenbank. Um eine hohe Verfügbarkeit und Skalierbarkeit zu gewährleisten, kann DataSunrise auf mehreren Servern konfiguriert werden. Bei der Bereitstellung von DataSunrise in einer Multi-Server-Konfiguration wird eine PostgreSQL-, MySQL/MariaDB- oder MS SQL Server-Datenbank verwendet, um die gemeinsamen Wörterbuch- und Audit-Daten zu speichern.
Die Audit-Datenbank in DataSunrise ist unerlässlich für die Speicherung detaillierter Logs aller überwachten Datenbankaktivitäten, einschließlich SQL-Abfragen, Benutzeraktionen und Sicherheitsereignisse. Diese Datenbank bietet eine umfassende Audit-Trail und erleichtert die Sicherheitsüberwachung durch Erkennung verdächtiger Aktivitäten. DataSunrise unterstützt PostgreSQL, MySQL, MariaDB und MS SQL Server für die Audit-Datenbank. Es ist von entscheidender Bedeutung, ausreichend Speicherplatz zu reservieren und die Aufbewahrungsrichtlinien zu verwalten, um das möglicherweise signifikante Wachstum von Audit-Daten zu bewältigen.
Die Wörterbuch-Datenbank enthält die Konfigurations- und Metadaten, die zur Bedienung von DataSunrise erforderlich sind, wie Informationen über Datenbankinstanzen, Sicherheitsregeln, Auditing-Regeln und Benutzerrollen. Sie stellt sicher, dass DataSunrise reibungslos funktionieren kann, indem sie alle erforderlichen Konfigurationsdaten speichert. Wie die Audit-Datenbank unterstützt DataSunrise PostgreSQL, MySQL, MariaDB und MS SQL Server für die Wörterbuch-Datenbank. Diese Datenbank sollte hochverfügbar sein und mit starken Passwörtern gesichert sein, da sie für den unterbrechungsfreien Betrieb von DataSunrise von entscheidender Bedeutung ist.
Weitere Informationen über die Anweisungen zur Vorbereitung der externen Datenbanken für den Einsatz als Audit- und Konfigurationsdatenbanken finden Sie im Kapitel 4 des Admin-Leitfadens: MultiServer-Konfiguration (High Availability-Modus). Durch die Verwendung externer Datenbanken für sowohl die Audit- als auch die Wörterbuch-Datenbanken kann DataSunrise eine robuste hohe Verfügbarkeit bieten, was einen kontinuierlichen Betrieb und eine konsistente Sicherheitsüberwachung in Ihrer Datenbankumgebung gewährleistet.
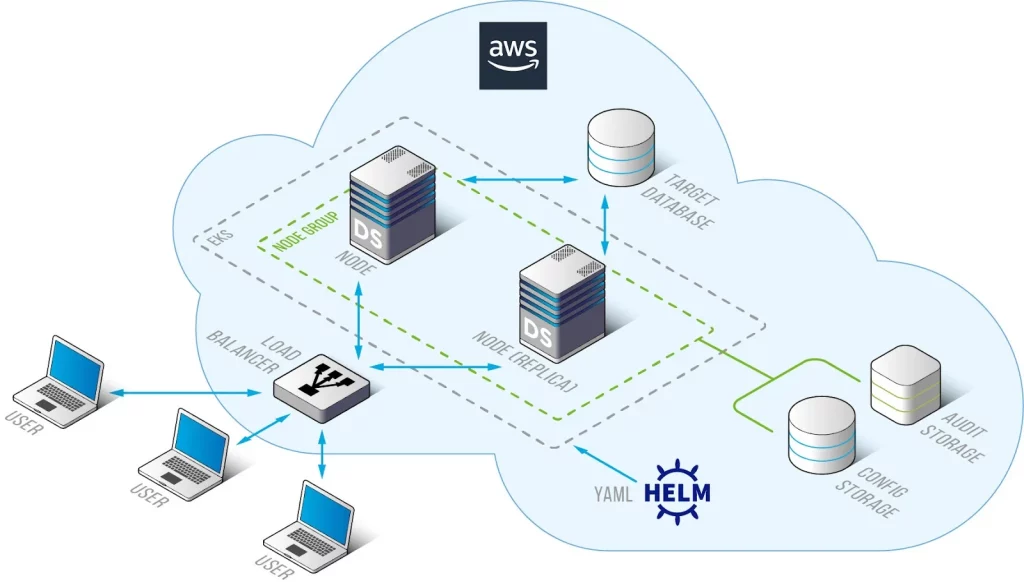
Bild 1. Bereitstellungsstruktur von DataSunrise auf K8S mit Helm-Chart
Wie man AWS EKS Cluster vorbereitet
Schritt – 1: Nachdem der EKS-Cluster und der Knoten, auf dem Sie Datasunrise installieren möchten, einsatzbereit sind, installieren Sie:
- kubectl: Interagiert direkt mit Kubernetes-Clustern, unerlässlich für Cluster- und Anwendungsmanagement.
