
Verbesserung des Datenmanagements und der Leistung durch Datenteilung
Einführung
Die Explosion digitaler Technologien, Internet of Things (IoT)-Geräte und Online-Interaktionen hat enorme Datenmengen geschaffen, die gesammelt und analysiert werden können. In der heutigen datengesteuerten Welt ist die effiziente Verwaltung großer Datensätze sowohl für Unternehmen als auch für Forscher entscheidend. Eine mächtige Technik, die in den letzten Jahren an Bedeutung gewonnen hat, ist die Datenteilung. Dieser Artikel wird tief in die Welt der Datenteilung eintauchen und dabei ihre Grundlagen, Vorteile und praktische Anwendungen beleuchten. Wir werden auch einige Open-Source-Tools vorstellen und Beispiele geben, die Ihnen den Einstieg in diese wichtige Datenmanagement-Technik erleichtern.
Was ist Datenteilung?
Datenteilung ist der Prozess, bei dem ein kleinerer, handhabbarer Teil eines größeren Datensatzes erstellt wird, während dessen wichtige Merkmale und Beziehungen erhalten bleiben. Diese Technik ermöglicht es den Benutzern, mit einer repräsentativen Stichprobe von Daten zu arbeiten, was die Handhabung, Analyse und das Testen erleichtert, ohne die Integrität des ursprünglichen Datensatzes zu beeinträchtigen.
Warum sollten Sie sich für Datenteilung interessieren?
Datenteilung wird in unserer Ära der großen Datenmengen immer wichtiger. Hier sind einige Gründe, warum Sie auf diese Technik achten sollten:
- Handhabung massiver Datensätze: Moderne Datensätze können enorm sein. Beispielsweise könnte eine Social-Media-Plattform täglich Petabytes an Daten generieren. Mit solch riesigen Datenmengen zu arbeiten, kann ohne Teilung unpraktisch oder unmöglich sein.
- Ressourcenoptimierung: Die Verarbeitung vollständiger Datensätze erfordert oft erhebliche Rechenressourcen. Durch die Teilung können Sie mit einem Bruchteil der Daten arbeiten, was Zeit spart und den Hardwarebedarf reduziert.
- Kostenreduktion: Cloud-Computing- und Speicher kosten sind direkt an das Datenvolumen gebunden. Durch die Arbeit mit Teilmengen können Sie diese Kosten erheblich senken.
- Schnellere Entwicklungszyklen (Softwaretests): Bei der Softwareentwicklung kann die Verwendung vollständiger Produktionsdatensätzen für Tests den Entwicklungsprozess verlangsamen. Teilmengen ermöglichen schnellere Iterationen und eine schnellere Fehleridentifikation.
- Einhaltung der Datenschutzvorschriften: Mit Vorschriften wie GDPR und CCPA kann die Verwendung vollständiger Datensätze mit sensiblen Informationen für Tests oder Analysen riskant sein. Die Teilung hilft, anonymisierte, konforme Datensätze zu erstellen.
- Verbesserte Datenqualität: Kleinere Datensätze sind leichter zu reinigen und zu validieren, was möglicherweise zu qualitativ hochwertigeren Daten für Ihre Analysen oder Modelle führt.
Wie groß können Datensätze sein? Ein realweltliches Beispiel
Um das Ausmaß moderner Datensätze zu verstehen, betrachten wir einige Beispiele:
- Walmart Data Warehouse: Im Jahr 2019 wurde geschätzt, dass das Datenlager von Walmart über 2,5 Petabyte Daten enthält. Das entspricht 167-mal dem gesamten Buchbestand der US Library of Congress.
- Facebook Nutzerdaten: Facebook verarbeitet täglich über 500 Terabyte an Daten. Dazu gehören Benutzerbeiträge, Fotos, Videos und Interaktionsdaten.
- CERN’s Large Hadron Collider: Der LHC erzeugt enorme Datenmengen, die etwa 20.000 Jahren 24/7 HD-Videoaufzeichnungen entsprechen.
- Genomdaten: Das menschliche Genom besteht aus etwa 3 Milliarden Basenpaaren. Die Sequenzierung und Speicherung dieser Daten für Millionen von Individuen erzeugt Datensätze im Petabyte-Bereich.
- Klimawissenschaft: Das Center for Climate Simulation (NCCS) der NASA verwaltet über 32 Petabyte Daten aus verschiedenen Erdbeobachtungsmissionen.
