
Datenengpass Test

Die Effizienz von Datenverarbeitung und -übertragung ist entscheidend für eine optimale Systemleistung. Ein Data-Bottleneck-Test ist ein wesentliches Werkzeug zur Identifizierung und Beseitigung von Leistungsbeschränkungen in verschiedenen Computerumgebungen. Dieser Artikel wird die Grundlagen von Data-Bottleneck-Tests untersuchen und Methoden zur Beschaffung geeigneter Testdaten aufzeigen.
Obwohl der Markt eine Vielzahl von Tools für Datenbank- und Anwendungs-Bottleneck-Tests bietet, erfordern viele von diesen Lösungen umfangreiche Fachkenntnisse, um sie effektiv umzusetzen. DataSunrise zeichnet sich jedoch durch eine benutzerfreundliche und dennoch leistungsstarke Plattform aus, die den komplexen Prozess des Data-Bottleneck-Tests vereinfacht.
Warum Data-Bottleneck-Tests wichtig sind
Stellen Sie sich vor, Sie versuchen, Wasser durch einen Trichter zu gießen. Der Wasserfluss ist glatt, bis er den engen Teil des Trichters erreicht, wo er sich verlangsamt. Dies ist vergleichbar mit der Funktionsweise von Datenengpässen in Computersystemen. Datenengpässe können die Systemleistung erheblich beeinträchtigen, was zu langsameren Verarbeitungsgeschwindigkeiten und verringerter Effizienz führt.
Data-Bottleneck-Tests finden Systemschwachstellen, sodass Sie Leistung und Effizienz verbessern können. Egal, ob Sie Softwareentwickler, Datenbankadministrator oder IT-Experte sind, das Verständnis und die Durchführung von Data-Bottleneck-Tests sind entscheidend für die Aufrechterhaltung hochleistungsfähiger Systeme.
Verständnis von Datenengpässen
Was ist ein Datenengpass?
Ein Datenengpass tritt auf, wenn der Datenfluss in einem System eingeschränkt ist, was zu Verzögerungen und schlechterer Leistung führt. Diese Einschränkungen können an verschiedenen Punkten auftreten: CPU-Verarbeitung, Speicherzugriff, Speicher-I/O, Netzwerkübertragung.
Die Auswirkungen von Datenengpässen
Datenengpässe können weitreichende Folgen haben: langsamere Anwendungsreaktionszeiten, verringerter Systemdurchsatz, erhöhte Ressourcennutzung, schlechte Benutzererfahrung.
Durch die Identifizierung und Beseitigung dieser Engpässe können Sie die Leistung und Zuverlässigkeit Ihres Systems erheblich verbessern.
Durchführung eines Data-Bottleneck-Tests
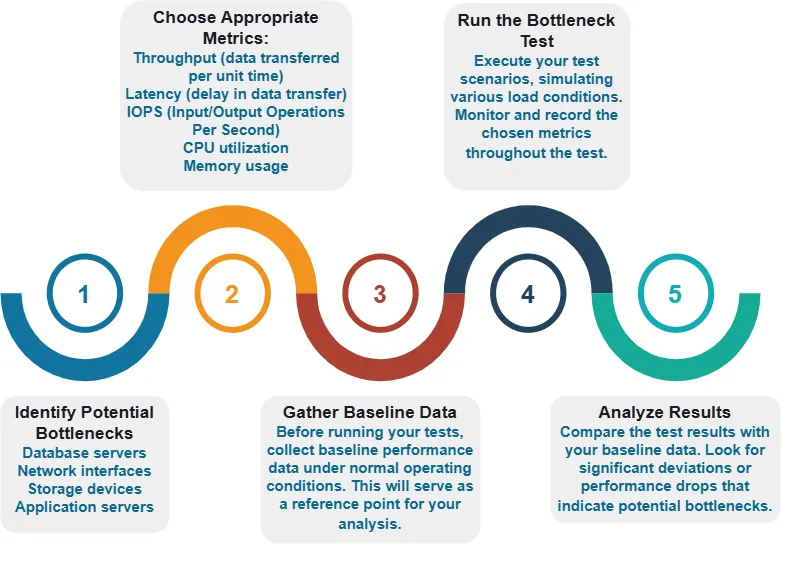
Beschaffung von Testdaten für Bottleneck-Tests
Eine der Herausforderungen bei der Durchführung von Data-Bottleneck-Tests besteht darin, geeignete Testdaten zu erhalten. Lassen Sie uns einige Methoden zur Beschaffung oder Generierung von Testdaten erkunden.
