
Data Masking für Amazon Athena
Einführung
Im April 2024 berichtete Mandiant von einer erheblichen Bedrohung für Snowflake Data Warehouse-Benutzer. Der Angriff nutzte gestohlene Anmeldeinformationen, um auf wertvolle Daten zuzugreifen und sie zu kompromittieren. Dieser Vorfall unterstreicht die wachsende Bedeutung robuster Cloud-Sicherheitsmaßnahmen in der heutigen digitalen Landschaft. Data Masking hilft, sensible Informationen zu schützen, indem das Risiko einer Offenlegung in Szenarien wie diesem reduziert wird. Amazon Athena, ein leistungsstarker serverloser Abfrageservice, verarbeitet große Mengen an Daten. Lassen Sie uns die Grundlagen des Data Masking für Amazon Athena untersuchen und wie es Ihre sensiblen Daten schützen kann.
Verständnis von Data Masking in Amazon Athena
Data Masking ist eine Technik, die verwendet wird, um eine strukturell ähnliche, aber unechte Version der Daten einer Organisation zu erstellen. Dieser Prozess zielt darauf ab, sensible Informationen zu schützen und gleichzeitig die Daten für Test- oder Analysezwecke nutzbar zu halten.
Warum ist Data Masking wichtig?
- Compliance: Viele Vorschriften erfordern den Schutz von persönlichen und sensiblen Daten.
- Risikominimierung: Maskierte Daten minimieren das Risiko von Datenverletzungen.
- Testen und Entwicklung: Sie ermöglichen die sichere Nutzung produktionsähnlicher Daten.
Native Masking-Techniken in Amazon Athena
Amazon Athena bietet mehrere native Masking-Techniken unter Verwendung der SQL-Sprache, Ansichten, gespeicherte Prozeduren und AWS CLI. Lassen Sie uns diese Methoden erkunden.
SQL-Sprachfunktionen
Athena unterstützt verschiedene SQL-Funktionen, die für Data Masking verwendet werden können:
- SUBSTR(): Extrahiert einen Teil einer Zeichenkette.
- CONCAT(): Kombiniert Zeichenketten.
- REGEXP_REPLACE(): Ersetzt Text mithilfe von regulären Ausdrücken.
Ansichten für Data Masking
Ansichten können eine Abstraktionsebene bieten, die es ermöglicht, Daten zu maskieren, ohne die Originaltabelle zu ändern.
Beispiel:
CREATE OR REPLACE VIEW masked_users AS SELECT id, first_name, last_name, -- Maskiere E-Mail CONCAT(SUBSTR(email, 1, 3), '***', SUBSTR(email, -4)) AS email, -- Maskiere IP-Adresse REGEXP_REPLACE(ip_address, '(\d+\.\d+\.\d+\.)\d+', '$1***') AS ip_address FROM danielarticletable;
SELECT * FROM "danielarticledatabase"."masked_users" limit 10;
Die Ausgabe könnte wie folgt aussehen:
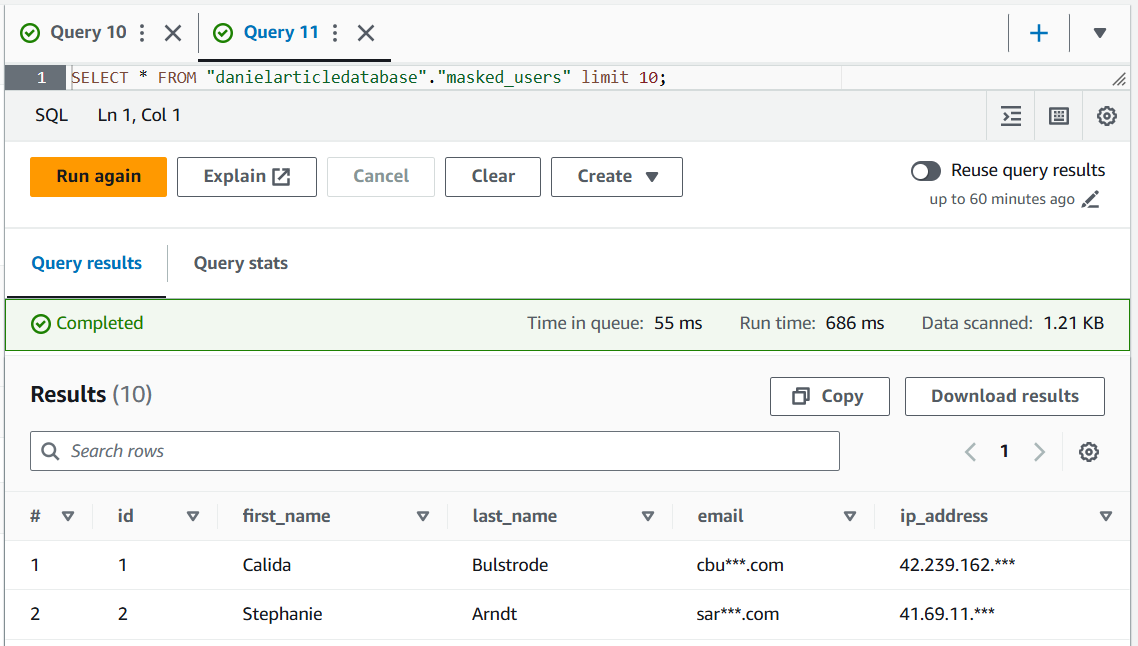
Gespeicherte Prozeduren und Zugriffskontrollen
Es ist wichtig zu verstehen, dass Amazon Athena keine traditionelle Datenbank ist, sondern ein Abfrageservice. Daher speichert Athena keine Prozeduren und verwaltet Benutzer nicht auf die gleiche Weise wie eine herkömmliche Datenbank. Aus diesem Grund haben wir alternative Masking-Ansätze untersucht, wie Ansichten und integrierte SQL-Funktionen.
Athenas Benutzerverwaltung und Zugriffskontrolle wird durch AWS Identity and Access Management (IAM) gehandhabt, was ein robustes, cloudnatives Sicherheitsmodell bietet. Dies bedeutet jedoch, dass Maskierungsregeln in der Regel auf Anwendungsebene implementiert werden müssen, wo die Zugriffskontrolle durchgesetzt wird.
Für Organisationen, die einen zentralisierteren und einheitlicheren Ansatz zur Zugriffskontrolle und Datenmaskierung suchen, können Lösungen wie DataSunrise hilfreich sein. Im Proxy-Modus verwendet, ermöglicht DataSunrise Datenbankadministratoren, konsistente Maskierungsregeln und Zugriffskontrollen über verschiedene Datenquellen hinweg zu implementieren, einschließlich Athena. Dieser Ansatz kann die Robustheit und Verwaltung von Datenschutzmaßnahmen erheblich verbessern, insbesondere in komplexen, multi-service Umgebungen.
AWS CLI für Data Masking
Die AWS Command Line Interface (CLI) bietet eine leistungsstarke Möglichkeit zur Automatisierung von Data Masking in Amazon Athena. Für ein praktisches Beispiel dieses Ansatzes, siehe unseren Artikel über dynamisches Maskieren, der zeigt, wie man effizient Data Protection implementiert und verwaltet, indem man CLI-Befehle verwendet.
Python und Boto3 für Native Maskierung in Athena
Schauen wir uns an, wie man Python und Boto3 verwendet, um eine Verbindung zu Athena herzustellen, Daten zu kopieren und E-Mails zu maskieren.
