
AI-Datengenerator

Da datengestützte Einblicke für Unternehmen aller Größen unerlässlich geworden sind, ist die Nachfrage nach hochwertigen, vielfältigen Datensätzen in die Höhe geschnellt. Allerdings kann die Beschaffung von Daten aus der realen Welt eine Herausforderung sein, viel Zeit in Anspruch nehmen und oft Datenschutzbedenken aufwerfen. Hier kommt der AI-Datengenerator ins Spiel und bietet eine leistungsstarke Lösung durch die Erzeugung von synthetischen Daten. Tauchen wir ein in diese faszinierende Welt und erkunden, wie die KI die Landschaft der Datenerzeugung verändert.
Da DataSunrise diese Funktion mit umfangreichen und benutzerfreundlichen Werkzeugen zur Erzeugung synthetischer Daten selbst implementiert, werden wir uns intensiver mit diesem Thema befassen und speziell die heutzutage verfügbaren quelloffenen Werkzeuge erkunden.
Verständnis Synthetischer Daten
Synthetische Daten sind künstlich erzeugte Informationen, die die Merkmale und statistischen Eigenschaften realer Daten nachahmen. Sie werden mit verschiedenen Algorithmen und KI-Methoden erzeugt, ohne jedoch tatsächliche Datenpunkte direkt zu kopieren. Dieser Ansatz bietet zahlreiche Vorteile, insbesondere in Szenarien, in denen echte Daten rar, sensibel oder schwer zu beschaffen sind.
Der Bedarf an Synthetischen Daten
Überwindung von Datenknappheit
Einer der Hauptgründe für die Verwendung synthetischer Daten besteht darin, die Knappheit realer Daten zu überwinden. In vielen Bereichen, insbesondere bei aufkommenden Technologien, kann die Beschaffung ausreichender Daten zur Schulung von maschinellen Lernalgorithmen eine Herausforderung sein. AI-Datengeneratoren können große Mengen vielfältiger Daten erzeugen und helfen so, diese Lücke zu schliessen.
Schutz von Privatsphäre und Sicherheit
Angesichts wachsender Bedenken hinsichtlich Datenschutz und Sicherheit bietet synthetische Daten eine sichere Alternative. Sie ermöglichen es Organisationen, mit Daten zu arbeiten, die echte Informationen eng nachbilden, ohne dabei das Risiko einer Preisgabe sensibler personenbezogener oder geschäftlicher Daten einzugehen. Dies ist insbesondere in Branchen wie Gesundheitswesen und Finanzen von grundlegender Bedeutung, in denen der Datenschutz von höchster Priorität ist.
Verbesserung der Modellschulung
Synthetische Daten können genutzt werden, um bestehende Datensätze zu erweitern und so die Leistung und Robustheit von maschinellen Lernmodellen zu verbessern. Durch die Generation zusätzlicher verschiedenartiger Beispiele können KI-Modelle lernen, mit einer breiteren Palette von Szenarien umzugehen, was zu einer besseren Verallgemeinerung führt.
Arten von Synthetischen Daten
KI-Datengeneratoren können verschiedene Arten von synthetischen Daten erzeugen:
1. Numerische Daten
Dies beinhaltet kontinuierliche Werte wie Messungen, Finanzzahlen oder Sensordaten. KI-Generatoren können numerische Daten mit spezifischen statistischen Eigenschaften erzeugen, wie:
- Wahrscheinlichkeitsdichteverteilung
- Mittelwert
- Varianz
- Korrelation zwischen Variablen
2. Kategoriale Daten
Kategoriale Daten stellen diskrete Kategorien oder Labels dar. KI-Generatoren können synthetische kategoriale Daten erzeugen, während sie die Verteilung und Beziehungen beibehalten, die in realen Datensätzen gefunden wurden.
3. Textdaten
Von einfachen Ausdrücken bis zu komplexen Dokumenten kann die KI synthetische Textdaten generieren. Dies ist besonders nützlich für Aufgaben der Verarbeitung natürlicher Sprache und der Erzeugung von Inhalten.