Verwendung von Produktionsdaten (mit Vorsicht)
Obwohl die Verwendung echter Produktionsdaten die genauesten Ergebnisse liefern kann, ist sie mit erheblichen Risiken verbunden:
- Datenschutzbedenken
- Regulatorische Compliance-Probleme
- Potenzielle Datenverletzungen
Wenn Sie sich dafür entscheiden, Produktionsdaten zu verwenden, stellen Sie sicher, dass Sie die ordnungsgemäße Genehmigung haben und robuste Sicherheitsmaßnahmen implementieren.
Generierung synthetischer Daten
DataSunrise zeichnet sich als führend in der Datenbanksicherheit und Datenmanagementlösungen aus und bietet fortschrittliche synthetische Testdaten-Funktionen für eine breite Palette von Datenbanken und Datenbanken. Unsere fortschrittlichen Tools vereinfachen den Prozess der Generierung hochwertiger Testdaten erheblich und sparen Organisationen wertvolle Zeit und Ressourcen.
Mit Unterstützung für Dutzende von beliebten Datenbankplattformen bietet DataSunrise unvergleichliche Flexibilität und Effizienz bei der Erstellung realistischer, datenschutzkonformer Testdatensätze. Dies macht es zu einem unschätzbaren Asset für Unternehmen, die umfassende Data-Bottleneck-Tests durchführen möchten, ohne sensible Informationen zu gefährden.
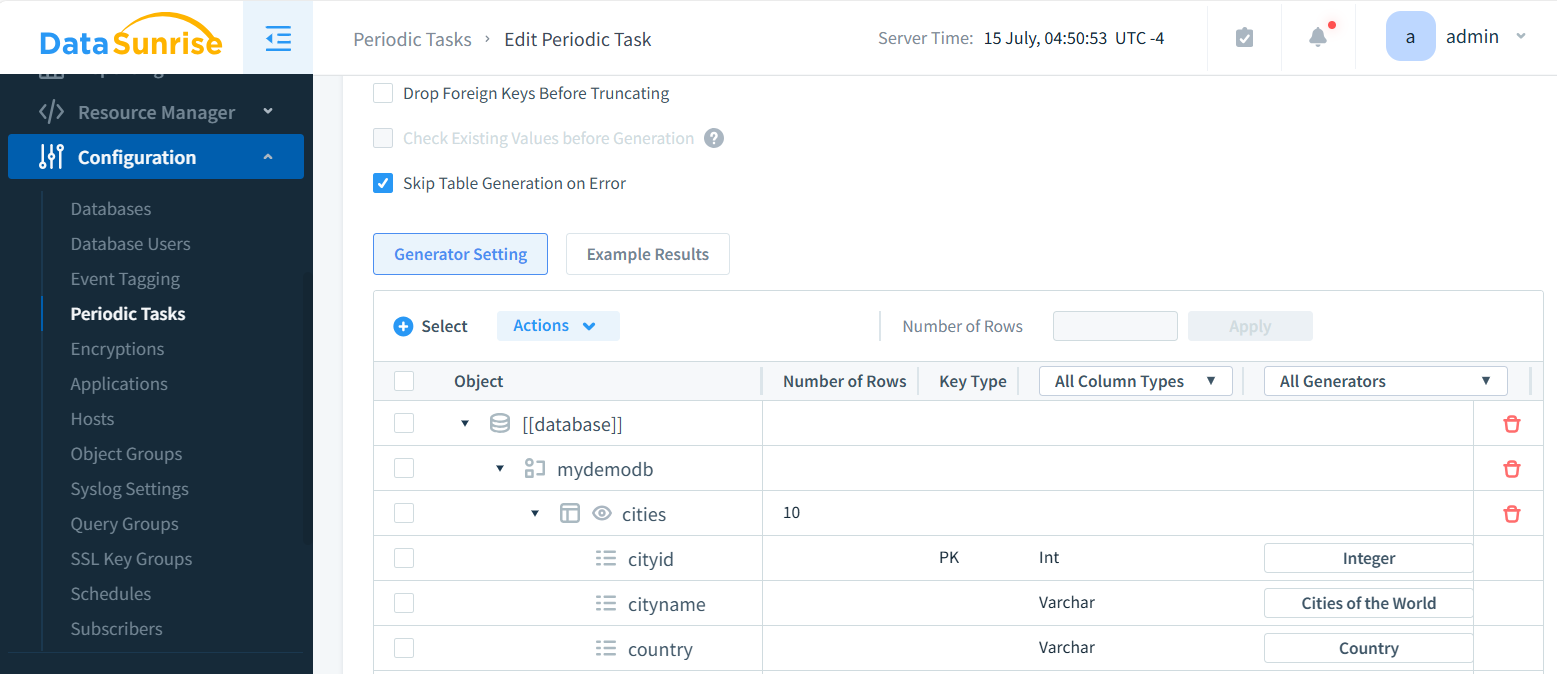