import boto3
import time
import pandas as pd
def wait_for_query_to_complete(athena_client, query_execution_id):
max_attempts = 50
sleep_time = 2
for attempt in range(max_attempts):
response = athena_client.get_query_execution(QueryExecutionId=query_execution_id)
state = response['QueryExecution']['Status']['State']
if state == 'SUCCEEDED':
return True
elif state in ['FAILED', 'CANCELLED']:
print(f"Query failed or was cancelled. Final state: {state}")
return False
time.sleep(sleep_time)
print("Query timed out")
return False
# Verbindung zu Athena herstellen
athena_client = boto3.client('athena')
# Abfrage ausführen
query = "SELECT * FROM danielArticleDatabase.danielArticleTable"
response = athena_client.start_query_execution(
QueryString=query,
ResultConfiguration={'OutputLocation': 's3://danielarticlebucket/AthenaArticleTableResults/'}
)
query_execution_id = response['QueryExecutionId']
# Warten, bis die Abfrage abgeschlossen ist
if wait_for_query_to_complete(athena_client, query_execution_id):
# Ergebnisse abrufen
result_response = athena_client.get_query_results(
QueryExecutionId=query_execution_id
)
# Spaltennamen extrahieren
columns = [col['Label'] for col in result_response['ResultSet']['ResultSetMetadata']['ColumnInfo']]
# Daten extrahieren
data = []
for row in result_response['ResultSet']['Rows'][1:]: # Kopfzeile überspringen
data.append([field.get('VarCharValue', '') for field in row['Data']])
# DataFrame erstellen
df = pd.DataFrame(data, columns=columns)
print("\nDataFrame head:")
print(df.head())
# E-Mails maskieren (angenommen, 'email' Spalte existiert)
if 'email' in df.columns:
df['email'] = df['email'].apply(lambda x: x[:3] + '***' + x[-4:] if x else x)
# Maskierte Daten speichern
df.to_csv('danielarticletable_masked.csv', index=False)
print("Maskierte Daten wurden in danielarticletable_masked.csv gespeichert")
else:
print("Fehler beim Abrufen der Abfrageergebnisse")Dieses Skript ruft Daten von Athena ab, maskiert die E-Mail-Spalte und speichert das Ergebnis in der Datei danielarticletable_masked.csv. Die Ausgabedatei sieht wie folgt aus:
id,first_name,last_name,email,gender,ip_address 1,Calida,Bulstrode,cbu***.com,Female,42.239.162.240 2,Stephanie,Arndt,sar***.com,Female,41.69.11.161 …
Die AWS-Anmeldeinformationen wurden in der Python-Umgebung gesetzt. Die Ausgabe des Maskierungsskripts für Jupyter Notebook in unserem Fall war:
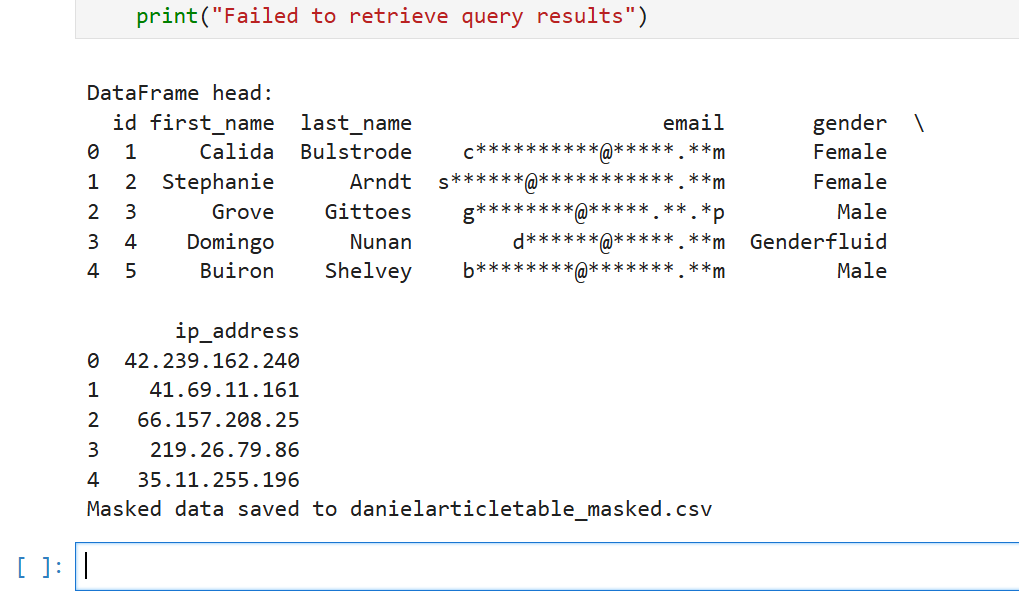
Maskierung mit DataSunrise
Während native Maskierung nützlich ist, bietet die DataSunrise Maskierung mehr Flexibilität. Sie bietet sowohl dynamische als auch statische Maskierungsfähigkeiten für Amazon Athena.