- Helm: Verwaltet Kubernetes-Anwendungen über Charts, vereinfacht Bereitstellung und Upgrades.
- AWS CLI: Verwaltet AWS-Ressourcen, nützlich für die Automatisierung von AWS-Aufgaben und die Integration von Diensten.
#kubectl
- curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl
- chmod +x ./kubectl
- sudo mv ./kubectl /usr/local/bin/kubectl
#helm
- curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
#awscli
- curl “https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip” -o “awscliv2.zip”
- unzip awscliv2.zip
- sudo ./aws/install
Schritt – 2: Jetzt können wir Anmeldeinformationen in awscli konfigurieren:
Führen Sie diesen Befehl aus: aws configure
Nachdem Sie es ausgeführt haben, werden Sie aufgefordert, Ihre AWS-Zugriffs-ID, Ihr AWS-Geheimzugriffsschlüssel, den Namen der Standardregion und das bevorzugte Ausgabeformat einzugeben.
AWS Access Key ID [None]: ************
AWS Secret access key [None]: ************
Default Region name [None]: us-east-2
Schritt – 3: Konfigurieren Sie anschließend Ihr kubectl, um mit dem angegebenen EKS-Cluster in der angegebenen Region zu interagieren. Überprüfen Sie nach der Aktualisierung der kubeconfig die Aktualisierung durch Überprüfen des Status der Pods im kube-system-Namespace.
- aws eks update-kubeconfig –region
–name - kubectl get pods -n kube-system -l k8s-app=aws-node -o wide
Installation von Datasunrise mit HELM
Schritt – 1: Laden Sie die Helm-Chart-Werte.yaml-Datei manuell von https://artifacthub.io/packages/helm/datasunrise/datasunrise herunter oder installieren Sie das Helm-Chart mit dem Befehl:
- helm repo add datasunrise https://www.datasunrise.com/helm-chart
- helm install my-datasunrise datasunrise/datasunrise –version 1.2.14
- Öffnen und bearbeiten Sie die values.yaml-Datei. Ändern Sie die folgenden Werte:
- enVars – zur Konfiguration Ihrer Wörterbuch- und Audit-Datenbankeigenschaften.
- Ändern Sie den uiService-Typ von ClusterIp in LoadBalancer.
- Aktivieren Sie den Ingress.
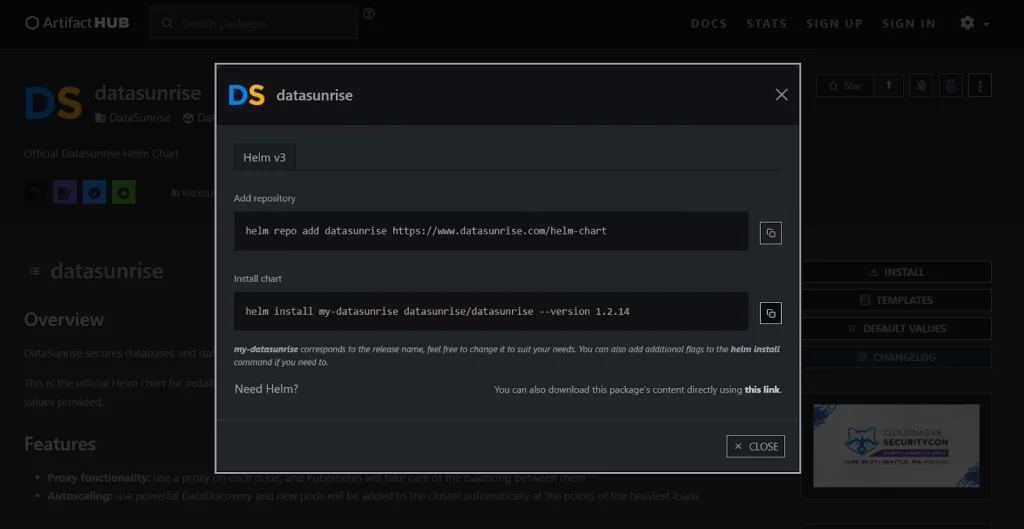
Bild 2. Datasunrise Helm Package Installation
Die Struktur des Verzeichnisses sollte wie folgt aussehen:
my-chart/
├── Chart.yaml
├── charts/
├── templates/
├── values.yaml
Es ist entscheidend, starke Passwörter in Ihrer Anwendungseinrichtung zu verwenden. Ein starkes Passwort sollte über 8-12 Zeichen lang sein und eine Kombination aus Groß- und Kleinbuchstaben, Ziffern und Sonderzeichen enthalten. Zum Beispiel: P@ssw0rd#2024! Die Demonstration der Verwendung des AWS Secret Managers wird auch im nächsten Teilkapitel beschrieben.
