
Datenherkunft mit Snowflake für ein besseres Datenmanagement
Einführung
In der heutigen datengesteuerten Welt ist es entscheidend, den Weg Ihrer Daten zu verstehen. Treten Sie ein in das Konzept der Datenherkunft, ein kraftvolles Konzept, das die Art und Weise revolutioniert, wie Organisationen ihre Datenressourcen verwalten und nutzen. Dieser Artikel untersucht die Datenherkunft mit einem Fokus auf deren Verwendung in Snowflake, einer führenden Cloud-Datenplattform.
Unternehmen verlassen sich zunehmend auf Daten zur Entscheidungsfindung. Transparenz und Rückverfolgbarkeit bei Datenprozessen sind wichtiger denn je. Die Datenherkunft bietet diese Sichtbarkeit, indem sie ein klares Bild von der Herkunft der Daten, deren Transformationen und der letztendlichen Verwendung liefert. Aber wie passt dies in den größeren Rahmen des Datenmanagements und welche Schritte sind erforderlich, um eine effektive Datenherkunft zu etablieren?
Wir werden die Bedeutung der Datenherkunft in modernen Datenökosystemen untersuchen und wie Organisationen diese innerhalb des Snowflake-Frameworks nutzen. Begleiten Sie uns bei dieser Diskussion!
Was ist Datenherkunft?
Die Datenherkunft ist der Lebenszyklus der Daten. Sie umfasst die Ursprünge der Daten und deren Bewegung im Laufe der Zeit. Dieses Konzept bietet Sichtbarkeit in die Datenanalyse-Pipeline und hilft dabei, Fehler bis zu ihren Quellen zurückzuverfolgen.
Hauptkomponenten der Datenherkunft
Bitte sehen Sie sich das folgende Bild für die Details an:

Die Datenherkunft verfolgt diese Komponenten und erstellt eine Karte der Reise der Daten durch die Systeme.
Ein wesentlicher Bestandteil des Datenmanagements
Datenherkunft ist tatsächlich ein integraler Bestandteil des Datenmanagements. Sie fällt unter die größere Überschrift der Datenverwaltung, die das gesamte Management der Datenverfügbarkeit, -nutzbarkeit, -integrität und -sicherheit umfasst.
Warum Datenherkunft im Datenmanagement wichtig ist
- Verbesserte Datenqualität: Durch die Verfolgung der Daten vom Ursprung bis zum Ziel können Organisationen Fehler schnell identifizieren und beheben.
- Verbesserte Compliance: Die Datenherkunft hilft, regulatorische Anforderungen zu erfüllen, indem sie einen klaren Prüfpfad bietet.
- Bessere Entscheidungsfindung: Das Verstehen der Herkunft und Transformationen der Daten führt zu fundierteren Geschäftsentscheidungen.
- Erhöhte Effizienz: Die Verfolgung der Datenherkunft kann Prozesse rationalisieren und Redundanzen reduzieren.
Die Hauptschritte der Datenherkunft
Die Implementierung der Datenherkunft umfasst mehrere wichtige Schritte:
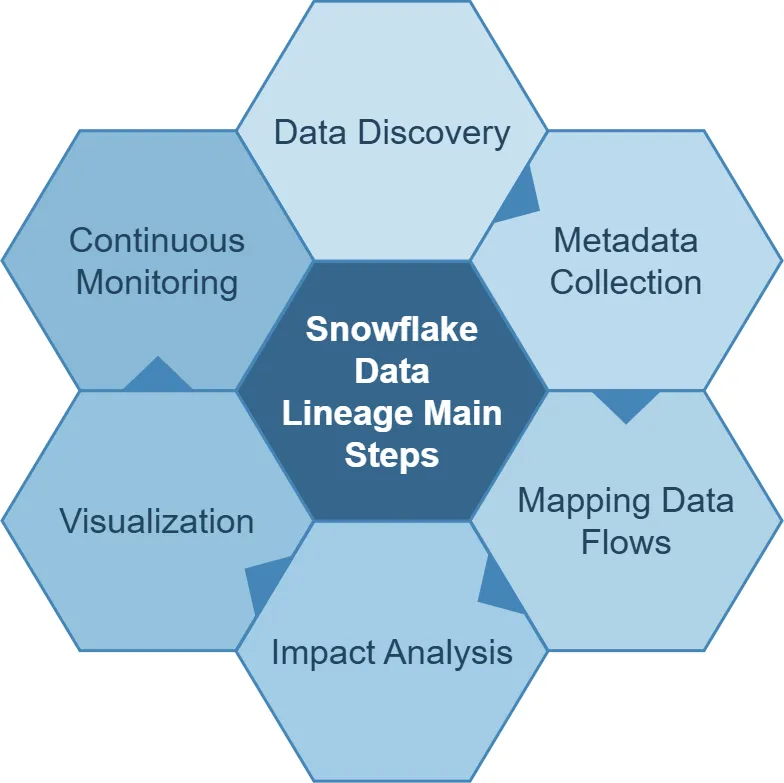
1. Datenentdeckung
In diesem ersten Schritt geht es darum, alle Datenressourcen innerhalb einer Organisation zu identifizieren und zu katalogisieren. Es ist wichtig, zu verstehen, welche Daten existieren und wo sie sich befinden.
