
Was ist Datenmaskierung?
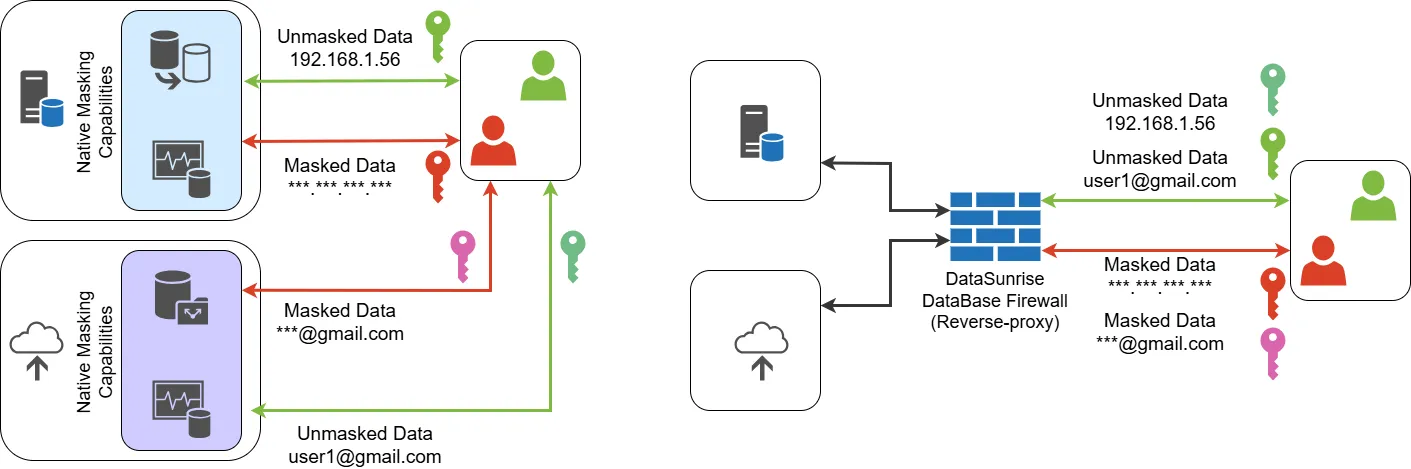
Datenmaskierung, auch bekannt als Datenverschleierung, ist der Prozess des Ersetzens sensibler Informationen durch realistische, aber unechte Daten. Ihr Hauptzweck besteht darin, vertrauliche Informationen, wie beispielsweise personenbezogene Daten, die in proprietären Datenbanken gespeichert sind, zu schützen. Effektive Maskierung erreicht jedoch ein Gleichgewicht zwischen Sicherheit und Nützlichkeit, indem sichergestellt wird, dass die verschleierten Daten weiterhin für wesentliche Unternehmensaktivitäten wie Softwaretests und Anwendungsentwicklung geeignet sind.
Warum Datenmaskierung heute unerlässlich ist
Datenmaskierung hat sich als Standardpraxis für Organisationen etabliert, die mit sensiblen oder regulierten Daten umgehen. Angesichts der zunehmenden Risiken von Datenschutzverletzungen und strengerer Compliance-Anforderungen wie GDPR, HIPAA und PCI-DSS bietet die Maskierung eine sichere Möglichkeit, Daten zu teilen, ohne reale Informationen preiszugeben.
Moderne Unternehmen verlassen sich auf Datenmaskierung, um Produktionsdatenbanken zu schützen, sicheres Testen zu ermöglichen und die Exposition in verschiedenen Umgebungen zu begrenzen. Tools wie DataSunrise rationalisieren diesen Prozess, indem anpassbare Maskierungstypen, dynamische Maskierung auf Anwendungsebene und Unterstützung für strukturierte und unstrukturierte Formate angeboten werden.
Durch die Anwendung geeigneter Maskierungstechniken reduzieren Teams das Risiko, während datengetriebene Innovationen und operative Prozesse sicher fortgeführt werden können.
