
Arten der Datenmaskierung: Wie man sensible Daten schützt

Der Schutz sensibler Daten ist für jedes Unternehmen von äußerster Wichtigkeit. Datenmaskierung erweist sich als entscheidende Technik, um die Privatsphäre und Sicherheit von Daten zu gewährleisten. Dieser Artikel beleuchtet die verschiedenen Arten der Datenmaskierung, erklärt deren Anwendungen und Unterschiede. Durch das Verständnis dieser Methoden können Unternehmen ihre kritischen Informationen besser vor unbefugtem Zugriff schützen.
Datenmaskierung ist die Erstellung einer gefälschten Version der Daten eines Unternehmens, um wichtige Informationen sicher zu halten. Diese Technik ist entscheidend für die Einhaltung von Datenschutzgesetzen und den Schutz von Daten in Test- und Analyseumgebungen.
Arten der Datenmaskierung
Statische Datenmaskierung (SDM)
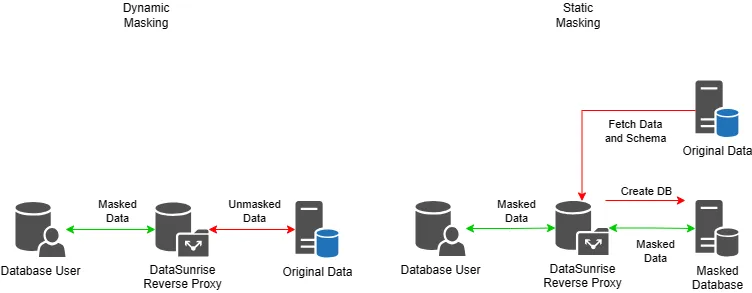
Die statische Datenmaskierung besteht darin, eine Kopie der Daten zu erstellen und Transformationstechniken anzuwenden, um sensible Informationen zu maskieren. Diese Kopie ersetzt dann die Originaldaten in Nicht-Produktionsumgebungen. Die Daten bleiben sicher, selbst wenn die Umgebung kompromittiert wird, da sie vor dem Verlassen der Datenbank transformiert werden.
Beispiel für statische Datenmaskierung: Stellen Sie sich eine Datenbank im Gesundheitswesen mit Patientendaten vor. Bevor diese Daten für Softwaretests verwendet werden, ersetzt ein statischer Datenmaskierungsprozess alle Patientennamen und IDs durch fiktive, aber realistische Einträge. Die Datenstruktur und das Format bleiben unverändert, sodass Anwendungen normal funktionieren können, ohne tatsächliche Patientendaten preiszugeben.
Dynamische Datenmaskierung (DDM)
Das System wendet die dynamische Datenmaskierung in Echtzeit an, wenn es Datenanfragen verarbeitet. Im Gegensatz zur SDM wird keine physische Kopie der Daten erstellt. Bei der Abfrage der Daten wendet das System Datenmaskierungsregeln an, um sicherzustellen, dass die Originaldaten in der Datenbank unverändert bleiben.
Beispiel für dynamische Datenmaskierung: Ein Finanzanalyst fragt eine Datenbank mit Finanzinformationen von Kunden ab. DDM verbirgt automatisch Kontonummern und Kontostände in den Abfrageergebnissen. Dies stellt sicher, dass Analysten nur die Informationen sehen, die sie für ihre Analyse benötigen. Gleichzeitig wird verhindert, dass sensible Daten offengelegt werden.
Vor-Ort-Datenmaskierung
Obwohl dies keine eigenständige Maskierungsmethode ist, ist die Vor-Ort-Maskierung als Ausnahmefall der statischen Maskierung erwähnenswert. Die Vor-Ort-Maskierung tritt auf, wenn die Quellproduktionsdatenbank und die maskierte Zieldatenbank identisch sind. Das bedeutet, dass sensible Teile der bestehenden Daten absichtlich entfernt oder maskiert werden. Dies birgt Risiken und sollte nur dann versucht werden, wenn der Datenbankadministrator vom Endergebnis überzeugt ist.
Wann findet die Maskierung statt?
- Statische Datenmaskierung maskiert die Daten, bevor sie in eine Nicht-Produktionsumgebung verschoben werden.
- Dynamische Datenmaskierung erfolgt während des Datenabrufs in Echtzeit.
Art der Datenänderungen bei der Maskierung
Datenmaskierung kann je nach verwendeter Methode reversibel oder irreversibel sein:
- Reversible Maskierung: Dies wird häufig verwendet, wenn es notwendig ist, unter sicheren Bedingungen zu den Originaldaten zurückzukehren.
- Irreversible Maskierung: Diese Methode wird verwendet, wenn kein Bedarf besteht, erneut auf die Originaldaten zuzugreifen, was die Sicherheit erhöht.