4. Bilddaten
Von KI generierte Bilder werden immer ausgefeilter. Diese können von einfachen geometrischen Formen bis hin zu fotorealistischen Bildern reichen, die für Anwendungen im Bereich der Computer Vision nützlich sind.
Mechanismen zur Erzeugung Synthetischer Daten
Bei der KI-Datenerzeugung kommen verschiedene Ansätze und Techniken zum Einsatz:
Statistische Modellierung
Dieser Ansatz beinhaltet die Erstellung mathematischer Modelle, die die statistischen Eigenschaften realer Daten erfassen. Die synthetischen Daten werden dann so generiert, dass sie diesen Eigenschaften entsprechen.
Datenerzeugung basierend auf Maschinellem Lernen
Fortgeschrittene Techniken des maschinellen Lernens, insbesondere generative Modelle, werden verwendet, um hochrealistische synthetische Daten zu erzeugen. Einige bekannte Methoden sind:
- Generative Adversarial Networks (GANs): Dabei handelt es sich um zwei neuronale Netzwerke, die gegeneinander antreten, wobei eines synthetische Daten erzeugt und das andere versucht, diese von echten Daten zu unterscheiden.
- Variational Autoencoders (VAEs): Diese Modelle lernen, Daten in eine komprimierte Darstellung zu kodieren und dann zu dekodieren, wobei in diesem Prozess neue Datensätze generiert werden.
- Transformer-Modelle: Insbesondere für die Textgenerierung sind diese Modelle sehr effektiv und haben Aufgaben der Verarbeitung natürlicher Sprache revolutioniert.
Regelbasierte Generierung
Diese Methode beinhaltet die Erstellung synthetischer Daten auf Basis vordefinierter Regeln und Einschränkungen. Sie wird oft verwendet, wenn die Daten spezifischen Mustern oder Geschäftslogiken folgen müssen.
KI-basierte Tools in der Testdatenerzeugung
KI spielt eine entscheidende Rolle bei der Erzeugung von Testdaten für Softwareentwicklung und Qualitätssicherung. Diese Tools können realistische, vielfältige Datensätze erstellen, die verschiedene Test-Szenarien abdecken und helfen, potenzielle Probleme und Randfälle aufzudecken.
Zum Beispiel könnte ein KI-basierter Testdatengenerator für eine E-Commerce-Anwendung erzeugen:
- Benutzerprofile mit verschiedenen demographischen Daten
- Produktkataloge mit unterschiedlichen Attributen
- Bestellhistorien mit verschiedenen Mustern
Diese synthetischen Testdaten können Entwicklern und QA-Teams helfen, die Robustheit und Zuverlässigkeit ihrer Anwendungen zu gewährleisten, ohne echte Kundendaten zu verwenden.
Generative KI in der Datenerzeugung
Die generative KI repräsentiert die Spitze der synthetischen Datenerzeugung. Diese Modelle können hochrealistische und vielfältige Datensätze in verschiedenen Domänen erzeugen. Einige Schlüsselanwendungen sind:
- Bildderstellung für die Schulung im Bereich Computer Vision
- Textgenerierung für die Verarbeitung natürlicher Sprache
- Sprach- und Sprachsynthese für Audioanwendungen
- Zeitreihendatengenerierung für prädiktive Modellierung
Zum Beispiel könnte ein generatives KI-Modell, das auf medizinischen Bildern trainiert wurde, synthetische Röntgen- oder MRT-Bilder erzeugen. Dies könnte Forschern dabei helfen, neue diagnostische Algorithmen zu entwickeln, ohne dabei die Patientenprivatsphäre zu beeinträchtigen.