Synthetische Daten bieten eine sichere Alternative zu Produktionsdaten. Sie ahmen die Eigenschaften echter Daten künstlich nach, ohne sensible Informationen preiszugeben.
Vorteile synthetischer Daten:
- Keine Datenschutzrisiken
- Anpassbar an spezifische Test-Szenarien
- Skalierbar auf große Datenmengen
Methoden zur Generierung synthetischer Daten:
- Generierung zufälliger Daten: Erstellen von Daten unter Verwendung von Zufallszahlengeneratoren und vordefinierten Regeln.
- Musterbasierte Generierung: Generieren von Daten, die bestimmten Mustern oder Verteilungen folgen, die in echten Daten beobachtet werden.
- Modellbasierte Generierung: Verwenden von maschinellen Lernmodellen, um Daten zu erstellen, die echten Datensätzen ähneln.
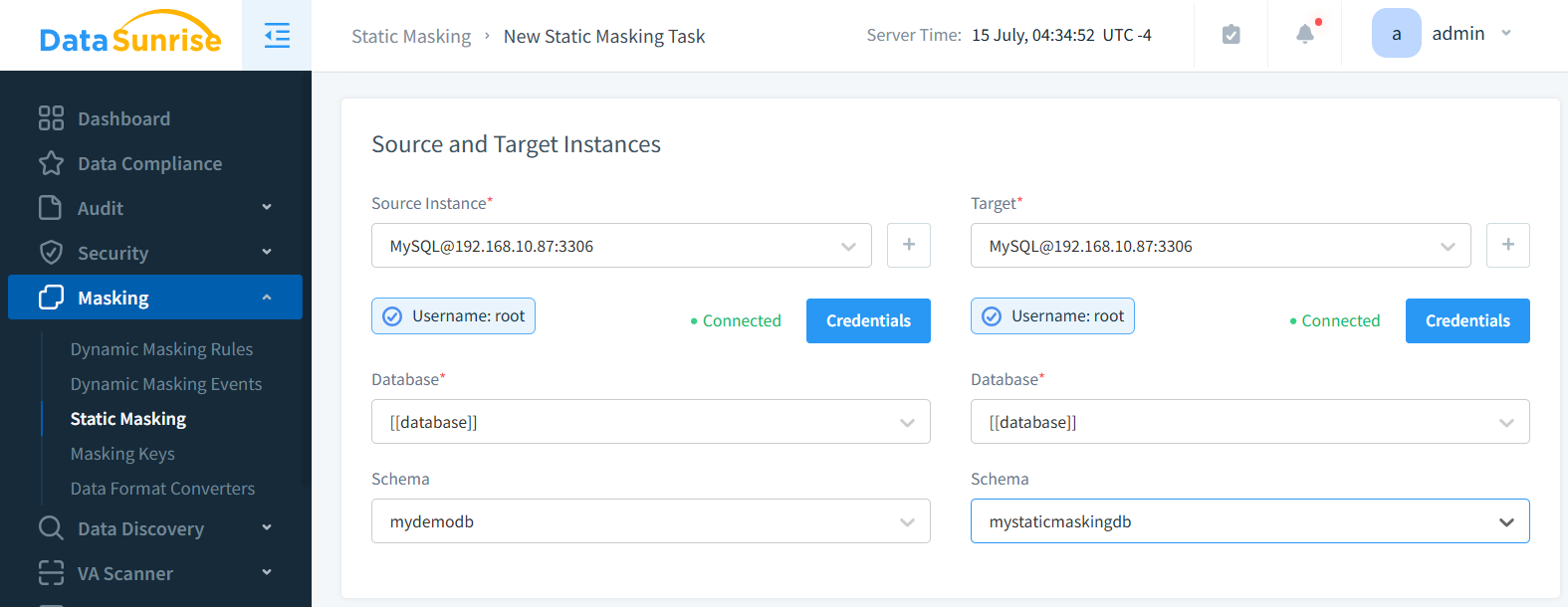
Datentarnung
Datentarnung umfasst das Ändern von sensiblen Informationen in einem Datensatz, wobei das Format und die statistischen Eigenschaften beibehalten werden. Diese Methode ermöglicht es Ihnen, produktionsähnliche Daten zu verwenden, ohne vertrauliche Informationen preiszugeben.