Maskierung erweist sich in den folgenden Szenarien als unschätzbar wertvoll:
- Ein Unternehmen muss Zugriff auf seine Datenbank(en) gewähren an ausgelagerte und externe IT-Unternehmen. Bei der Datenmaskierung ist es sehr wichtig, dass sie konsistent aussieht und erscheint, damit Hacker und andere böswillige Akteure glauben, dass sie es mit echten Daten zu tun haben.
- Ein Unternehmen muss Betreiberfehler mindern. Unternehmen vertrauen in der Regel darauf, dass ihre Mitarbeiter gute und sichere Entscheidungen treffen, doch viele Verstöße sind das Ergebnis von Bedienfehlern. Ist die Datenmaskierung jedoch aktiv, sind die Folgen solcher Fehler nicht so katastrophal. Es ist auch erwähnenswert, dass nicht alle Operationen in Datenbanken die Verwendung vollständig realer, genauer Daten erfordern.
- Ein Unternehmen führt datengetriebene Tests durch.
In diesem Artikel schauen wir uns genauer die statische Maskierung, die dynamische Maskierung und die In-Place-Maskierung an.
Beispiele für maskierte Daten
Die Wahl des richtigen Ansatzes zur Datenmaskierung hängt von den Sicherheitsbedürfnissen und Compliance-Anforderungen einer Organisation ab. Einige Branchen erfordern strenge Kontrollen zum Schutz persönlicher und finanzieller Daten, während andere Flexibilität für Tests und Analysen priorisieren. Native Datenbank-Maskierungstools bieten grundlegenden Schutz, fehlen jedoch häufig erweiterte Funktionen wie granulare Zugriffskontrollen und formatsichernde Verschlüsselung. Drittanbieterlösungen wie DataSunrise bieten einen umfassenderen Ansatz, der sicherstellt, dass maskierte Daten in mehreren Systemen konsistent bleiben, während die Nutzbarkeit für Geschäftsanwendungen erhalten bleibt.
Im Beispiel unten sehen Sie, wie die Karten-Spalte vor der Maskierung aussah:
SQL> select * from scott.emp;
EMPNO ENAME JOB MGR HIREDATE CARD
--------- --------- ---------- ------- --------- -------------------
1 SMITH CLERK 0 17-DEC-80 4024-0071-8423-6700
2 SCOTT SALESMAN 0 20-FEB-01 4485-4392-7160-9980
3 JONES ANALYST 0 08-JUN-95 6011-0551-9875-8094
4 ADAMS MANAGER 1 23-MAY-87 5340-8760-4225-7182
4 rows selected.
Und nach der Maskierung:
SQL> select * from scott.emp;
EMPNO ENAME JOB MGR HIREDATE CARD
--------- --------- ---------- ------- --------- -------------------
1 SMITH CLERK 0 17-DEC-80 XXXX-XXXX-XXXX-6700
2 SCOTT SALESMAN 0 20-FEB-01 XXXX-XXXX-XXXX-9980
3 JONES ANALYST 0 08-JUN-95 XXXX-XXXX-XXXX-8094
4 ADAMS MANAGER 1 23-MAY-87 XXXX-XXXX-XXXX-7182
4 rows selected.
DataSunrise ermöglicht es Ihnen, verschiedene Maskierungsmethoden für jedes Feld anzuwenden. Sie können aus Voreinstellungen wählen oder benutzerdefinierte Maskierungsregeln für bestimmte Datentypen erstellen. Die formatsichernde Maskierung bewahrt die Datenstruktur, während vertrauliche Informationen geschützt werden. Auf diese Weise bleiben maskierte Daten verwendbar und bewahren ihre statistischen Eigenschaften.