Zur Veranschaulichung: 1 Petabyte entspricht 20 Millionen vierteiligen Aktenschränken gefüllt mit Text. Stellen Sie sich nun vor, Sie versuchen, diese Datenmenge in ihrer Gesamtheit zu analysieren oder zu verarbeiten – hier wird die Datenteilung unverzichtbar.
Wenn Sie beispielsweise ein Datenwissenschaftler bei Walmart wären und Kundenverhalten analysieren möchten, wäre es unpraktisch, mit den vollständigen 2,5 Petabyte zu arbeiten. Stattdessen würden Sie vielleicht eine Teilmenge von Daten für einen bestimmten Zeitraum, eine Region oder eine Produktkategorie erstellen und so Ihren Arbeitsdatensatz auf handlichere 50 Gigabyte reduzieren.
Warum ist Datenteilung nützlich?
Datenteilung bietet zahlreichen Nutzen für Datenprofis und Organisationen:
- Verbesserte Leistung: Die Arbeit mit kleineren Datensätzen reduziert die Verarbeitungszeit und den Ressourcenbedarf.
- Kosteneffektiv: Die Teilung kann Speicher- und Rechenkosten im Zusammenhang mit großen Datenmengen senken.
- Optimierte Tests: Sie ermöglicht schnellere und effizientere Tests datengesteuerter Anwendungen.
- Einhaltung von Datenschutzvorschriften: Die Teilung hilft bei der Erstellung anonymisierter Datensätze zur Einhaltung von Vorschriften.
- Vereinfachte Analyse: Kleinere Datensätze sind insbesondere in den Anfangsstadien eines Projekts leichter zu erkunden und zu analysieren.
Praktische Anwendungen der Datenteilung
Werfen wir einen Blick auf einige realweltliche Szenarien, in denen die Datenteilung von unschätzbarem Wert ist:
1. Softwareentwicklung und Tests
Entwickler müssen oft mit realistischen Daten zur Testung von Anwendungen arbeiten. Die Verwendung vollständiger Produktionsdatensätze kann jedoch sowohl unpraktisch als auch riskant sein. Die Teilung ermöglicht die Erstellung kleinerer, repräsentativer Testdatensätze, die die Komplexität realer Daten beibehalten, ohne sensible Informationen offenzulegen.
2. Datenanalyse und Exploration
Bei der Arbeit mit massiven Datensätzen kann die erste explorative Datenanalyse zeitaufwendig sein. Durch die Erstellung einer Teilmenge können Analysten schnell Einblicke gewinnen und Hypothesen testen, bevor sie zur vollständigen Datensatzanalyse übergehen.
3. Entwicklung von Machine-Learning-Modellen
In den frühen Phasen der Modellentwicklung können Datenwissenschaftler Teilmengen verwenden, um schnell verschiedene Algorithmen und Hyperparameter zu iterieren, bevor sie das vollständige Modell trainieren.
4. Datenbankoptimierung
Datenbankadministratoren können Teilmengen erstellen, um kleinere Versionen von Produktionsdatenbanken für Entwicklungs- und Testumgebungen zu schaffen, wodurch optimale Leistung ohne den Aufwand der Verwaltung von Vollreplikaten sichergestellt wird.
Tools und Techniken zur Datenteilung
Nachdem wir nun die Bedeutung der Datenteilung verstanden haben, werfen wir einen Blick auf einige beliebte Tools und Techniken zur effektiven Implementierung.
SQL für Datenteilung
SQL ist eine leistungsstarke Sprache zur Datenmanipulation und eignet sich hervorragend zur Teilung relationaler Datenbanken. Hier ist ein Beispiel, wie Sie eine Teilmenge von Daten mit SQL erstellen können:
-- Erstellen Sie eine Teilmenge von Kundendaten für das Jahr 2023 CREATE TABLE customer_subset_2023 AS SELECT * FROM customers WHERE EXTRACT(YEAR FROM order_date) = 2023 LIMIT 10000;
Diese Abfrage erstellt eine neue Tabelle customer_subset_2023, die bis zu 10.000 Kundendatensätze aus dem Jahr 2023 enthält. Das Ergebnis ist ein kleinerer, handlicher Datensatz für Analyse- oder Testzwecke.