DataSunrises Datentarnungslösung zeichnet sich als leistungsstarkes und vielseitiges Werkzeug im Bereich Datenschutz und -sicherheit aus. Diese funktionsreiche Implementierung bietet Organisationen eine robuste Möglichkeit, sensible Informationen zu schützen und gleichzeitig die Datenverwendbarkeit für Tests, Entwicklung und Analysezwecke aufrechtzuerhalten.
Typische Datentarnungstechniken:
- Substitution: Ersetzen von sensiblen Werten durch fiktive, aber realistische Alternativen.
- Shuffling: Umsortieren von Daten innerhalb einer Spalte, um die Assoziation zwischen Datensätzen zu durchbrechen.
- Verschlüsselung: Transformieren von Daten unter Verwendung von Verschlüsselungsalgorithmen.
Open-Source-Datensätze
Viele Organisationen und Institutionen stellen Open-Source-Datensätze zur Verfügung, die für Testzwecke verwendet werden können. Diese Datensätze stammen oft aus realen Szenarien, wurden jedoch anonymisiert und zur öffentlichen Nutzung freigegeben.
Quellen für Open-Source-Datensätze:
- Regierungsdatenportale
- Akademische Forschungsrepositorien
- Datenwissenschaft-Wettbewerbsplattformen (z.B. Kaggle)
Erstellung benutzerdefinierter Testdaten
Mit Python und der Faker Bibliothek können Sie ganz einfach zufällige Daten mit Funktionsaufrufen wie diesen generieren:
fake.name()
fake.email()
Beispiele zur Datengenerierung finden Sie in unseren Artikeln über synthetische Daten und KI-Datengeneratoren.