Tools und Bibliotheken für die Erzeugung Synthetischer Daten
Es sind mehrere Tools und Bibliotheken verfügbar, die zur Erzeugung synthetischer Daten genutzt werden können. Eine beliebte Option ist die Python Faker-Bibliothek. Im Unterschied zu komplexeren Tools stützt sie sich nicht auf maschinelles Lernen oder KI-bezogene Techniken. Stattdessen nutzt Faker robuste, klassische Ansätze zur Datengenerierung.
Python Faker-Bibliothek
Faker ist ein Python-Paket, das gefälschte Daten für verschiedene Zwecke erzeugt. Es ist besonders nützlich für das Erstellen realistisch aussehender Testdaten.
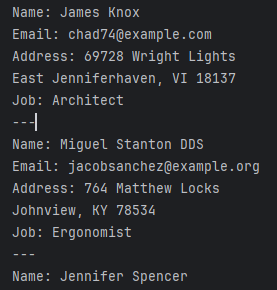
Hier ist ein einfaches Beispiel für die Verwendung von Faker zur Erzeugung synthetischer Benutzerdaten:
from faker import Faker
fake = Faker()
# Generate 5 fake user profiles
for _ in range(5):
print(f"Name: {fake.name()}")
print(f"Email: {fake.email()}")
print(f"Address: {fake.address()}")
print(f"Job: {fake.job()}")
print("---")Dieses Skript könnte eine Ausgabe wie folgt produzieren:
CTGAN-Bibliothek
CTGAN ist eine Python-Bibliothek, die speziell entwickelt wurde, um synthetische tabellarische Daten mit generativen adversen Netzwerken (GANs) zu erzeugen. Sie ist Teil des Synthetic Data Vault (SDV) Projekts und eignet sich gut für die Erzeugung synthetischer Versionen strukturierter Datensätze. CTGAN funktioniert eher wie ein KI-Datengenerator im Vergleich zu Faker.
Hier ist, wie Sie CTGAN in Python verwenden können:
Hier ist ein grundlegendes Beispiel dafür, wie man CTGAN verwendet (aktuell empfiehlt das Readme die Installation der SDV-Bibliothek, die benutzerfreundliche APIs für den Zugriff auf CTGAN bietet):
import pandas as pd
from ctgan import CTGAN
import numpy as np
# Create a sample dataset
data = pd.DataFrame({
'age': np.random.randint(18, 90, 1000),
'income': np.random.randint(20000, 200000, 1000),
'education': np.random.choice(['High School', 'Bachelor', 'Master', 'PhD'], 1000),
'employed': np.random.choice(['Yes', 'No'], 1000)
})
print("Original Data Sample:")
print(data.head())
print("\nOriginal Data Info:")
print(data.describe())
# Initialize and fit the CTGAN model
ctgan = CTGAN(epochs=10) # Using fewer epochs for this example
ctgan.fit(data, discrete_columns=['education', 'employed'])
# Generate synthetic samples
synthetic_data = ctgan.sample(1000)
print("\nSynthetic Data Sample:")
print(synthetic_data.head())
print("\nSynthetic Data Info:")
print(synthetic_data.describe())
# Compare distributions
print("\nOriginal vs Synthetic Data Distributions:")
for column in data.columns:
if data[column].dtype == 'object':
print(f"\n{column} distribution:")
print("Original:")
print(data[column].value_counts(normalize=True))
print("Synthetic:")
print(synthetic_data[column].value_counts(normalize=True))
else:
print(f"\n{column} mean and std: ")
print(f"Original: mean = {data[column].mean():.2f}, std = {data[column].std():.2f}")
print(f"Synthetic: mean = {synthetic_data[column].mean():.2f}, std = {synthetic_data[column].std():.2f}")Der Code erzeugt eine Ausgabe wie diese (beachten Sie den Unterschied in den statistischen Parametern):
Original Data Sample: age income education employed 0 57 25950 Master No 1 78 45752 High School No … Original Data Info: age income count 1000.00000 1000.000000 mean 53.75300 109588.821000 std 21.27013 50957.809301 min 18.00000 20187.000000 25% 35.00000 66175.250000 50% 54.00000 111031.000000 75% 73.00000 152251.500000 max 89.00000 199836.000000 Synthetic Data Sample: age income education employed 0 94 78302 Bachelor Yes 1 31 174108 Bachelor No … Synthetic Data Info: age income count 1000.000000 1000.000000 mean 70.618000 117945.021000 std 18.906018 55754.598894 min 15.000000 -5471.000000 25% 57.000000 73448.000000 50% 74.000000 112547.500000 75% 86.000000 163881.250000 max 102.000000 241895.000000
In diesem Beispiel:
- Importieren wir die notwendigen Bibliotheken.