Erstellen einer DataSunrise dynamischen Maskierungsregel
- Gehe zu „Maskierung und dynamische Maskierung“ im Hauptmenü.
- Erstelle eine neue Maskierungsregel.
- Wähle die „Amazon Athena“-Instanz als Regelinstanz.
- Konfiguriere die Maskierungsregel, indem du angibst, welche Spalten maskiert werden sollen.
- Speichere die Regel. Sie wird automatisch beim Speichern aktiv.
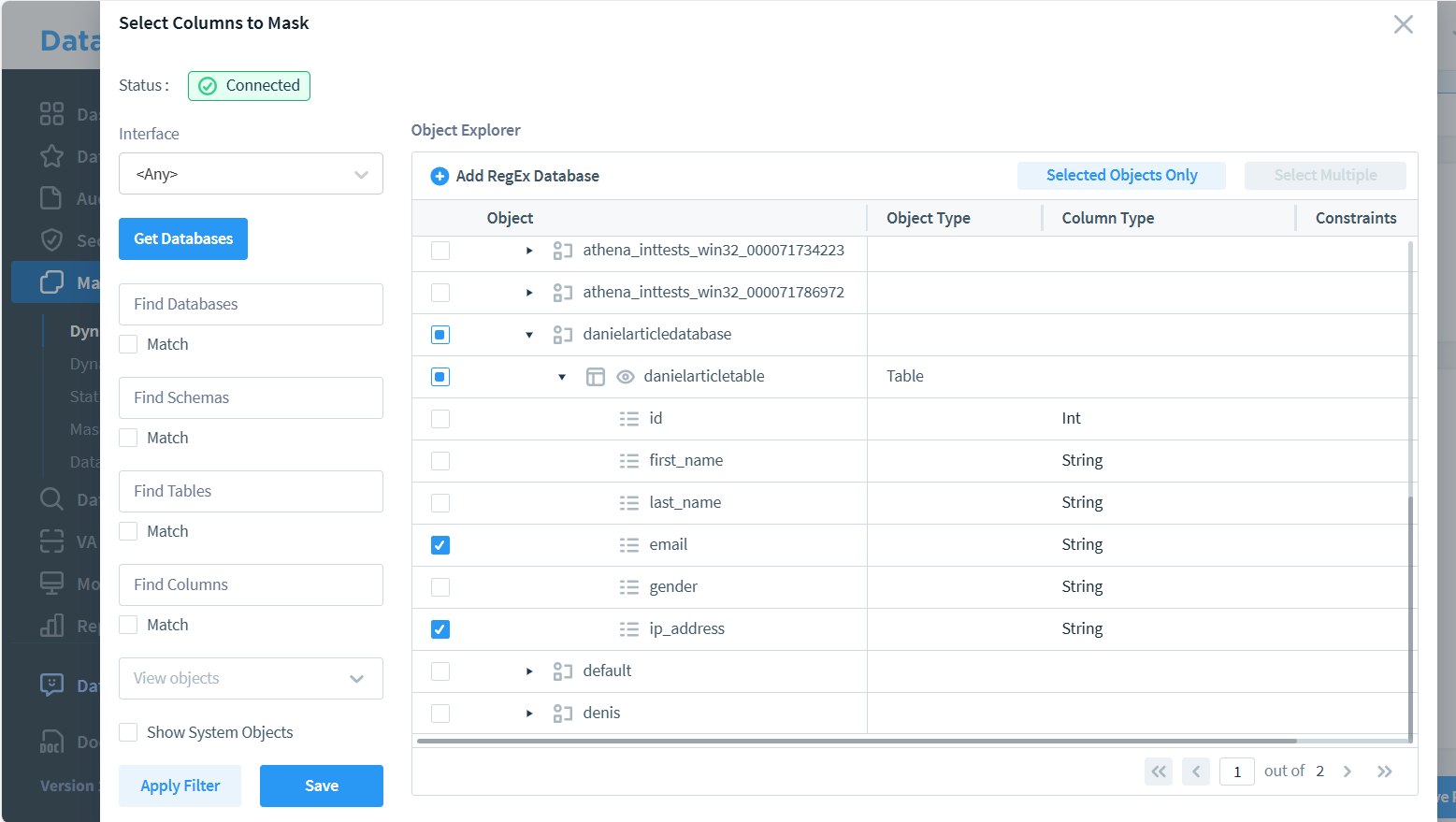
Auf dem Bild oben sind zwei Spalten zur Maskierung markiert. Das Auswählen mehrerer Spalten in einer einzigen Regel kann jedoch die verfügbaren Maskierungsmethoden einschränken. Wenn du unterschiedliche Maskierungstechniken für jedes Feld benötigst, erstelle separate Regeln für jede Spalte. Dieser Ansatz bietet eine größere Flexibilität bei der Auswahl geeigneter Maskierungsmethoden für einzelne Datentypen.
Vorteile von DataSunrise für zentrale Maskierung
- Einheitliche Kontrolle: Verwalte Maskierungsregeln über mehrere Datenquellen hinweg.
- Echtzeitschutz: Wende Maskierung dynamisch an, wenn Abfragen ausgeführt werden.
- Flexible Regeln: Erstelle komplexe Maskierungsmuster basierend auf Benutzerrollen oder Datenempfindlichkeit.
- Prüfpfad: Verfolge alle Datenzugriffs- und Maskierungsaktivitäten.
Statistische Datenmaskierung von Athena mit DataSunrise
Amazon Athena ist ein Abfrageservice und keine traditionelle Datenbank, was bedeutet, dass direkte statische Maskierung in DataSunrise für Athena nicht unterstützt wird. Es gibt jedoch effektive Workarounds. Für detaillierte Informationen zu diesen alternativen Ansätzen sieh dir bitte unseren speziellen Artikel zu Athena-statistischen Datenmaskierungsstrategien an.
