
Datenklassifizierungs-Framework: Was ist es & welche Vorteile bietet es

Einführung
In der heutigen datenbasierten Welt verarbeiten Organisationen täglich immense Informationsmengen. Die Sicherstellung der Sicherheit, Integrität und ordnungsgemäßen Verwaltung dieser Daten ist entscheidend, um den Geschäftsbetrieb aufrechtzuerhalten, regulatorische Anforderungen zu erfüllen und sensible Informationen zu schützen. Hier kommt ein gut gestaltetes Datenklassifizierungs-Framework ins Spiel.
Durch die Kategorisierung von Daten basierend auf ihrer Sensibilität und Kritikalität können Organisationen geeignete Sicherheitskontrollen und Zugriffspolitiken implementieren. Dieser Artikel erklärt Datenklassifizierungs-Frameworks, einschließlich ihrer Hauptkomponenten, bewährten Verfahren und praxisnahen Beispielen.
Verständnis von Datenklassifizierungs-Frameworks
Ein Datenklassifizierungs-Framework ist ein strukturierter Ansatz zur Kategorisierung der Datenbestände einer Organisation basierend auf ihrer Sensibilität, ihrem Wert und ihrer Kritikalität. Es beinhaltet die Zuordnung von Daten zu vordefinierten Kategorien oder Ebenen, die jeweils spezifische Sicherheitsanforderungen und Handhabungsprozeduren aufweisen. Die Hauptziele eines Datenklassifizierungs-Frameworks sind:
- Sensible Daten identifizieren und priorisieren
- Angemessene Sicherheitskontrollen basierend auf der Datensensibilität anwenden
- Compliance mit regulatorischen Anforderungen sicherstellen
- Effizientes Datenmanagement und Governance erleichtern
Durch die Implementierung eines Datenklassifizierungs-Frameworks können Organisationen fundierte Entscheidungen bezüglich Datenschutz, Zugriffskontrollen und Risikomanagement treffen.
Wichtige Komponenten eines Datenklassifizierungs-Frameworks
Bei der Entwicklung eines Datenklassifizierungs-Frameworks sollten mehrere wichtige Komponenten berücksichtigt werden:
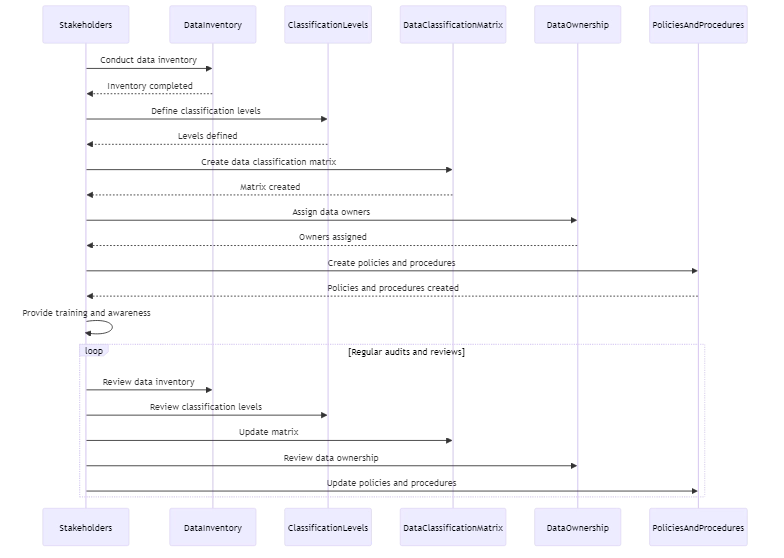
- Dateninventar: Führen Sie eine gründliche Inventarisierung aller Datenbestände durch, einschließlich strukturierter und unstrukturierter Daten in verschiedenen Systemen und Repositories.
- Klassifizierungsstufen: Definieren Sie klare und eindeutige Klassifizierungsstufen basierend auf der Datensensibilität. Häufige Stufen umfassen Öffentlich, Intern, Vertraulich und Eingeschränkt.
- Datenklassifizierungsmatrix: Erstellen Sie eine Matrix, die Datentypen den Klassifizierungsstufen zuordnet. Diese Matrix dient als Referenzleitfaden für eine konsistente Datenkategorisierung.
- Datenbesitz: Weisen Sie Datenbesitzer zu, die für die Klassifizierung und Verwaltung von Daten in ihren jeweiligen Domänen verantwortlich sind.
- Richtlinien und Verfahren: Erstellen Sie Regeln für die Verwaltung, den Zugriff und die Sicherung von Daten gemäß ihrer Klassifizierungsstufe.
Hier ist ein Beispiel für eine einfache Datenklassifizierungsmatrix:
Datentyp Öffentlich Intern Vertraulich Eingeschränkt Finanzaufzeichnungen X Kunden-PII X Marketing-Inhalte X HR-Dokumente X
Diese Matrix zeigt die Privatsphärenebenen verschiedener Informationstypen. Finanzdokumente werden vertraulich behandelt. Kundendaten sind eingeschränkt. Werbematerialien sind öffentlich zugänglich. HR-Unterlagen sind ausschließlich für den internen Gebrauch.