Beachten Sie, dass spezialisierte Software wie DataSunrise die gespeicherten Daten bei der dynamischen Datenmaskierung nicht ändert. Diese Art der Maskierung funktioniert im Reverse-Proxy-Modus. Anstelle der tatsächlichen Datenbank werden die Abfragen an die Datenbank vom DataSunrise-Proxy bearbeitet. Die Endbenutzer-Software arbeitet wie gewohnt mit der Datenbankverbindung.
Bei der statischen Maskierung kopiert DataSunrise standardmäßig Daten in eine andere Datenbank. Dies minimiert das Risiko eines Datenverlusts.
Maskierungsmethoden
Dies sind keine Maskierungstypen, aber in manchen Situationen sollte man auf die Maskierungsmethoden achten. Gefälschte Daten müssen das Format nachahmen, nicht nur um den Angreifer zu täuschen. Dies ist auch eine Möglichkeit, alte Software zu unterstützen, die empfindlich auf das Datenformat reagiert.
Substitution
Die Substitution besteht darin, die Originaldaten durch fiktive, aber realistische Werte zu ersetzen. Sie müssen fiktive Daten im Voraus erstellen. Diese Technik bewahrt das Format und die Struktur der Daten und stellt sicher, dass die maskierten Werte nicht reversibel sind. Beispiel:
Originaldaten: John Doe Maskierte Daten: James Smith
Shuffling
Shuffling ordnet die Werte innerhalb einer Spalte neu an und trennt die Beziehung zwischen den maskierten Daten und den Originaldaten. Diese Technik ist nützlich, wenn Sie die Verteilung und Einzigartigkeit der Daten beibehalten müssen. Beispiel:
Originaldaten: John Doe, Jane Smith, Alice Johnson Maskierte Daten: Alice Johnson, John Doe, Jane Smith
Verschlüsselung
Verschlüsselung besteht darin, die Originaldaten mit einem kryptografischen Algorithmus und einem geheimen Schlüssel in ein unlesbares Format zu konvertieren. Sie können die maskierten Daten nur mit dem entsprechenden Schlüssel entschlüsseln, wodurch die Daten reversibel sind. Verschlüsselung wird häufig verwendet, wenn die Möglichkeit besteht, die Originaldaten wiederherstellen zu müssen. Beispiel:
Originaldaten: John Doe Maskierte Daten: Xk9fTm1pR2w=
Tokenisierung
Tokenisierung ersetzt sensible Daten durch ein eindeutiges, zufällig generiertes Token. Das System speichert die Originaldaten sicher in einem Token-Tresor. Das Token dient als Referenz, um die Daten bei Bedarf abzurufen.
Unternehmen verwenden Tokenisierung häufig, um Kreditkartennummern und andere sensible Finanzdaten zu schützen. Beispiel:
Originaldaten: 1234-5678-9012-3456 Maskierte Daten: TOKEN1234
Im untenstehenden Bild sehen Sie die Auswahl der Maskierungsmethoden in DataSunrise. Dies erscheint, wenn Sie eine dynamische Maskierungsregel mit der web-basierten Benutzeroberfläche von DataSunrise erstellen. Die verfügbaren Maskierungsmethoden reichen von trivialem ‘Leerzeichen’ bis hin zu fortgeschrittener formatkonformer ‘FF3-Verschlüsselung’.
Maskierung mit nativen DBMS-Tools: Vor- und Nachteile
Datenbanksysteme (DBMS) bieten oft native Tools wie Views und gespeicherte Prozeduren. Sie können diese verwenden, um eine Datenmaskierung zu implementieren. Diese Tools bieten zwar einige Vorteile, haben jedoch auch Einschränkungen im Vergleich zu spezialisierten Datenmaskierungslösungen. Lassen Sie uns die Vor- und Nachteile der Verwendung nativer DBMS-Tools für die Erstellung von Masken untersuchen.
Vorteile
Vertrautheit: Datenbankadministratoren (DBAs) und Entwickler sind in der Regel gut mit der Verwendung nativer DBMS-Tools vertraut. Diese Vertrautheit kann es ihnen erleichtern, Maskierungen mit diesen Tools zu implementieren, ohne dass zusätzliche Schulungen erforderlich sind.
Integration: Das Datenbanksystem integriert DBMS-Tools nativ. Dies ermöglicht eine nahtlose Interaktion mit den Daten. Diese Integration kann den Implementierungsprozess vereinfachen und die Kompatibilität mit bestehenden Datenbankoperationen sicherstellen.
Leistung: Sie können Views und gespeicherte Prozeduren direkt innerhalb der Datenbank-Engine ausführen. Dies bietet eine bessere Leistung im Vergleich zu externen Maskierungslösungen. Dies ist besonders vorteilhaft bei großen Datenmengen oder komplexen Maskierungsregeln.
Nachteile
Begrenzte Funktionalität: Native DBMS-Tools bieten möglicherweise nicht den gleichen Funktionsumfang wie spezialisierte Datenmaskierungslösungen. Sie können fortschrittliche Maskierungstechniken wie formatkonforme Verschlüsselung oder bedingte Maskierung fehlen. Dies kann die Effektivität des Maskierungsprozesses einschränken.