Python für Datenteilung
Mit seinem reichen Ökosystem an Datenmanipulationsbibliotheken bietet Python leistungsstarke Tools zur Datenteilung.
Python hat einen eingebauten Datentyp namens ‘set’, der nützlich ist, um einzigartige Elemente zu speichern und mathematische Mengenoperationen durchzuführen. Für große Datenoperationen werden jedoch spezialisierte Bibliotheken wie pandas, NumPy oder PySpark verwendet, die aufgrund ihrer optimierten Leistung und erweiterten Datenmanipulationsfunktionen häufig zum Einsatz kommen.
Sehen wir uns ein Beispiel mit pandas an:
import pandas as pd
import numpy as np
# Laden Sie den vollständigen Datensatz
full_dataset = pd.read_csv('large_dataset.csv')
# Erstellen einer Teilmenge basierend auf einer Bedingung und einer zufälligen Stichprobe
subset = full_dataset[full_dataset['category'] == 'electronics'].sample(n=1000, random_state=42)
# Speichern der Teilmenge in einer neuen CSV-Datei
subset.to_csv('electronics_subset.csv', index=False)Dieses Skript lädt einen großen Datensatz, filtert ihn, um nur Elektronikartikel einzuschließen, und entnimmt dann zufällig 1.000 Zeilen, um eine Teilmenge zu erstellen. Das Ergebnis wird als neue CSV-Datei gespeichert.
Mit Pandas können Sie Daten auch mit folgenden Anweisungen filtern:
filtered_df_loc = df.loc[df['age'] > 25, ['name', 'city']]
oder
filtered_df = df[df['age'] > 25]
Bedingungsbasierte Datenfilterung in R
R ist eine weitere leistungsstarke Sprache zur Datenmanipulation und -analyse, die weit verbreitet in der statistischen Berechnung und Datenwissenschaft verwendet wird. Während Python oft für Deep Learning bevorzugt wird, hat R starke Fähigkeiten im Bereich des statistischen Lernens und des traditionellen Machine Learnings. Dies kann vorteilhaft sein, wenn Ihre Datenteilung modellbasierte Ansätze beinhaltet oder wenn Sie die statistischen Eigenschaften Ihrer Teilmengen analysieren müssen.
Sie können diesen Code in der Posit Cloud Version des kostenlosen RStudio-Kontos ausführen.
# Notwendige Bibliothek laden
library(dplyr)
# Nehmen wir an, wir haben einen großen Datensatz namens 'full_dataset'
# Für dieses Beispiel erstellen wir einen Beispieldatensatz
set.seed(123) # für Reproduzierbarkeit
full_dataset <- data.frame(
id = 1:1000,
category = sample(c("A", "B", "C"), 1000, replace = TRUE),
value = rnorm(1000)
)
# Erstellen einer Teilmenge basierend auf einer Bedingung und einer zufälligen Stichprobe
subset_data <- full_dataset %>%
filter(category == "A") %>%
sample_n(100)
# Anzeigen der ersten paar Zeilen der Teilmenge
head(subset_data)
# Speichern der Teilmenge in einer CSV-Datei
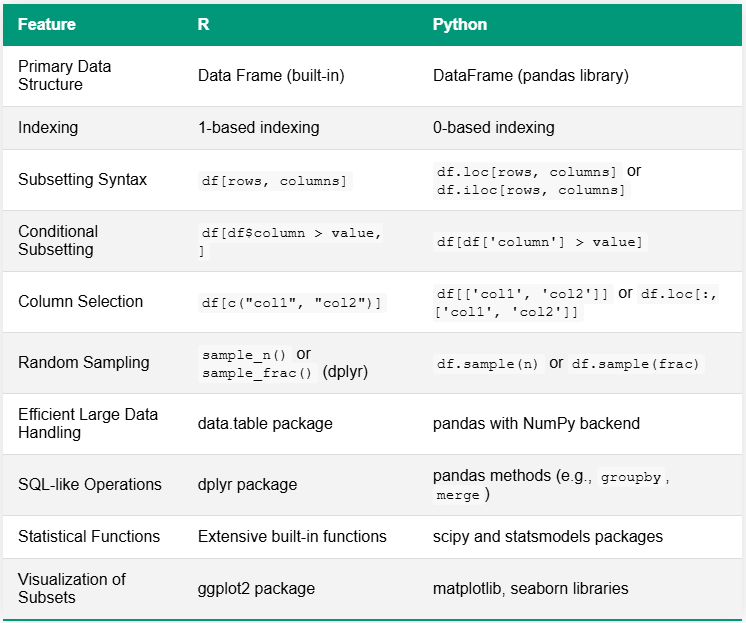
write.csv(subset_data, "category_A_subset.csv", row.names = FALSE)Die folgende Tabelle vergleicht R und Python für Datenteilungsaufgaben und hebt wesentliche Unterschiede in Syntax und Funktionalität hervor. Ein bemerkenswerter Unterschied liegt in ihren Ökosystemen: R hat oft eingebaute Funktionen oder verlässt sich auf einige umfassende Pakete, während Python typischerweise eine Vielzahl spezialisierter Bibliotheken für ähnliche Fähigkeiten verwendet.
