
Datenverwaltungslösungen: Top-Trends & Lösungen

Datenverwaltung-Lösungen bieten einen umfassenden Ansatz zur Sammlung, Organisation, Sicherung und Nutzung der Datenbestände eines Unternehmens. Diese Lösungen helfen, Datensilos aufzubrechen. Sie verbessern auch die Datenqualität. Zusätzlich erleichtern sie den Zugriff auf Daten im gesamten Unternehmen.
Durch die Zusammenführung von Daten aus verschiedenen Quellen auf einer zentralisierten Plattform ermöglichen Datenverwaltungslösungen es Unternehmen, fundierte Entscheidungen zu treffen. Moderne Datenverwaltungssysteme beinhalten oft künstliche Intelligenz (KI) Fähigkeiten, um komplexe Datenherausforderungen zu bewältigen.
Die Bedeutung der Datenverwaltung
In der modernen Geschäftswelt sind Daten zu einer wichtigen Unternehmensressource geworden. Wenn Unternehmen Daten gut verwalten, können sie nützliche Informationen liefern, die helfen, das Marketing zu verbessern, Kosten zu senken und den Umsatz zu steigern. Ohne effektive Datenverwaltung praktiken können Daten jedoch schnell von einem Vermögenswert zu einer Belastung werden.
Inkonsistente und isolierte Daten behindern die Fähigkeit eines Unternehmens, durch Business Intelligence und Analyseinitiativen bedeutungsvolle Erkenntnisse zu gewinnen. Schlechte Datenqualität kann zu ungenauen Ergebnissen führen.
Daten nehmen ständig zu. Organisationen können in “Daten-Sümpfe” geraten – riesige Mengen an unorganisierten Daten, die schwer zu verwalten und zu schützen sind. Diese Daten-Sümpfe stellen Risiken für Organisationen dar, da sie schwer zu nutzen, zu kontrollieren und zu sichern sind.
Datenverwaltung ist wichtig, um strenge Datenschutzgesetze wie die DSGVO einzuhalten. Sie hilft Unternehmen, Vorschriften einzuhalten und sensible Informationen zu schützen.
Schlüsselkomponenten von Datenverwaltungslösungen
Datenbankverwaltungssysteme (DBMS)
Im Kern jeder Datenverwaltungslösung steht ein Datenbankverwaltungssystem (DBMS). Ein DBMS bietet die Tools und Schnittstellen, die erforderlich sind, um Datenbanken zu erstellen, zu sichern, zu aktualisieren und abzurufen. Es fungiert als Vermittler zwischen der Datenbank selbst und den Anwendungen oder Endbenutzern, die mit ihr interagieren.
Ein gut gestaltetes DBMS gewährleistet Datenkonsistenz, -integrität und -zugänglichkeit. Es besteht typischerweise aus drei Hauptkomponenten:
- Die DBMS-Software selbst, die es Benutzern ermöglicht, die Datenbank zu verwalten
- Die Datenbank-Engine, die für die Verarbeitung von Datenzugriff, Sperr- und Bearbeitungsanforderungen verantwortlich ist
- Das Datenbankschema, das die logische Struktur und Organisation der Daten definiert
Datenbankverwaltungssysteme verfügen über Tools, die bei Aufgaben wie der Verwaltung von Änderungen, der Datensicherung, der Leistungsverbesserung und der Prüfung helfen. Diese Tools wurden entwickelt, um es Benutzern zu erleichtern, verschiedene Aspekte der Datenbankverwaltung zu handhaben.
Die Verwaltung von Änderungen, die Datensicherung, die Leistungsverbesserung und die Prüfung sind alles wichtige Aufgaben bei der Wartung einer Datenbank. DBMSs bieten Tools, um diese Prozesse zu rationalisieren und effizienter zu gestalten.
Beispiel: Ein Einzelhandelsunternehmen implementiert ein DBMS, um Kundeninformationen, Produktkataloge und Verkaufsabwicklungen zu speichern und zu verwalten. Das DBMS stellt die Datenkonsistenz über verschiedene Anwendungen sicher, wie die E-Commerce-Website des Unternehmens, das Lagerverwaltungssystem und die Customer Relationship Management (CRM) Software.
Stammdatenmanagement (MDM)
Das Stammdatenmanagement (MDM) zielt darauf ab, eine einheitliche und zuverlässige Sicht auf die Hauptgeschäftseinheiten eines Unternehmens zu schaffen. Diese Einheiten umfassen Kunden, Produkte und Lieferanten. Diese Disziplin konzentriert sich darauf, sicherzustellen, dass die Daten über das gesamte Unternehmen hinweg genau und konsistent sind. Durch Vereinheitlichung und Harmonisierung von Daten aus mehreren Quellen stellt MDM die Datengenauigkeit, Konsistenz und Zuverlässigkeit über das gesamte Unternehmen hinweg sicher.