apiVersion: secrets-store.csi.x-k8s.io/v1alpha1
kind: SecretProviderClass
metadata:
name: aws-secrets
namespace: default #Wechseln Sie zu Ihrem bevorzugten Namespace
spec:
provider: aws
secretObjects:
- secretName: k8s-secret
type: Opaque
data:
- objectName: db_password
key: password_for_ds
parameters:
objects:
- objectName: arn:aws:secretmanager:us-east-1:xxxxxx:secret:MySecret
objectType: secretmanager
jmesPath:
- path: password_for_ds
objectAlias: db_password
envVars##
envVars: {}
# Beispiele:
# - name: DICTIONARY_TYPE
# value: "postgresql"
#
# - name: DICTIONARY_PASS
# valueFrom:
# secretKeyRef:
# name: db-secret
# key: password
- name: DICTIONARY_TYPE
value: "postgresql"
- name: DICTIONARY_HOST
value: "your_dictionary_host"
- name: DICTIONARY_PORT
value: "5432"
- name: DICTIONARY_DB_NAME
value: "dictionarydb"
- name: DICTIONARY_LOGIN
value: "postgres"
- name: DICTIONARY_PASS
valueFrom:
secretKeyRef:
name: k8s-secret
key: password_for_ds
- name: AUDIT_TYPE
value: "postgresql"
- name: AUDIT_HOST
value: "your_audit_host"
- name: AUDIT_PORT
value: "5432"
- name: AUDIT_DB_NAME
value: "auditdb"
- name: AUDIT_LOGIN
value: "postgres"
- name: AUDIT_PASS
valueFrom:
secretKeyRef:
name: k8s-secret
key: password_for_ds
uiService:
type: LoadBalancer
port: 11000
annotations: {}
ingress: enabled: true className: “”
Hinweis: Wenn Ihr Pod im Status “Pending” feststeckt, deaktivieren Sie das Volume:
localSettingsPersistentVolume: ## Wenn 'true', dann wird Persistent Volume Claim erstellt/genutzt. ## Wenn 'false', dann wird emptyDir verwendet. enabled: false
Schritt – 2: Um eine Verbindung zu Datasunrise Web-UI herzustellen, müssen wir den Ingress einrichten:
helm upgrade –install ingress-nginx ingress-nginx –repo https://kubernetes.github.io/ingress-nginx –namespace ingress-nginx –create-namespace
Dieser Befehl zieht das ingress-nginx-Chart aus dem angegebenen Repository und installiert es im Namespace ingress-nginx, indem er den Namespace erstellt, wenn er noch nicht vorhanden ist. Mit dieser Einrichtung können Sie den externen Zugriff auf Ihre DataSunrise-Dienste über Kubernetes-Ingress-Ressourcen verwalten.
Danach müssen wir den Host für Ihren Ingress festlegen. Um den Link zum Load Balancer zu finden, navigieren Sie zu Ihrem AWS EKS Cluster-Dashboard. Gehen Sie dann zu “Ressourcen” -> “Service und Netzwerk” -> “Service” -> “ingress-nginx-controller” und kopieren Sie die URL des LoadBalancers. Sobald Sie die URL haben, verwenden Sie sie zum Setzen des Host-Felds (“-host”) in Ihrer Ingress-Konfiguration.