2. Metadatenerfassung
Die Erfassung von Metadaten zu jeder Datenressource ist unerlässlich. Dies umfasst Informationen zu Datenquellen, Schemata und Transformationen.
3. Datenflussabbildung
In diesem Schritt geht es darum, nachzuverfolgen, wie Daten durch verschiedene Systeme und Prozesse fließen. Es geht darum, die Reise der Daten von ihrer Quelle bis zu ihrem endgültigen Ziel zu verstehen.
4. Auswirkungsanalyse
Sobald die Datenflüsse abgebildet sind, können Organisationen analysieren, wie sich Änderungen in einem Teil des Systems auf andere Bereiche auswirken könnten.
5. Visualisierung
Die Erstellung visueller Darstellungen der Datenherkunft hilft den Interessengruppen, komplexe Datenbeziehungen leichter zu verstehen.
6. Kontinuierliches Monitoring
Die Datenherkunft ist keine einmalige Anstrengung. Sie erfordert fortlaufendes Monitoring und Updates, um Änderungen in den Datenflüssen und Systemen widerzuspiegeln.
Datenherkunft in Snowflake
Snowflake, eine cloud-basierte Datenplattform, bietet robuste Funktionen zur Implementierung und Verwaltung der Datenherkunft. Lassen Sie uns untersuchen, wie Snowflake diesen wichtigen Aspekt des Datenmanagements unterstützt.
Snowflakes Ansatz zur Datenherkunft
Snowflake bietet eingebaute Funktionen zur Verfolgung der Datenherkunft, hauptsächlich durch die Metadatenschicht und die Funktionen zur Abfragehistorie.
Beispiel: Verfolgung der Abfragehistorie
Um die Herkunft einer bestimmten Tabelle zu sehen, können Sie die Abfragehistorie von Snowflake verwenden:
SELECT * FROM TABLE(INFORMATION_SCHEMA.QUERY_HISTORY_BY_SESSION()) WHERE QUERY_TEXT LIKE '%YOUR_TABLE_NAME%' ORDER BY START_TIME DESC;
Diese Abfrage gibt eine Liste aller Operationen zurück, die auf der angegebenen Tabelle durchgeführt wurden, was Ihnen hilft, ihre Herkunft nachzuvollziehen.
Snowflake Horizon: Verbesserung der Datenherkunft
Snowflake Horizon, eine Suite von Governance-Funktionen, verbessert die Fähigkeiten zur Datenherkunft weiter. Es bietet einen umfassenden Überblick über Datenressourcen und deren Beziehungen.
Schlüsselfunktionen von Snowflake Horizon für die Datenherkunft
- Automatisierte Herkunftsverfolgung: Horizon erfasst und visualisiert die Datenherkunft automatisch in Ihrem Snowflake-Konto.
- Datenbankübergreifende Herkunft: Es kann die Herkunft über verschiedene Datenbanken innerhalb Ihrer Snowflake-Umgebung verfolgen.
- Integration mit externen Tools: Horizon kann mit Drittanbieter-Datenkatalogen und Governance-Tools integriert werden.
Implementierung der Datenherkunft in Snowflake: Eine Schritt-für-Schritt-Anleitung
Gehen wir den Prozess der Einrichtung und Nutzung der Datenherkunft in Snowflake durch.