Best Practices für Data Masking in Amazon Athena
- Identifiziere sensible Daten: Führe regelmäßig Datenüberprüfungen durch, um sensible Informationen zu identifizieren.
- Verwende mehrere Techniken: Kombiniere native Athena-Funktionen mit Tools von Drittanbietern wie DataSunrise.
- Gründlich testen: Stelle sicher, dass Maskierung die Anwendungsfunktionalität nicht beeinträchtigt.
- Regelmäßig aktualisieren: Überprüfe und aktualisiere Maskierungsregeln, wenn sich Daten ändern.
- Überwachen und Prüfen: Behalte im Auge, wer wann auf maskierte Daten zugreift.
Fazit
Data Masking für Amazon Athena ist ein wichtiger Aspekt der Datensicherheit. Durch die Nutzung nativer Athena-Funktionen und leistungsstarker Tools wie DataSunrise können Organisationen sensible Informationen schützen und dennoch die Nützlichkeit der Daten beibehalten. Denken Sie daran, dass effektives Data Masking ein fortlaufender Prozess ist, der Wachsamkeit und regelmäßige Updates erfordert.
Da Datenverletzungen häufiger werden, ist die Investition in robuste Data Masking-Techniken nicht nur eine bewährte Methode, sondern eine Notwendigkeit für verantwortungsvolles Datenmanagement.
DataSunrise bietet flexible und fortschrittliche Tools für die Datensicherheit, einschließlich umfassender Prüf- und Compliance-Werkzeuge. Für eine praktische Erfahrung mit unserer leistungsstarken Datenschutz-Suite laden wir Sie ein, unsere Website zu besuchen und unsere Online-Demo zu vereinbaren.
Nächste