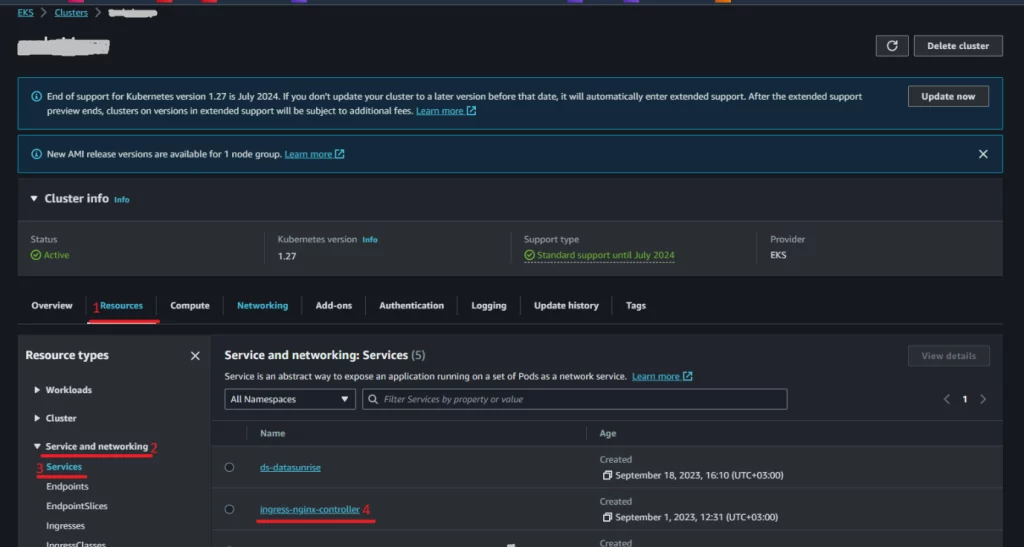
Bild 3. Wie man den Load Balancer-Link in AWS EKS (1) findet
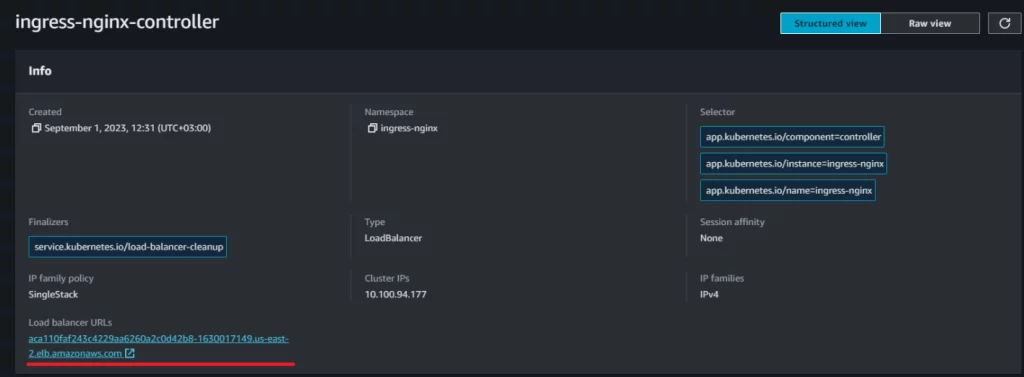
Bild 4. Wie man den Load Balancer-Link in AWS EKS (2) findet
ingress:
enabled: false
className: "nginx"
## Für den Ingress sind einige zusätzliche Annotationen erforderlich.
## Wenn Sie nginx verwenden, sind die notwendigen Annotationen bereits unten vorhanden.
## Wenn Sie einen anderen Ingress verwenden, müssen Sie ähnliche Annotationen für Ihre Klasse finden.
## Die HTTPS-Backend- und "sticky session"-Annotationen werden benötigt
annotations:
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
nginx.ingress.kubernetes.io/affinity: "cookie"
nginx.ingress.kubernetes.io/affinity-mode: "persistent"
hosts:
- host: #Setzen Sie hier Ihre LoadBalancer-URL ein
paths:
- path: /
pathType: ImplementationSpecific
Schritt – 3: Nach der Konfiguration des Hosts, können Sie DataSunrise mit Helm installieren. Stellen Sie sicher, dass Sie sich im Verzeichnis befinden, das das Helm-Chart-Skript enthält. Dann führen Sie den folgenden Befehl aus:
“helm install ds .”
Um den Status der Installation zu verfolgen, verwenden Sie den folgenden Befehl:
“kubectl get pods”
Überprüfen Sie die Protokolle des Pods, wenn der Pod nicht startet:
“kubectl logs
Schritt – 4: Nachdem der Datasunrise-Pod ausgeführt wird, sollten Sie in der Lage sein, sich mit dem vorherigen LoadBalancer-Link mit der Datasunrise Web-UI zu verbinden. Oder prüfen Sie mit diesem Befehl: kubectl get services.