- Laden wir Ihre echten Daten in ein Pandas DataFrame.
- Initialisieren wir das CTGAN-Modell.
- Passen wir das Modell an Ihre Daten an und geben dabei an, welche Spalten diskret sind.
- Generieren wir synthetische Proben mit dem trainierten Modell.
CTGAN ist besonders nützlich, wenn Sie synthetische Daten generieren müssen, die komplexe Beziehungen und Verteilungen beibehalten, die in Ihrem ursprünglichen Datensatz vorhanden sind. Es ist fortschrittlicher als einfache Zufallsprobenahmeverfahren wie diejenigen, die in Faker verwendet werden.
Einige wichtige Merkmale von CTGAN sind:
- Umgang mit sowohl numerischen als auch kategorialen Spalten
- Erhaltung der Korrelationen zwischen den Spalten
- Umgang mit multimodalen Verteilungen
- Bedingte Abtastung auf der Grundlage spezifischer Spaltenwerte
Weitere Bemerkenswerte Tools
- SDV (Synthetic Data Vault): Eine Python-Bibliothek zur Generierung von synthetischen Daten in Bezug auf mehrere Tabellen.
- Gretel.ai: Eine Plattform, die verschiedene Techniken zur Erzeugung synthetischer Daten anbietet, einschließlich differential privacy.

Bild-Datenerzeugung
Während es richtig ist, dass Faker, SDV und CTGAN die Erzeugung von Bild- und Sprachdaten nicht nativ unterstützen, gibt es tatsächlich quelloffene Werkzeuge für diese Zwecke. Diese Werkzeuge repräsentieren die derzeit nahesten Technologien zur KI in diesem Bereich und können derzeit als vollwertige KI-Datengeneratoren fungieren. Sie sind jedoch in der Regel spezialisierter und erfordern oft mehr Einrichtung und Fachwissen für eine effektive Nutzung. Hier ist ein kurzer Überblick:
Für die Bildgenerierung:
- StyleGAN: Eine fortschrittliche GAN-Architektur, besonders gut für hochwertige Gesichtsbilder.
- DALL-E mini (nun Craiyon genannt): Eine von OpenAI’s DALL-E inspirierte Open-Source-Version für die Erzeugung von Bildern aus Textbeschreibungen.
- Stable Diffusion: Ein jüngster Durchbruch in der Text-zu-Bild-Generierung, mit verfügbaren Open-Source-Implementierungen.
Für die Sprachdatengenerierung:
- TTS (Text-to-Speech) Bibliotheken wie Mozilla TTS oder Coqui TTS: Diese können synthetische Sprachdaten aus Texteingaben generieren.
- WaveNet: Ursprünglich von DeepMind entwickelt, hat es jetzt Open-Source-Implementierungen für die Erzeugung realistischer Sprache.
- Tacotron 2: Ein weiteres beliebtes Modell zur Erzeugung menschenähnlicher Sprache, mit verfügbaren Open-Source-Versionen.