| Maskierungsmethode | Originaldaten | Maskierte Daten |
|---|---|---|
| Kreditkartenmaskierung | 4111 1111 1111 1111 | 4111 **** **** 1111 |
| E-Mail-Maskierung | john.doe@example.com | j***e@e*****e.com |
| URL-Maskierung | https://www.example.com/user/profile | https://www.******.com/****/****** |
| Telefonnummernmaskierung | +1 (555) 123-4567 | +1 (***) ***-4567 |
| Zufällige IPv4-Adressmaskierung | 192.168.1.1 | 203.45.169.78 |
| Zufälliges Datum/Datum und Uhrzeit mit konstantem Jahr für Zeichenfolgenspalten | 2023-05-15 | 2023-11-28 |
| Zufälliges Datum/Datum und Uhrzeit sowie Zeit aus dem Intervall für Zeichenfolgenspalte | 2023-05-15 14:30:00 | 2024-02-19 09:45:32 |
| Maskierung durch leere, NULL- und Teilzeichenwert | Sensible Informationen | NULL |
| Maskierung durch feste und zufällige Werte | John Doe | Anonymer Nutzer 7392 |
| Maskierung mit benutzerdefinierter Funktion | Secret123! | S****t1**! |
| Maskierung der ersten und letzten Zeichen von Zeichenfolgen | Passwort | *asswor* |
| Maskierung jeglicher sensiblen Daten im Klartext | Meine SSN ist 123-45-6789 und mein Geburtsdatum ist 15.01.1980 | Meine SSN ist XXX-XX-XXXX und mein Geburtsdatum ist XX/XX/XXXX |
| Maskierung durch Werte aus vordefinierten Wörterbüchern | John Smith, Software-Ingenieur, New York | Ahmet Yılmaz, Datenanalyst, Chicago |
Schritte der Datenmaskierung
Bei der praktischen Umsetzung benötigen Sie die beste Strategie, die in Ihrer Organisation funktioniert. Nachfolgend sind die Schritte, die Sie unternehmen müssen, um eine wirksame Maskierung zu gewährleisten:
- Finden Sie Ihre sensiblen Daten. Der erste Schritt besteht darin, Daten wiederherzustellen und zu identifizieren, die möglicherweise sensibel sind und Schutz benötigen. Es ist besser, ein spezielles automatisiertes Software-Tool dafür zu verwenden, wie etwa die Erkennung sensibler Daten von DataSunrise mit Nutzung von Tabellenbeziehungen.
- Analysieren Sie die Situation. In dieser Phase sollte das Datensicherheitsteam verstehen, wo sich die sensiblen Daten befinden, wer darauf zugreifen muss und wer nicht. Sie können rollenbasierte Zugriffe verwenden. Jeder, der eine bestimmte Rolle hat, kann originale oder maskierte sensible Daten sehen.
- Wenden Sie die Maskierung an. Man sollte bedenken, dass es in sehr großen Organisationen nicht machbar ist, davon auszugehen, dass nur ein einziges Maskierungs-Tool überall verwendet werden kann. Stattdessen benötigen Sie möglicherweise verschiedene Arten der Maskierung.
- Testen Sie die Maskierungsergebnisse. Dies ist der letzte Schritt im Prozess. Qualitätssicherung und -tests sind erforderlich, um sicherzustellen, dass die Maskierungskonfigurationen die gewünschten Ergebnisse liefern.
Typen der Datenmaskierung
Für detailliertere Informationen zu den Maskierungstypen und ihrer Implementierung sowohl unter Verwendung nativer als auch von Drittanbieter-Lösungen, besuchen Sie bitte unseren YouTube-Kanal und erkunden Sie unsere umfassende Maskierungs-Playlist.
Dynamische Maskierung
Dynamische Maskierung ist ein Prozess des Maskierens von Daten zum Zeitpunkt einer Abfrage an eine Datenbank mit echten privaten Daten. Dies geschieht durch Modifizieren der Abfrage oder der Antwort. Dabei werden die Daten im Flug maskiert, ohne sie in einem Übergangsdaten-Speicher abzulegen.