Bild 5. Beispiel-Ergebnisse von ‘kubectl get services’
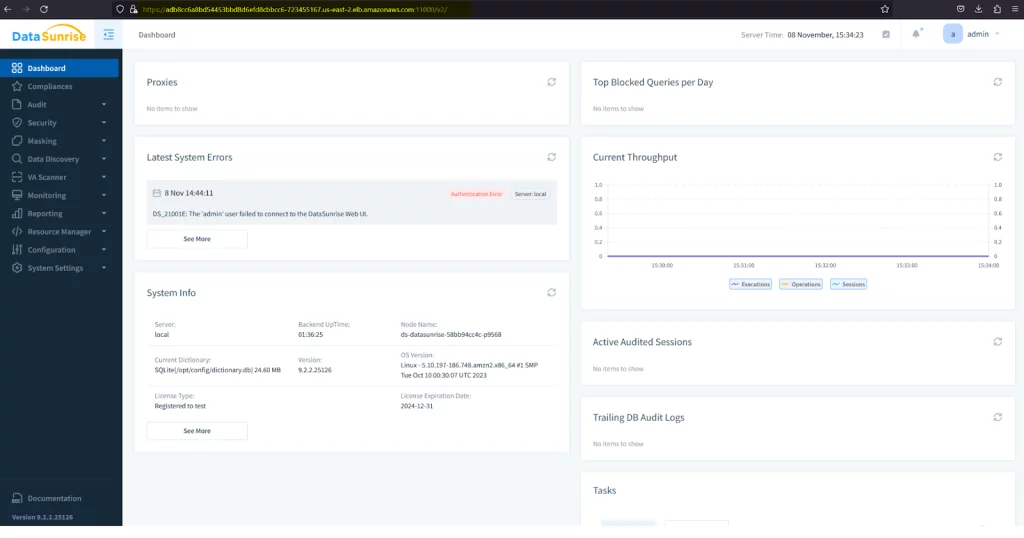
Bild 6. Verbindungsaufbau zur DataSunrise-Webkonsole
Schritt – 5: Wenn Sie DataSunrise auf eine neuere Version aktualisieren möchten, müssen Sie die im values.yaml angegebene Version auf die gewünschte Version ändern. Sobald Sie die notwendigen Änderungen vorgenommen haben, führen Sie den folgenden Befehl aus, um DataSunrise zu aktualisieren: “helm upgrade ds .”
Einrichten der Verbindung zur Ziel-Datenbank
Wenn Ihr mit Kubernetes und Docker erstellter DataSunrise-Cluster läuft, können Sie DataSunrise-Regeln konfigurieren, um Ihre sensiblen Datenbankspalten zu auditieren, zu sichern oder zu maskieren. Siehe Abschnitt “DataSunrise Use Cases” des DataSunrise-Benutzerhandbuchs.
DataSunrise interagiert mit einer Ziel-Datenbank und erhält alle für den Betrieb erforderlichen Informationen über ein Benutzerkonto dieser Datenbank (das Konto, der Benutzername und das Passwort davon werden im Profil der Ziel-Datenbank in der Webkonsole angegeben). Sie können das Administratorkonto der Datenbank zur Verbindung verwenden, es ist jedoch auch möglich, ein anderes Benutzerkonto mit ausreichenden Berechtigungen zu verwenden. Der Abschnitt des Benutzerhandbuchs: 5.2 Erstellen von Datenbankbenutzern, die erforderlich sind, um die Metadaten der Datenbank zu erhalten beschreibt die erforderlichen Schritte, um eine Verbindung zwischen DataSunrise und verschiedenen Datenbanken herzustellen. Nachdem Sie den Datenbankbenutzer zur Abrufung der Metadaten der Datenbank konfiguriert haben, können Sie die folgenden Schritte durcharbeiten, um sich mit DataSunrise über die Webkonsole zu verbinden.
- Melden Sie sich an der DataSunrise Webkonsole an.
Verwenden Sie die externe IP-Adresse, die Sie vom vorherigen Schritt erhalten haben, um auf die DataSunrise Webkonsole zuzugreifen.
- Fügen Sie die Ziel-Datenbankinstanz hinzu.
- Navigieren Sie zu Konfiguration > wählen Sie Datenbankinstanzen aus.
- Klicken Sie auf “Neue Instanz hinzufügen” und geben Sie die erforderlichen Details ein:
- Logischer Name: Ein Referenzname für die Datenbank.
- Hostname oder IP: Die Adresse der Ziel-Datenbank.
- Authentifizierungsmethode: Wählen Sie die geeignete Methode (z.B. Datenbank-Benutzername/Passwort, Active Directory).
- Datenbanktyp: Wählen Sie den Typ Ihrer Ziel-Datenbank (z.B. MS SQL, PostgreSQL).
- Port: Die Portnummer, auf der die Datenbank läuft.
- Datenbankname: Der Name der Ziel-Datenbank.
- Verbindung testen.
- Klicken Sie auf die Schaltfläche “Test”, um sicherzustellen, dass DataSunrise erfolgreich eine Verbindung zur Ziel-Datenbank herstellen kann.
- Sobald der Verbindungstest erfolgreich ist, klicken Sie auf “Speichern”, um die Datenbankinstanz zu DataSunrise hinzuzufügen.
- Sicherheits- und Prüfregeln einrichten.
Navigieren Sie im DataSunrise Web Console zum Abschnitt Regeln. Erstellen und konfigurieren Sie die Regeln für Auditing, Sicherheit und Datenmaskierung gemäß Ihren Anforderungen.