Best Practices für Data-Bottleneck-Tests
Um die Effektivität Ihrer Data-Bottleneck-Tests zu gewährleisten, beachten Sie diese Best Practices:
- Klein anfangen: Beginnen Sie mit einfachen Testszenarien und erhöhen Sie schrittweise die Komplexität.
- Komponenten isolieren: Testen Sie einzelne Systemkomponenten, bevor Sie End-to-End-Tests durchführen.
- Verwendung realistischer Datenvolumen: Stellen Sie sicher, dass Ihre Testdaten reale Nutzungsmuster widerspiegeln.
- Ressourcennutzung überwachen: Behalten Sie während der Tests CPU-, Speicher- und I/O-Nutzung im Auge.
- Tests wiederholen: Führen Sie mehrere Iterationen durch, um Variabilitäten zu berücksichtigen und Ergebnisse zu bestätigen.
- Alles dokumentieren: Führen Sie detaillierte Aufzeichnungen über Testkonfigurationen, Ergebnisse und Beobachtungen.
Werkzeuge für Data-Bottleneck-Tests und DataSunrise
Mehrere Werkzeuge können bei der Durchführung von Data-Bottleneck-Tests hilfreich sein:
- Apache JMeter: Open-Source-Tool für Lasttests und Leistungsbewertung.
- Gatling: Scala-basiertes Lasttest-Tool zur Analyse und Messung der Systemleistung.
- Locust: Python-basiertes Tool für verteilte Lasttests.
- iperf3: Tool zur Messung der Netzwerkleistung.
DataSunrise Lösung
Zu den wichtigsten Vorteilen des Ansatzes von DataSunrise für Bottleneck-Tests gehören:
- Intuitive Benutzeroberfläche: Entwickelt mit Fokus auf die Benutzererfahrung, sodass auch Nicht-Experten komplexe Tests einrichten und durchführen können.
- Hochgradig anpassbar: Bietet eine Vielzahl von Parametern und Szenarien, die leicht an spezifische Testanforderungen angepasst werden können.
- Umfassende Abdeckung: Fähig, verschiedene Aspekte der Datenbankleistung zu testen, von der Abfrageausführung bis hin zu Datenübertragungsraten.
- Automatisierte Testgenerierung: Erstellt intelligent Testszenarien basierend auf tatsächlichen Datenbankenutzung-Mustern und reduziert so die manuelle Konfigurationszeit.
- Echtzeitüberwachung: Bietet Live-Einblicke während der Testausführung, sodass Engpässe sofort identifiziert werden können.
- Detaillierte Berichterstattung: Erstellt ausführliche, leicht verständliche Berichte, die Leistungsprobleme hervorheben und Optimierungen vorschlagen.
- Integrationsmöglichkeiten: Funktioniert nahtlos mit verschiedenen Datenbanksystemen und kann in bestehende Entwicklungs- und Testworkflows integriert werden.
- Skalierbarkeit: Bewältigt Tests für Datenbanken jeder Größe, von kleinen Anwendungen bis hin zu großen Unternehmenssystemen.
Testresultate interpretieren
Nach der Durchführung Ihrer Data-Bottleneck-Tests ist eine sorgfältige Analyse entscheidend. Achten Sie auf:
- Unvorhergesehene Spitzen bei der Ressourcennutzung
- Konsequente Leistungsdegradationen unter bestimmten Bedingungen
- Diskrepanzen zwischen Komponenten, die eine ähnliche Leistung haben sollten
Denken Sie daran, dass das Ziel nicht nur darin besteht, Engpässe zu identifizieren, sondern auch deren Ursachen zu verstehen und effektive Lösungen zu entwickeln.