Statische Maskierung
Wie der Name schon sagt, müssen beim statischen Maskieren von Daten Datenbankadministratoren eine Kopie der Originaldaten erstellen, sie sicher aufbewahren und durch ein gefälschtes Datenset ersetzen. Dieser Prozess umfasst das Duplizieren des Inhalts einer Datenbank in eine Testumgebung, die die Organisation dann mit Drittanbietern und anderen externen Parteien teilen kann. Das Ergebnis ist, dass die ursprünglichen sensiblen Daten, die geschützt werden müssen, in der Produktionsdatenbank verbleiben und eine maskierte Kopie in die Testumgebung übertragen wird. So hilfreich es auch scheint, mit Drittanbietern unter Verwendung statischer Maskierung zu arbeiten – für Anwendungen, die echte Daten aus Produktionsdatenbanken benötigen, kann statisch maskierte Daten ein großes Problem darstellen.
In-Place-Maskierung
Die In-Place-Maskierung erstellt wie die statische Maskierung Testdaten basierend auf echten Produktionsdaten. Dieser Prozess besteht in der Regel aus drei Hauptschritten:
- Kopieren der Produktionsdaten wie sie sind in eine Testdatenbank.
- Entfernen redundanter Testdaten, um das Datenvolumen zu verringern und Testprozesse zu beschleunigen.
- Ersetzen aller PII-Daten in einer Testdatenbank durch maskierte Werte – dieser Schritt wird als In-Place-Maskierung bezeichnet.
Die Art des Kopierens von Produktionsdaten bleibt außerhalb des Rahmens der eigentlichen In-Place-Datenmaskierung. Es kann sich zum Beispiel um eine ETL-Prozedur oder Backup-Wiederherstellung einer Produktionsdatenbank handeln oder etwas anderes sein. Das Wichtigste hier ist, dass die In-Place-Maskierung auf eine Kopie einer Produktionsdatenbank angewendet wird, um die darin enthaltenen PII-Daten zu maskieren.
Bedingungen, die die Datenmaskierung erfüllen sollte
Wie bereits erwähnt, müssen alle an der Maskierung beteiligten Daten auf mehreren Ebenen sinnvoll bleiben:
- Die Daten müssen für die Anwendungslogik sinnvoll und gültig bleiben.
- Die Daten müssen ausreichend verändert werden, damit sie nicht rückentwickelt werden können.
- Die verschleierten Daten sollten über mehrere Datenbanken innerhalb einer Organisation konsistent bleiben, wenn jede Datenbank das spezifische zu maskierende Datenelement enthält.
Datenmaskierung mit DataSunrise
Die Datenmaskierungsfunktion von DataSunrise stellt eine der anspruchsvollsten und gleichzeitig benutzerfreundlichsten Lösungen auf dem heutigen Markt dar. Unsere Maskierungsoberfläche exemplifiziert dieses perfekte Gleichgewicht – stellen Sie sich vor, Sie konfigurieren die Maskierung des E-Mail-Feldes mit nur wenigen Klicks. Mit Dutzenden von Maskierungstypen zur Auswahl könnte der Prozess nicht einfacher sein: Wählen Sie Ihre Datenbank, wählen Sie, was maskiert werden muss (ob es sich um strukturierte oder unstrukturierte Daten handelt), wählen Sie den bevorzugten Maskierungstyp und schon sind Sie bereit. Ihre Daten werden problemlos durch Prüfungen zur Einhaltung von Vorschriften geführt, während ein robuster Schutz gewährleistet ist.