MDM-Prozesse etablieren und erzwingen DatenGovernance- Richtlinien, um Datenqualität zu gewährleisten und nahtlosen Datenaustausch zwischen Systemen zu ermöglichen. Dies ist besonders wichtig in komplexen IT-Umgebungen mit zahlreichen Anwendungen und Plattformen.
Beispiel: Ein globaler Hersteller führt eine MDM-Lösung ein, um eine einheitliche Sicht auf seine Lieferantendaten zu schaffen. Das Unternehmen kann seine Beschaffungsprozesse verbessern, indem es Lieferanteninformationen aus verschiedenen ERP-Systemen und Datenbanken sammelt. Dies kann helfen, Kosten zu senken und Lieferkettenrisiken zu vermindern.
Datenmodellierung
Die Datenmodellierung ist der Prozess der Erstellung visueller Darstellungen der Datenstrukturen und -beziehungen eines Unternehmens. Mit Symbolen und Text bieten Datenmodelle eine Blaupause für die Gestaltung von Datenbanken und die Ausrichtung von Datenressourcen an den Geschäftsanforderungen.
Gute Datenmodellierung hilft Teams, Datenbedürfnisse zu verstehen, Probleme frühzeitig zu finden und Daten effizient zu nutzen. Datenmodelle helfen Entwicklern, besseren Code zu schreiben, indem sie eine klare Übersicht über die verwendeten Daten bieten.
Beispiel: Ein Gesundheitsdienstleister beteiligt sich an der Datenmodellierung, um ein neues System für elektronische Patientenakten (EHR) zu entwerfen. Das Datenmodell stellt Patientendaten, medizinische Geschichte und Behandlungsinformationen visuell dar und hilft Entwicklern dabei, eine robuste und effiziente Datenbankstruktur zu erstellen.
Datenlager und Data Lakes
Datenlager und Data Lakes sind zwei gängige Arten von Datenrepositories, die in Datenverwaltungslösungen verwendet werden. Ein Datenlager ist ein zentralisiertes Repository, das Daten aus verschiedenen Systemen für Berichts- und Analysezwecke aggregiert. Datenlager speichern in der Regel strukturierte Daten in einem hierarchischen Format, das für schnelle Abfragen und Business Intelligence-Anwendungen optimiert ist.
Data Lakes hingegen speichern große Mengen an Rohdaten im nativen Format, bis sie für Analysen benötigt werden. Sie sind hervorragend geeignet, große Datenmengen zu speichern und zu verarbeiten, insbesondere für Aufgaben des maschinellen Lernens.
Zum Beispiel erstellt eine Bank ein Datenlager. Der Zweck besteht darin, Daten aus verschiedenen Systemen zusammenzuführen. Zu diesen Systemen gehören Kreditkartenabwicklung und Darlehensvergabe. Das Datenlager ermöglicht der Institution, umfassende Berichte zu erstellen und komplexe Analysen durchzuführen, um Cross-Selling-Möglichkeiten zu erkennen und Risiken zu verwalten.
Produktinformationsmanagement (PIM)
PIM-Lösungen helfen Organisationen, alle Produktdaten an einem zentralen Ort zu speichern. Diese Daten können mühelos über verschiedene Kanäle wie Websites, Apps und Kataloge geteilt werden. PIM-Tools sorgen für die Genauigkeit, Konsistenz und Vollständigkeit der Produktinformationen und verbessern das Gesamt kundenerlebnis.
Produktmanager und Marketing-Teams verwenden PIM-Lösungen, um Produktdaten aus verschiedenen Quellen zu sammeln und zu verbessern. Sie verwenden diese Lösungen auch, um Unstimmigkeiten in den Daten zu beheben. Darüber hinaus nutzen sie PIM-Lösungen, um aktuelle Produktinformationen mit Verkaufs- und Vertriebskanälen zu teilen.
Beispiel: Ein Modeeinzelhändler implementiert eine PIM-Lösung, um seinen umfangreichen Produktkatalog zu verwalten. Das PIM-System hilft Einzelhändlern, Produktdaten von Lieferanten zu sammeln. Es ermöglicht ihnen auch, Marketinginhalte hinzuzufügen. Einzelhändler können dann genaue Produktinformationen auf ihrer Website, App und in Ladenanzeigen teilen.