Schritt 1: Aktivieren der Konto-Nutzung
Stellen Sie zunächst sicher, dass die Konto-Nutzung in Ihrem Snowflake-Konto aktiviert ist. Diese Funktion bietet Zugriff auf Metadaten über Ihre Snowflake-Nutzung.
USE ROLE ACCOUNTADMIN; GRANT IMPORTED PRIVILEGES ON DATABASE SNOWFLAKE TO ROLE SYSADMIN;
Schritt 2: Erstellung einer Herkunfts-Datenbank
Erstellen Sie als Nächstes eine dedizierte Datenbank zur Speicherung von Herkunftsinformationen:
CREATE DATABASE DATA_LINEAGE; USE DATABASE DATA_LINEAGE;
Schritt 3: Einrichten von Herkunftstabellen
Erstellen Sie Tabellen zur Speicherung von Herkunftsinformationen:
CREATE TABLE DATA_SOURCES ( SOURCE_ID INT AUTOINCREMENT, SOURCE_NAME VARCHAR(255), SOURCE_TYPE VARCHAR(50), CREATED_AT TIMESTAMP_LTZ DEFAULT CURRENT_TIMESTAMP() ); CREATE TABLE DATA_TRANSFORMATIONS ( TRANSFORM_ID INT AUTOINCREMENT, SOURCE_ID INT, TARGET_ID INT, TRANSFORMATION_TYPE VARCHAR(50), QUERY_ID VARCHAR(50), CREATED_AT TIMESTAMP_LTZ DEFAULT CURRENT_TIMESTAMP(), FOREIGN KEY (SOURCE_ID) REFERENCES DATA_SOURCES(SOURCE_ID), FOREIGN KEY (TARGET_ID) REFERENCES DATA_SOURCES(SOURCE_ID) );
Schritt 4: Auffüllen der Herkunftsdaten
Verwenden Sie die Abfragehistorie von Snowflake, um Ihre Herkunftstabellen aufzufüllen:
INSERT INTO DATA_SOURCES (SOURCE_NAME, SOURCE_TYPE)
SELECT DISTINCT TABLE_NAME, 'TABLE'
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'PUBLIC';
INSERT INTO DATA_TRANSFORMATIONS (SOURCE_ID, TARGET_ID, TRANSFORMATION_TYPE, QUERY_ID)
SELECT
s.SOURCE_ID,
t.SOURCE_ID,
'INSERT',
qh.QUERY_ID
FROM
TABLE(INFORMATION_SCHEMA.QUERY_HISTORY()) qh
JOIN DATA_SOURCES s ON qh.QUERY_TEXT LIKE CONCAT('%FROM%', s.SOURCE_NAME, '%')
JOIN DATA_SOURCES t ON qh.QUERY_TEXT LIKE CONCAT('%INSERT INTO%', t.SOURCE_NAME, '%')
WHERE qh.QUERY_TYPE = 'INSERT';Schritt 5: Visualisierung der Datenherkunft
Obwohl Snowflake keine integrierten Visualisierungstools für die Datenherkunft bietet, können Sie die gesammelten Daten nutzen, um Ihre eigenen Visualisierungen zu erstellen oder sich mit Drittanbieter-Tools zu integrieren.
Bewährte Praktiken für die Datenherkunft in Snowflake
Um die Vorteile der Datenherkunft in Snowflake zu maximieren, sollten Sie diese bewährten Praktiken berücksichtigen:
- Konsistente Namenskonventionen: Verwenden Sie klare und konsistente Namen für Datenbanken, Schemata und Tabellen, um die Herkunftsverfolgung zu erleichtern.
- Regelmäßige Überprüfungen: Überprüfen und aktualisieren Sie regelmäßig Ihre Herkunftsinformationen, um deren Genauigkeit sicherzustellen.
- Nutzung der Snowflake-Funktionen: Nutzen Sie umfassend die nativen Funktionen von Snowflake wie Time Travel und Abfragehistorie für eine umfassende Herkunftsverfolgung.
- Integration mit Datenkatalogen: Integrieren Sie Snowflake mit Datenkatalog-Tools für ein verbessertes Metadaten-Management.