Open-Source-Tools zur Datenteilung
Für fortgeschrittene Bedürfnisse stehen mehrere Open-Source-Tools zur Verfügung:
- Jailer: Ein Datenbank-Teilungstool, das die referentielle Integrität bewahrt.
- Benerator CE: Ein Open-Source-Framework zur Generierung und Teilung von Testdaten.
- Subsetter: Eine Python-Bibliothek zur Teilung relationaler Datenbanken bei gleichzeitiger Bewahrung der referentiellen Integrität.
Diese Werkzeuge bieten fortgeschrittenere Funktionen wie die Aufrechterhaltung komplizierter Beziehungen zwischen Tabellen und die Generierung synthetischer Daten zur Ergänzung von Teilmengen.
Best Practices für effektive Datenteilung
Um die Datenteilung optimal zu nutzen, sollten Sie diese Best Practices berücksichtigen:
- Wahren Sie die Datenintegrität: Stellen Sie sicher, dass Ihre Teilmenge die Beziehungen und Einschränkungen des ursprünglichen Datensatzes bewahrt.
- Verwenden Sie repräsentative Stichproben: Streben Sie an, Teilmengen zu erstellen, die die Merkmale des vollständigen Datensatzes genau widerspiegeln.
- Berücksichtigen Sie die Datenempfindlichkeit: Seien Sie bei der Teilung für Tests oder Entwicklung vorsichtig mit sensiblen Informationen und wenden Sie geeignete Anonymisierungstechniken an.
- Dokumentieren Sie Ihren Prozess: Halten Sie klare Aufzeichnungen darüber, wie Teilmengen erstellt wurden, um die Reproduzierbarkeit sicherzustellen.
- Validieren Sie Ihre Teilmengen: Überprüfen Sie regelmäßig, ob Ihre Teilmengen weiterhin den vollständigen Datensatz genau repräsentieren, wenn dieser sich im Laufe der Zeit entwickelt.
Herausforderungen der Datenteilung
Obwohl diese Datenverarbeitung viele Vorteile bietet, ist sie nicht ohne Herausforderungen:
- Beibehaltung von Datenbeziehungen: In komplexen Datenbanken kann es schwierig sein, die referentielle Integrität aufrechtzuerhalten.
- Sicherstellung repräsentativer Stichproben: Es kann eine Herausforderung sein, Teilmengen zu erstellen, die alle Aspekte des vollständigen Datensatzes genau repräsentieren.
- Umgang mit Zeitreihendaten: Die Teilung von Zeitreihendaten bei gleichzeitiger Erhaltung temporaler Muster erfordert sorgfältige Überlegungen.
- Skalierung mit großen Daten: Mit zunehmender Größe der Datensätze kann sogar die Erstellung von Teilmengen rechnerisch intensiv werden.
Fazit
Die Datenteilung ist eine mächtige Technik, die Ihre Datenmanagementpraktiken erheblich verbessern kann. Durch die Erstellung kleinerer, handhabbarerer Datensätze können Sie die Leistung verbessern, Kosten reduzieren und Ihre Entwicklungs- und Testprozesse straffen. Ob Sie SQL, Python oder spezialisierte Werkzeuge verwenden – die Beherrschung der Datenteilung ist eine wesentliche Fähigkeit für jeden Datenprofi.
Denken Sie daran, wenn Sie Ihre Reise zur Datenteilung antreten, dass der Schlüssel zum Erfolg in der Wahrung der Datenintegrität, der Sicherstellung der Repräsentativität und der Wahl der richtigen Werkzeuge für Ihre spezifischen Bedürfnisse liegt.