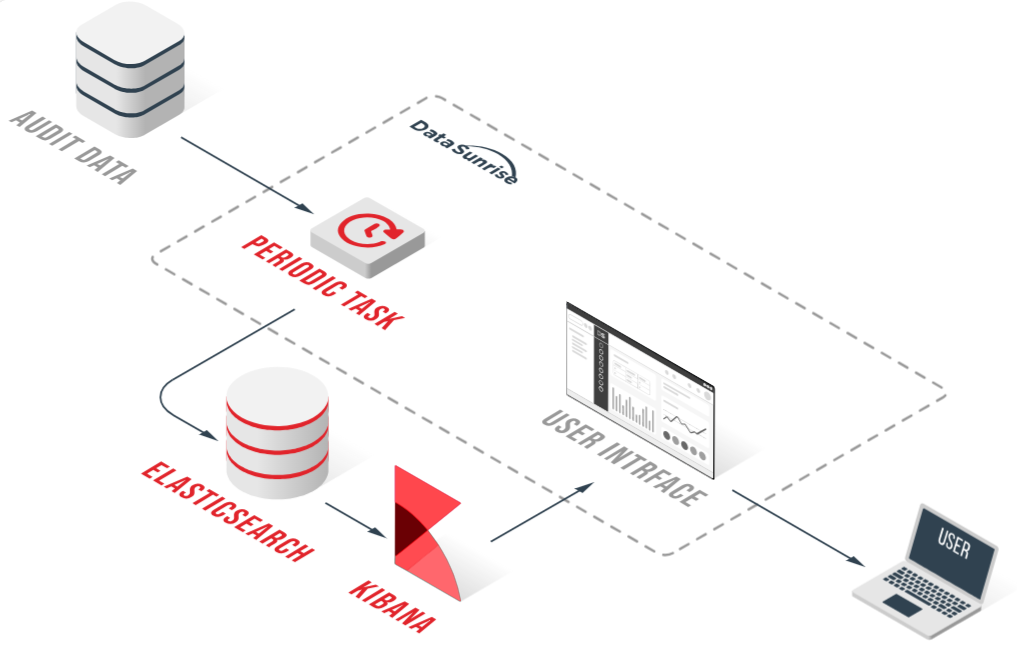
Durch die Nutzung der Audit-Integration von DataSunrise können Organisationen tiefgehende, umsetzbare Einblicke in ihre Datenbankleistung gewinnen, die proaktive Optimierungen und effiziente Engpassidentifikationen ermöglichen.
Fazit
Data-Bottleneck-Tests sind unschätzbare Werkzeuge zur Optimierung der Systemleistung. Lernen Sie die Grundlagen von Tests kennen und finden Sie die richtigen Daten, um Leistungsprobleme in Ihren Systemen effektiv zu identifizieren und zu beheben. Achten Sie bei den Tests darauf, dass die Daten reale Situationen genau widerspiegeln und sicher bleiben.
Sie können synthetische Daten, maskierte Produktionsdaten oder benutzerdefinierte Datensätze für diesen Zweck verwenden. Sie können synthetische Daten, maskierte Produktionsdaten oder benutzerdefinierte Datensätze für diesen Zweck verwenden.
Denken Sie daran, dass es sich bei Data-Bottleneck-Tests um einen iterativen Prozess handelt, bei dem kontinuierliche Tests und Optimierungen helfen werden, die Spitzenleistung Ihres Systems angesichts sich entwickelnder Anforderungen an die Datenverarbeitung aufrechtzuerhalten.
Für diejenigen, die benutzerfreundliche und flexible Tools für die Datenbanksicherheit suchen, einschließlich äußerst nützlicher synthetischer Daten- und Datenmaskierungsfunktionen, sollten die Angebote von DataSunrise in Betracht ziehen. Unser umfassendes Toolset kann den Prozess der Generierung und Verwaltung von Testdaten für Ihre Bottleneck-Tests erheblich vereinfachen und gleichzeitig Datenschutz und Compliance gewährleisten. Besuchen Sie die DataSunrise-Website, um eine Demo anzusehen und zu erfahren, wie unsere Lösungen Ihnen bei Datenmanagement und Tests helfen können.