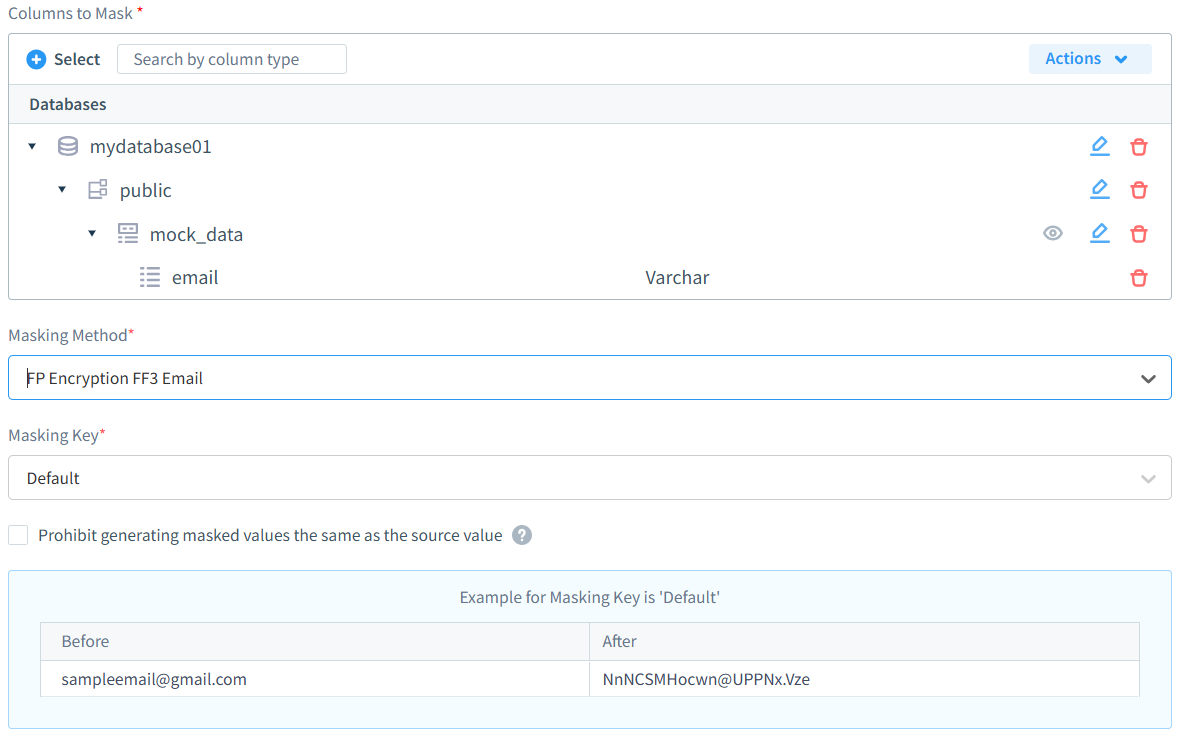
Die Lösung bietet sowohl dynamische als auch statische Maskierungsmöglichkeiten und ermöglicht es Organisationen, Daten sowohl im Ruhezustand als auch in Bewegung zu schützen. Ihre vielseitigen Maskierungsalgorithmen unterstützen verschiedene Datentypen – von einfachen Textersetzungen bis hin zu komplexen, formatsichernden Verschlüsselungen – und gewährleisten, dass sensible Informationen geschützt bleiben, während referenzielle Integrität und Datennutzbarkeit beibehalten werden. Unabhängig davon, ob Organisationen personenbezogene Informationen (PII), Finanzdaten oder Gesundheitsdaten maskieren müssen, bietet die robuste Maskierungs-Engine von DataSunrise die Flexibilität und Sicherheit, die für moderne Herausforderungen im Datenschutz erforderlich sind, und integriert sich nahtlos in bestehende Datenbankinfrastrukturen.
Fazit
DataSunrise bietet Ihnen die Möglichkeit zur statischen und dynamischen Datenmaskierung, um Ihre Daten zu schützen (auch Maskierung von XML, JSON, CSV und unstrukturiertem Text auf Amazon S3). Darüber hinaus wird die Datenerkennung mit Tabellenbeziehungen ein unverzichtbares zusätzliches Werkzeug zum Schutz Ihrer Daten sein. Unsere Sicherheitssuite garantiert den Schutz von Daten in Ihren Datenbanken sowohl in der Cloud als auch On-Premises. Probieren Sie jetzt alle unsere Funktionen aus, um sicherzustellen, dass alles unter Ihrer Kontrolle ist.