- Automatisierung der Herkunftsverfolgung: Implementieren Sie automatisierte Prozesse zur Aktualisierung der Herkunftsinformationen, sobald sich Datenflüsse ändern.
Herausforderungen und Lösungen bei der Implementierung der Datenherkunft
Obwohl die Datenherkunft zahlreiche Vorteile bietet, kann ihre Implementierung Herausforderungen mit sich bringen. Hier sind einige häufige Probleme und deren Lösungen:
Herausforderung 1: Komplexe Datenökosysteme
Viele Organisationen haben komplexe Datenökosysteme mit mehreren Quellen und Zielen.
Lösung: Beginnen Sie klein, indem Sie sich auf kritische Datenressourcen konzentrieren. Erweitern Sie Ihre Herkunftsverfolgung schrittweise, während Sie Ihre Prozesse verfeinern.
Herausforderung 2: Manuelle Verfolgung
Die manuelle Verfolgung der Datenherkunft kann zeitaufwendig und fehleranfällig sein.
Lösung: Nutzen Sie die automatisierten Funktionen von Snowflake und erwägen Sie die Investition in spezialisierte Datenherkunfts-Tools, die sich mit Snowflake integrieren.
Herausforderung 3: Aufrechterhaltung der Aktualität der Herkunft
Datenflüsse können sich schnell ändern, was es schwierig macht, die Herkunftsinformationen aktuell zu halten.
Lösung: Implementieren Sie automatisierte Auslöser in Snowflake, um Herkunftsinformationen zu aktualisieren, wann immer wesentliche Datenoperationen stattfinden.
Die Zukunft der Datenherkunft in Snowflake
Mit der Weiterentwicklung des Datenmanagements entwickelt sich auch die Rolle der Datenherkunft. Snowflake steht an vorderster Front dieser Entwicklung und verbessert kontinuierlich seine Fähigkeiten zur Datenherkunft.
Aufkommende Trends
- KI-gesteuerte Herkunft: Maschinelles Lernen könnte bald komplexe Herkunftsverfolgungsaufgaben automatisieren.
- Echtzeit-Herkunft: Da Unternehmen zunehmend Echtzeitanalysen durchführen, werden voraussichtlich Fortschritte in der Echtzeit-Herkunftserfassung zu sehen sein.
- Verbesserte Visualisierung: Es werden wahrscheinlich ausgefeiltere Visualisierungstools entstehen, die die Datenherkunft für Nicht-Techniker zugänglicher machen.
Fazit
Die Datenherkunft in Snowflake ist ein leistungsstarkes Werkzeug, das Organisationen hilft, ihre Datenressourcen effektiver zu verstehen und zu verwalten. Indem die Herkunft der Daten und deren Verwendung aufgezeigt werden, verbessert die Datenherkunft die Datenqualität, Compliance und Entscheidungsfindung.
Um die Datenherkunft in Snowflake einzurichten, müssen Sie einige Schritte befolgen. Diese Schritte umfassen die Aktivierung der Konto-Nutzung und das Einrichten von Herkunftsverfolgungssystemen. Obwohl Herausforderungen existieren, überwiegen die Vorteile bei weitem die Schwierigkeiten, insbesondere wenn bewährte Praktiken befolgt werden.
In einer Ära, in der Daten ein kritisches Unternehmensgut sind, ist das Beherrschen der Datenherkunft nicht mehr optional – es ist unerlässlich. Snowflake verbessert seine Fähigkeiten zur Datenherkunft.
Snowflake verbessert seine Fähigkeit, Datenherkunft zu verfolgen. Dies wird Organisationen helfen, ihre Daten besser zu nutzen. Infolgedessen können sie Innovationen vorantreiben und sich in einem datenfokussierten Umfeld einen Wettbewerbsvorteil verschaffen.
Für diejenigen, die nach fortschrittlichen Werkzeugen suchen, um die Herkunftsfähigkeiten von Snowflake zu ergänzen, sollten Sie die benutzerfreundlichen und flexiblen Lösungen von DataSunrise für Datenbanksicherheit und Compliance in Betracht ziehen. Besuchen Sie die DataSunrise-Website für eine Online-Demo und erfahren Sie, wie unsere Werkzeuge Ihre Datenmanagement-Strategie verbessern können.
Nächste