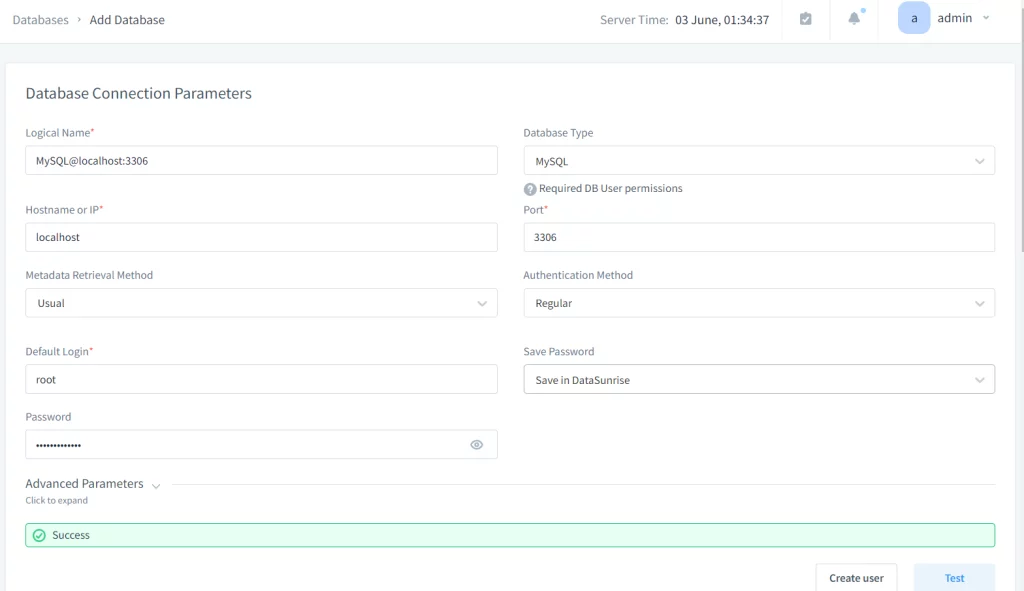
Bild 7. Prüfung der Verbindung in DataSunrise
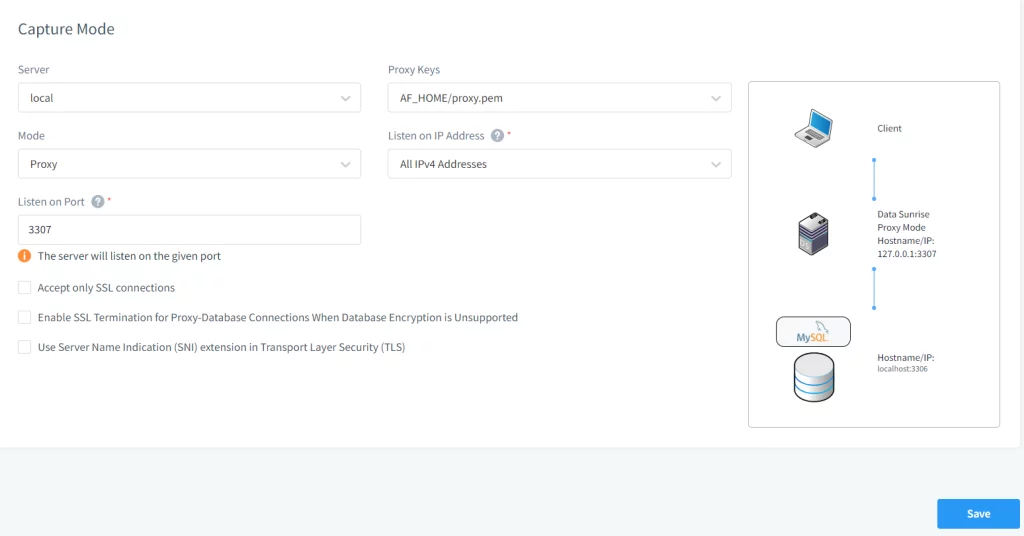
Bild 8. Einrichtung einer Proxy-Verbindung in DataSunrise
Fazit
Das von DataSunrise bereitgestellte Helm-Chart vereinfacht den Bereitstellungsprozess und bietet Schlüsselfunktionen wie Proxy-Funktionalität und automatische Skalierung, um optimale Leistung und Zuverlässigkeit zu gewährleisten. Darüber hinaus können Organisationen durch die Einhaltung von Best Practices wie die Konfiguration externer Datenbanken und die Verwendung starker Passwörter die Sicherheitslage ihrer Bereitstellungen verbessern. Mit DataSunrise, das in Kubernetes bereitgestellt wird, können Organisationen ihre sensiblen Daten sicher schützen und gleichzeitig die Skalierbarkeit und Flexibilität von containerisierten Umgebungen nutzen.