Die richtige Datenverwaltungslösung wählen
Bei der Auswahl einer Datenverwaltungslösung sollten Organisationen mehrere Schlüsselfaktoren berücksichtigen:
Datenbereinigungskapazitäten: Suchen Sie nach Lösungen, die robuste Datenprofilierungs-, Bereinigungs- und Qualitätsmanagement-Funktionen bieten, um Daten genau und konsistent zu halten.
Datenintegration: Wählen Sie eine Lösung, die Daten aus verschiedenen Quellen und Formaten, wie Datenbanken, Dateien und Altsystemen, problemlos zusammenführen kann.
Benutzerfreundliche Schnittstelle: Entscheiden Sie sich für eine Lösung mit einer benutzerfreundlichen Oberfläche. Diese Schnittstelle sollte sowohl für technische als auch für nicht-technische Benutzer toegankelijk sein und einen effizienten Datenzugriff und -umgang ermöglichen.
Skalierbarkeit: Stellen Sie sicher, dass die Lösung skalierbar ist, um den wachsenden Datenanforderungen Ihres Unternehmens gerecht zu werden und sich an sich ändernde Geschäftsanforderungen anzupassen.
Kosten: Berücksichtigen Sie die Gesamtkosten des Besitzes, einschließlich Lizenzgebühren, Implementierungskosten und laufender Wartungskosten.
Reales Beispiel einer Datenverwaltungslösung
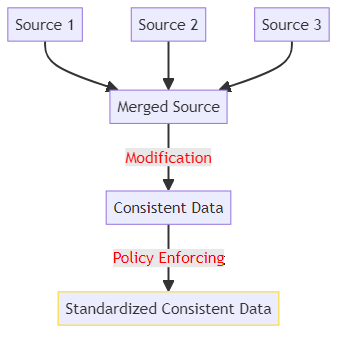
Sehen wir uns eine Programmierumsetzung des Stammdatenmanagements an.
Zuerst nehmen wir Daten aus verschiedenen Quellen, zum Beispiel CRM-Daten, E-Commerce-Daten und Supportsystem-Daten und teilen sie in DataFrames auf.
import pandas as pd
crm_data = {
'customer_id': [1, 2, 3],
'name': ['John Doe', 'Jane Smith', 'Alice Johnson'],
'email': ['john.doe@crm.com', 'jane.smith@crm.com', 'alice.johnson@crm.com'],
'phone': ['123-456-7890', '234-567-8901', '345-678-9012']
}
df_crm = pd.DataFrame(crm_data)
ecommerce_data = {
'customer_id': [1, 2, 4],
'name': ['John Doe', 'Jane Smith', 'Bob Brown'],
'email': ['john.doe@ecom.com', 'jane.smith@ecom.com', 'bob.brown@ecom.com'],
'address': ['123 Elm St', '456 Oak St', '789 Pine St']
}
df_ecommerce = pd.DataFrame(ecommerce_data)
support_data = {
'customer_id': [2, 3, 5],
'name': ['Jane Smith', 'Alice Johnson', 'Charlie Davis'],
'email': ['jane.smith@support.com', 'alice.johnson@support.com', 'charlie.davis@support.com'],
'issue_count': [5, 2, 1]
}
df_support = pd.DataFrame(support_data)
Als nächstes führen wir sie in einem einzigen DataFrame zusammen, um eine einheitliche Sicht auf die Daten zu erstellen.
merged_df = pd.merge(df_crm, df_ecommerce, on='customer_id', how='outer', suffixes=('_crm', '_ecom'))
merged_df = pd.merge(merged_df, df_support, on='customer_id', how='outer')
Um die Daten konsistent zu machen, müssen wir den zusammengeführten DataFrame anpassen:
merged_df.fillna('N/A', inplace=True)
merged_df['email'] = merged_df['email_crm'].combine_first(merged_df['email_ecom']).combine_first(merged_df['email'])
merged_df.drop(columns=['email_crm', 'email_ecom'], inplace=True)
Schließlich setzen wir eine Richtlinie in den resultierenden DataFrame durch. Beispielsweise eine Richtlinie für E-Mails, dass diese gültig sein müssen, indem sie ein ‘@’-Symbol enthalten und in Kleinbuchstaben geschrieben sind:
merged_df['email'] = merged_df['email'].str.lower()
valid_email_mask = merged_df['email'].str.contains('@')
merged_df = merged_df[valid_email_mask]
Das ist ein einfaches Beispiel für die Umsetzung des Stammdatenmanagements in einem Projekt.
Fazit
Datenverwaltungslösungen sind für Organisationen unerlässlich, die die Macht ihrer Datenressourcen nutzen möchten. Durch den Einsatz der richtigen Datenverwaltungstools und -praktiken können Unternehmen die Datenqualität und Effizienz verbessern.