Diese Tools sind in dem Sinne “einsatzbereit”, dass sie frei verfügbar sind, aber sie erfordern oft:
- Mehr technische Einrichtung (z.B. GPU-Ressourcen, spezifische Abhängigkeiten)
- Verständnis von Deep-Learning-Konzepten
- Möglicherweise, Feinabstimmung auf domänenspezifische Daten
Dies steht im Gegensatz zu Tools wie Faker, die bei einfacheren Datentypen eher Plug-and-Play sind. Die Komplexität von Bild- und Sprachdaten verlangt ausgefeiltere Modelle, die wiederum mehr Expertise für eine effektive Implementierung erfordern.
Best Practices für die Verwendung von KI-Datengeneratoren
- Validierung der synthetischen Daten: Stellen Sie sicher, dass sie die statistischen Eigenschaften und Beziehungen der ursprünglichen Daten beibehalten.
- Verwendung von Fachkenntnissen: Integrieren Sie Fachwissen, um realistische und aussagekräftige synthetische Daten zu generieren.
- Kombination mit echten Daten: Verwenden Sie, wenn möglich, synthetische Daten, um echte Datensätze zu ergänzen, anstatt sie vollständig zu ersetzen.
- Betrachtung der Datenschutzimplikationen: Seien Sie auch bei synthetischen Daten vorsichtig hinsichtlich potenzieller Datenschutzlecks, insbesondere in sensiblen Bereichen.
- Regelmäßige Aktualisierung der Modelle: Aktualisieren Sie Ihre generativen Modelle, wenn sich die realen Daten ändern, um sicherzustellen, dass die synthetischen Daten relevant bleiben.
Die Zukunft der KI-Datenerzeugung
Da sich die KI-Technologie weiterentwickelt, können wir in Zukunft noch ausgefeiltere und vielseitigere Datengenerierungsfähigkeiten erwarten. Einige aufkommende Trends sind:
- Verbesserte Realitätstreue in generierten Daten in allen Bereichen
- Verbesserte Techniken zum Schutz der Privatsphäre, die in den Generierungsprozess integriert sind
- Zugänglichere Tools für nicht-technische Benutzer zur Erstellung von benutzerdefinierten synthetischen Datensätzen
- Zunehmender Einsatz von synthetischen Daten in regulatorischen Compliance- und Test-Szenarien
Schlussfolgerung
Der KI-Datengenerator revolutioniert die Art und Weise, wie wir Daten erstellen und damit arbeiten. Von der Überwindung von Datenknappheit bis zur Verbesserung der Privatsphäre und Sicherheit bieten synthetische Daten zahlreiche Vorteile in verschiedenen Branchen. Mit der ständigen Weiterentwicklung der Technologie wird sie eine immer entscheidendere Rolle bei der Förderung von Innovationen, der Verbesserung von maschinellen Lernalgorithmen und der Ermöglichung neuer Möglichkeiten bei datengestützten Entscheidungen spielen.
Durch die Nutzung von Tools wie der Python Faker-Bibliothek und fortschrittlicheren KI-basierten Generatoren können Organisationen vielfältige, realistische Datensätze erstellen, die auf ihre spezifischen Bedürfnisse zugeschnitten sind. Es ist jedoch entscheidend, die Erzeugung von synthetischen Daten mit Sorgfalt anzugehen und sicherzustellen, dass die erzeugten Daten die erforderliche Integrität und Relevanz für ihren beabsichtigten Einsatz beibehalten.
Wenn wir in die Zukunft blicken, ist das Potenzial von KI-Datengeneratoren grenzenlos und verspricht, neue Grenzen in Data Science, maschinellem Lernen und darüber hinaus zu eröffnen.
Für diejenigen, die benutzerfreundliche und flexible Tools für die Datenbanksicherheit erkunden möchten, einschließlich synthetischer Datenfunktionen, empfehlen wir, DataSunrise zu berücksichtigen. Unsere umfassende Palette von Lösungen bietet robusten Schutz und innovative Funktionen für moderne Datenumgebungen. Besuchen Sie unsere Website für eine Online-Demonstration und entdecken Sie, wie unsere Tools Ihre Daten-Sicherheitsstrategie verbessern können.
Nächste