Integration von AWS Secret Manager mit AWS EKS
AWS Secrets Manager ist ein robustes Tool, das Verschlüsselung in Ruhezustand und Secret Rotation bietet und daher ideal für das sichere Management sensibler Informationen ist. Aufgrund seiner Genehmigung durch viele Sicherheitsteams ist es eine vertrauenswürdige Lösung für des Umgang mit Geheimnissen in Cloud-Umgebungen. Daher können Sie zur Verbesserung der Sicherheit in AWS-Bereitstellungen, wie bei Amazon EKS, den AWS Secrets Manager verwenden, um sicherzustellen, dass Ihre Anwendungen sicher und konform mit Best Practices bleiben.
Es gibt mehrere Möglichkeiten, den AWS Secrets Manager-Dienst in EKS-Pods zu verwenden.
Verwendung des Kubernetes Secrets Store CSI-Treibers
Während mehrere benutzerdefinierte Implementierungen Flexibilität bieten, erfordern sie auch erhebliche Entwicklungs-, Wartungs- und Betriebseinheiten. Ein standardisierter und effizienterer Ansatz besteht darin, den Kubernetes Secrets Store CSI-Treiber zu verwenden. Dieser Treiber integriert Secrets Stores mit Kubernetes über ein Container Storage Interface (CSI)-Volume, so dass Secrets von AWS Secrets Manager direkt auf dem Pod eingebunden werden können.
Der Secrets Store CSI-Treiber vereinfacht den Prozess der Secrets-Verwaltung, indem er eine native Kubernetes-Schnittstelle für das Secrets-Management bereitstellt. Er reduziert den Overhead, der mit benutzerdefinierten Lösungen verbunden ist, und sorgt für eine konsistente und sichere Methode zum Umgang mit Secrets in Ihrer Kubernetes-Umgebung.
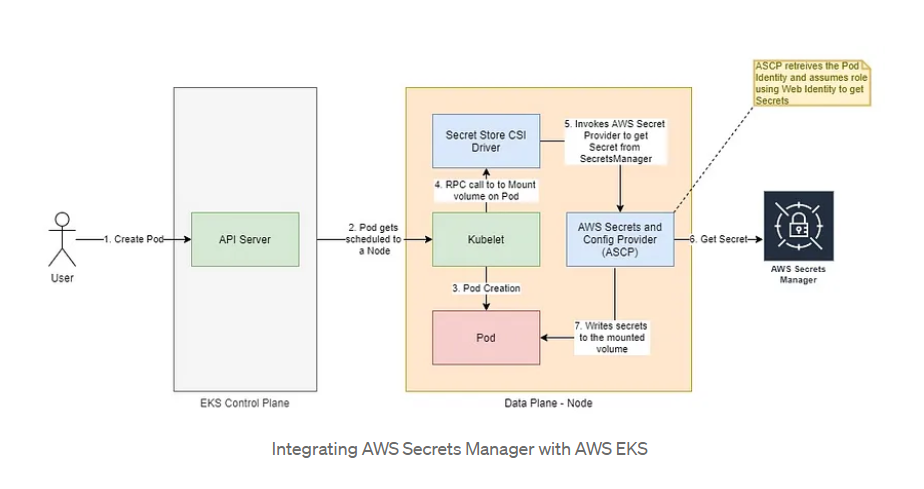
Bild 9. AWS Secrets Manager
Sie können diese Links durchgehen, um mehr über den Treiber und seine Verwendung zu erfahren. Die Anweisungen zur Installation dieser Anforderungen sind unten ebenfalls erwähnt.
Zu befolgende Schritte
- Installieren Sie den CSI Secrets Store Driver. Sie müssen sicherstellen, dass der secrets-store.csi.k8s.io CSI-Treiber in Ihrem Kubernetes-Cluster installiert ist. Dieser Treiber ermöglicht es Kubernetes, mit externen Secret-Management-Systemen zu interagieren.
- Erstellen Sie ein Secret innerhalb des AWS Secrets Managers in der gleichen Region wie Ihr Cluster mit dem AWS CLI (Command Line Interface). Sie können dies auch in der AWS Management Console tun.
- Erstellen Sie eine IAM-Richtlinie, indem Sie den untenstehenden Befehl ausführen. Nach Ausführung des Befehls enthält die Variable POLICY_ARN die ARN der erstellten IAM-Richtlinie.
- Erstellen Sie ein Dienstkonto, das mit der IAM-Richtlinie verbunden ist, die Sie zuvor mit `eksctl` erstellt haben. Bevor Sie den Befehl ausführen, stellen Sie sicher, dass Sie eksctl auf Ihrem Gerät installiert und konfiguriert haben.