Wartungsaufwand: Die Implementierung der Maskierung mithilfe von Views und gespeicherten Prozeduren erfordert individuelle Entwicklung und kontinuierliche Wartung. Da sich das Schema der Datenbank weiterentwickelt, müssen die Views und gespeicherten Prozeduren entsprechend aktualisiert werden. Dies kann zeitaufwändig und fehleranfällig sein, insbesondere in komplexen Datenbankumgebungen.
Skalierbarkeitsprobleme: Bei der Verwendung nativer DBMS-Tools für die Maskierung ist die Maskierungslogik eng mit dem Datenbankschema verbunden. Es kann schwierig sein, die Maskierungslösung über mehrere Datenbanken hinweg zu skalieren oder Änderungen in der Datenstruktur anzupassen. Dedizierte Maskierungslösungen bieten oft mehr Flexibilität und Skalierbarkeit beim Umgang mit verschiedenen Datenquellen und sich entwickelnden Anforderungen.
Sicherheitsbedenken: Views und gespeicherte Prozeduren sind Teil des Datenbanksystems. Benutzer mit den entsprechenden Berechtigungen können auf sie zugreifen. Wenn sie nicht ordnungsgemäß gesichert sind, besteht das Risiko eines unbefugten Zugriffs auf die Maskierungslogik oder die unmaskierten Daten. Dedizierte Maskierungslösungen bieten oft zusätzliche Sicherheitsmaßnahmen und Zugangskontrollen, um diese Risiken zu mindern.
Konsistenz und Standardisierung: Wenn man sich auf native DBMS-Tools verlässt, kann die Maskierungsimplementierung von Datenbank zu Datenbank und von Team zu Team variieren. Dieser Mangel an Konsistenz kann zu Unterschieden in den maskierten Daten führen und es schwierig machen, einen standardisierten Maskierungsansatz im gesamten Unternehmen aufrechtzuerhalten. Dedizierte Maskierungslösungen bieten einen zentralisierten und konsistenten Ansatz für die Maskierung und gewährleisten Einheitlichkeit und Compliance mit Datenschutzrichtlinien.
Erstellen von Maskierungsregeln in DataSunrise
Um die Datenmaskierung mit DataSunrise zu implementieren, können Sie entweder die web-basierte Benutzeroberfläche (GUI) oder die Befehlszeilenschnittstelle (CLI) verwenden.
Beispiel für die Verwendung der CLI für eine dynamische Maskierungsregel (einfache Zeile):
executecommand.bat addMaskRule -name script-rules -instance aurora -login aurorauser -password aurorauser -dbType aurora -maskType fixedStr -fixedVal XXXXXXXX -action mask -maskColumns 'test.table1.column2;test.table1.column1;'
Dieses Kommando erstellt eine Maskierungsregel namens “script-rules,” die Werte in den Spalten “test.table1.column2” und “test.table1.column1” der Tabelle “table1” ersetzt. Weitere Details finden Sie im DataSunrise CLI Guide.
Schlussfolgerung und Zusammenfassung
Datenmaskierung ist eine wichtige Sicherheitsmaßnahme, die Unternehmen hilft, sensible Informationen zu schützen. Das Verständnis der verschiedenen Datenmaskierungstypen und deren Einsatz kann die Datensicherheitsstrategie erheblich verbessern. Statische und dynamische Datenmaskierung haben jeweils ihre Rollen, abhängig von der Sensibilität der Daten.
Während native DBMS-Tools wie Views und gespeicherte Prozeduren zur Erstellung einer Maskierung verwendet werden können, haben sie im Vergleich zu spezialisierten Datenmaskierungslösungen Einschränkungen. Unternehmen sollten ihre Maskierungsanforderungen sorgfältig bewerten, unter Berücksichtigung von Faktoren wie Funktionalität, Skalierbarkeit, Sicherheit und Wartbarkeit, bevor sie sich für den geeigneten Ansatz entscheiden.
Dedizierte Maskierungslösungen wie DataSunrise bieten umfassende Funktionen, Flexibilität und Benutzerfreundlichkeit. Dies macht sie zu einer bevorzugten Wahl für Unternehmen, die robuste und zuverlässige Datenmaskierungspraktiken implementieren möchten. DataSunrise bietet eine breite Palette von Maskierungstechniken, unterstützt mehrere Datenbanken und bietet eine zentrale web-basierte Verwaltungskonsole zur einheitlichen Definition und Anwendung von Maskierungsregeln im gesamten Unternehmen.
Kommen Sie zu unserem Team für eine Online-Demonstration, um zu sehen, wie unsere Lösungen Ihre Daten effektiv schützen können.
Hinweis zu DataSunrise: Die außergewöhnlichen und flexiblen Tools von DataSunrise bieten nicht nur robusten Schutz, sondern gewährleisten auch Compliance und effizientes Datenmanagement. Nehmen Sie an einer Online-Demo teil, um zu erkunden, wie wir Ihnen beim Schutz Ihrer Datenbestände helfen können.