Sicherheit und Bequemlichkeit ausgleichen
Bei der Implementierung eines Datenklassifizierungs-Frameworks ist es wichtig, ein Gleichgewicht zwischen Sicherheit und Bequemlichkeit zu finden. Während strenge Sicherheitskontrollen für sensible Daten erforderlich sind, können übermäßig restriktive Maßnahmen die Produktivität und Benutzererfahrung beeinträchtigen. Berücksichtigen Sie die folgenden bewährten Verfahren:
- Wenden Sie das Prinzip der geringsten Privilegien an und gewähren Sie nur denjenigen Zugriff, die ihn für ihre Arbeitsfunktionen benötigen.
- Implementieren Sie eine rollenbasierte Zugriffskontrolle (RBAC), um sicherzustellen, dass Benutzer die entsprechenden Berechtigungen basierend auf ihren Rollen und Verantwortlichkeiten haben.
- Verwenden Sie Verschlüsselung für Daten im Ruhezustand und in der Übertragung, insbesondere für vertrauliche und eingeschränkte Daten.
- Überprüfen und aktualisieren Sie regelmäßig Zugangsberechtigungen, um das Prinzip der geringsten Privilegien aufrechtzuerhalten.
Bewährte Verfahren und Strategien
Um die Effektivität Ihres Datenklassifizierungs-Frameworks zu gewährleisten, sollten Sie die folgenden bewährten Verfahren und Strategien berücksichtigen:
- Beziehen Sie Stakeholder aus verschiedenen Abteilungen ein, einschließlich IT, Sicherheit, Recht und Geschäftseinheiten, um ein umfassendes Verständnis der Datenanforderungen und -sensibilitäten zu gewinnen.
- Bieten Sie Schulungs- und Bewusstseinsprogramme an, um Mitarbeiter über das Datenklassifizierungs-Framework, ihre Verantwortlichkeiten und ordnungsgemäße Datenhandhabungsverfahren zu informieren.
- Automatisieren Sie Datenklassifizierungsprozesse, wo immer möglich, und nutzen Sie Tools und Technologien, um Klassifizierungskennzeichnungen und Metadaten konsistent anzuwenden.
- Führen Sie regelmäßige Audits und Überprüfungen durch, um die Genauigkeit und Effektivität der Datenklassifizierung sicherzustellen.
- Integrieren Sie die Datenklassifizierung mit anderen Sicherheitskontrollen, wie z. B. Datenverlustprävention (DLP) und Zugriffsverwaltungssysteme.
Hier ist ein Beispiel dafür, wie Sie die Datenklassifizierung in der Praxis anwenden können:
Angenommen, eine Organisation verfügt über eine Kundendatenbank, die sensible PII enthält. Autorisiertes Personal hat nur eingeschränkten Zugriff auf die als Eingeschränkt klassifizierte Datenbank. Wenn ein Mitarbeiter versucht, auf die Datenbank zuzugreifen, muss er zusätzliche Identitätsnachweise, wie die Nutzung von MFA, erbringen. Darüber hinaus markiert das System automatisch jede aus der Datenbank entnommene Information als Eingeschränkt und verschlüsselt sie, bevor sie weitergegeben oder gespeichert wird.
Wichtigkeit von Datenklassifizierungs-Frameworks
Die Implementierung eines Datenklassifizierungs-Frameworks ist aus mehreren Gründen entscheidend:
- Regulatorische Compliance: Viele Branchen haben spezifische Vorschriften zur Datensicherung, wie GDPR, HIPAA oder PCI DSS. Ein gut definiertes Datenklassifizierungs-Framework hilft Organisationen, diese regulatorischen Anforderungen zu erfüllen, indem sie sensible Daten identifizieren und sichern.
- Risikomanagement: Durch die Organisation von Daten nach Sensibilität können Organisationen das Risiko von Datenschutzverletzungen, unbefugtem Zugriff und Datenverlust verringern. Sie können auch geeignete Sicherheitsmaßnahmen implementieren, um diese Risiken weiter zu verwalten.
- Effiziente Ressourcenzuweisung: Die Datenklassifizierung ermöglicht es Organisationen, Sicherheitsbemühungen zu priorisieren und Ressourcen effektiv zuzuweisen. Indem sie sich auf den Schutz der kritischsten und sensibelsten Daten konzentrieren, können Organisationen ihre Sicherheitsinvestitionen optimieren.
- Verbesserte Daten-Governance: Ein Datenklassifizierungs-Framework hilft Organisationen, Daten zu verwalten, indem es klare Richtlinien, Verfahren und Eigentumsverhältnisse für Datenbestände erstellt.
Fazit
Organisationen benötigen ein starkes Datenklassifizierungs-Framework. Es hilft, ihre Daten zu schützen und gesetzliche Vorschriften zu erfüllen. Es ermöglicht auch, fundierte Entscheidungen über Datensicherheit und -management zu treffen.
Durch das Verständnis der Datenklassifizierung können Organisationen einen Plan zur Sicherung und Zugänglichkeit ihrer Daten erstellen. Dieser Plan sorgt auch für die Vertraulichkeit, Integrität und Verfügbarkeit der Daten.
DataSunrise bietet Tools zur Datenverwaltung an, einschließlich Sicherheit, Auditregeln, Maskierung und Compliance. Diese Tools erleichtern die Implementierung eines Datenklassifizierungs-Frameworks. Ihre umfassenden Lösungen können Organisationen dabei helfen, ihre Datenklassifizierungsprozesse zu vereinfachen und die höchsten Datenschutzstandards sicherzustellen. Für weitere Informationen können Sie unser Team kontaktieren und eine Online-Demo-Session vereinbaren.