- Erstellen Sie die AWS Secret Provider Class.
- Ändern Sie die values.yaml, indem Sie die Secrets verwenden, die wir in Schritt-2 erstellt haben. Sie müssen das envVarsSecretProviderClassName-Parameter mit dem Namen des SecretProviderClass angeben, den Sie in Schritt-5 erstellt haben. Nachdem Sie alle erforderlichen Felder in values.yaml geändert haben, können Sie mit der Helm-Bereitstellung fortfahren.
“helm repo add secrets-store-csi-driver https://kubernetes-sigs.github.io/secrets-store-csi-driver/charts”
“helm install csi-secrets-store secrets-store-csi-driver/secrets-store-csi-driver –namespace kube-system –set syncSecret.enabled=true”
3.1: Setzen Sie zwei Umgebungsvariablen REGION und CLUSTERNAME. Diese Variablen definieren die AWS-Region und den Namen des EKS-Clusters.
REGION=
CLUSTERNAME=
3.2: Erstellen Sie das Secret in AWS Secrets Manager. Es enthält JSON-Objekte Ihrer Zugangsdaten oder Secrets. Nach Ausführung dieses Befehls enthält die Variable SECRET_ARN die ARN (Amazon Resource Name) des erstellten Secrets.
SECRET_ARN=$(aws –query ARN –output text secretsmanager create-secret –name
POLICY_ARN=$(aws --region "$REGION" --query Policy.Arn --output text iam create-policy --policy-name--policy-document '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["secretsmanager:GetSecretValue", "secretsmanager:DescribeSecret"], "Resource": ["$SECRET_ARN"] } ] }')
eksctl create iamserviceaccount –name
Die Option –approve bestätigt die Erstellung des Dienstkontos ohne Aufforderung zur Bestätigung, und –override-existing-serviceaccounts ermöglicht es dem Befehl, bestehende Dienstkonten mit dem gleichen Namen zu überschreiben.
apiVersion: secrets-store.csi.x-k8s.io/v1alpha1 kind: SecretProviderClass metadata: name:spec: provider: aws parameters: objects: | - objectName: " " objectType: "secretsmanager" jmesPath: - path: objectAlias: - path: objectAlias:
SECRET_ARN=$(aws --query ARN --output text secretsmanager create-secret --name--secret-string '{" ":" ", " ":" "}' --region "$REIGON")
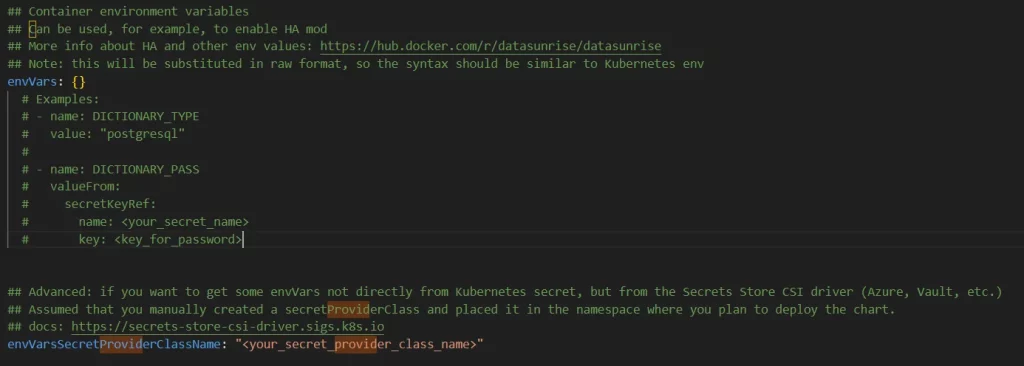
Bild 10. Parameter spezifizieren
Hinweis: Wenn Sie ein k8s-Secret mit dem yaml-Manifest erstellen, sollten Sie das Secret in base64-Codierung einbeziehen. Siehe das folgende Beispiel:
Ihr_Secret_Datei.yaml:
apiVersion: v1
kind: Secret
metadata:
name: db-secret
type: Opaque
data:
password: cGFzc3dvcmQxMjMK # password1234 in base64-Codierung
-------------------------
values.yaml:
- name: DICTIONARY_PASS
valueFrom:
secretKeyRef:
name: db-secret
key: password
Fazit
Die Verwendung starker Passwörter in Kombination mit einem Secrets Management Service wie AWS Secrets Manager verbessert die Sicherheitslage Ihrer Bereitstellungen erheblich. Indem Sie diese Schritte befolgen, können Sie Secrets aus AWS Secrets Manager sicher verwalten und in Ihre über Helm auf EKS bereitgestellten DataSunrise-Anwendungen injizieren.
