
Datenworkflow optimieren
Für datengetriebene Unternehmen ist eine effiziente Datenverarbeitung entscheidend, um Einblicke zu gewinnen und fundierte Entscheidungen zu treffen. Wenn jedoch mit sensiblen Informationen umgegangen wird, ist es wichtig, Geschwindigkeit und Effizienz mit Datenschutz und Sicherheit abzuwägen. Dieser Artikel befasst sich mit Möglichkeiten, Datenworkflows mithilfe von ETL- und ELT-Methoden zu vereinfachen und gleichzeitig den Datenschutz zu gewährleisten.
Verstehen von Ansätzen zur Optimierung der Datenverarbeitung
Bevor wir uns mit ETL und ELT befassen, lassen Sie uns gängige Ansätze zur Optimierung der Datenverarbeitung untersuchen:
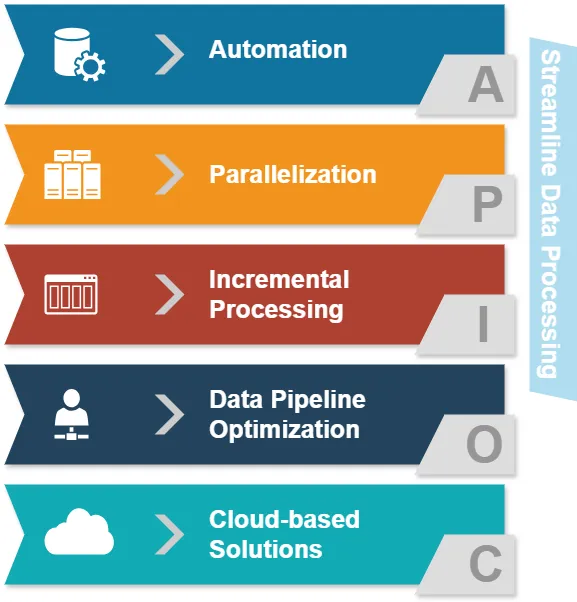
- Automatisierung: Reduzierung manueller Eingriffe bei Datenverarbeitungsaufgaben.
- Parallelisierung: Gleichzeitige Verarbeitung mehrerer Datenströme.
- Inkrementelle Verarbeitung: Aktualisierung nur geänderter Daten statt ganzer Datensätze.
- Optimierung der Datenpipeline: Sicherstellung eines reibungslosen Datenflusses zwischen verschiedenen Stufen.
- Cloud-basierte Lösungen: Nutzung skalierbarer Infrastruktur für die Datenverarbeitung.
Diese Ansätze zielen darauf ab, die Effizienz der Datenverarbeitung zu verbessern. Nun wollen wir erkunden, wie ETL und ELT in diesem Kontext passen.
ETL vs. ELT: Ein Vergleich
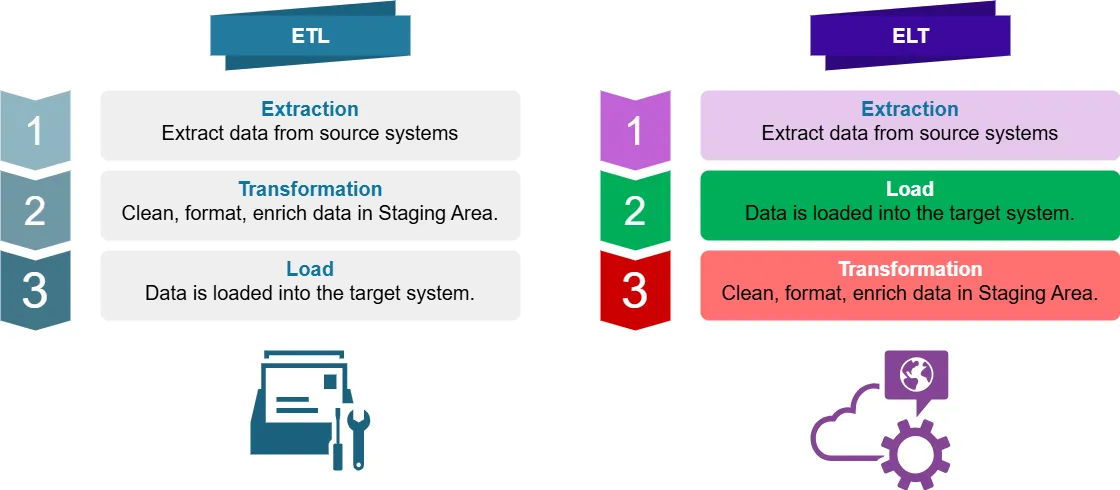
Was ist ETL?
ETL steht für Extract, Transform, Load. Es ist ein traditioneller Datenintegrationsprozess, bei dem Daten:
- Aus Datenquellsystemen extrahiert werden
- In einem Staging-Bereich transformiert (bereinigt, formatiert, angereichert) werden
- In das Zielsystem (z. B. Data Warehouse) geladen werden
Was ist ELT?
ELT steht für Extract, Load, Transform. Es ist ein moderner Ansatz, bei dem Daten:
- Aus Quellsystemen extrahiert werden
- Direkt in das Zielsystem geladen werden
- Innerhalb des Zielsystems transformiert werden
Wesentliche Unterschiede in der optimalen Datenverarbeitung
Für Business Intelligence liegt der Hauptunterschied zwischen ETL und ELT darin, wann und wo die Datenumwandlung stattfindet. Dies beeinflusst die optimale Datenverarbeitung in mehreren Aspekten:
- Verarbeitungskapazität: ETL nutzt separate Transformationsserver, während ELT die Verarbeitungskapazität des Zielsystems nutzt.
- Datenflexibilität: ELT bewahrt Rohdaten, was agilere Transformationen ermöglicht.
- Verarbeitungszeit: ELT kann bei großen Datensätzen schneller sein, da parallele Verarbeitung möglich ist.
- Datenschutz: ETL kann mehr Kontrolle über sensible Daten während der Transformation bieten.
Wo werden ETL und ELT angewendet?
ETL wird häufig verwendet in:
- Traditionellem Data Warehousing
- Systemen mit begrenzter Speicher- oder Verarbeitungskapazität
- Szenarien, die komplexe Datenumwandlung vor dem Laden erfordern
ELT wird oft bevorzugt für:
- Cloud-basierte Data Warehouses
- Big Data Umgebungen
- Echtzeit- oder nahezu Echtzeit-Datenverarbeitung
- Situationen, in denen Rohdatenaufbewahrung entscheidend ist
Optimierung von Datenworkflows: Python und Pandas Beispiele
Schauen wir uns einige Beispiele für optimierte und nicht optimierte Datenverarbeitung mithilfe von Python und Pandas an.
Nicht optimierter Ansatz
import pandas as pd
# Daten aus CSV lesen
df = pd.read_csv('large_dataset.csv')
# Mehrere Transformationen durchführen
df['new_column'] = df['column_a'] + df['column_b']
df = df[df['category'] == 'important']
df['date'] = pd.to_datetime(df['date'])
# Transformierte Daten in neue CSV schreiben
df.to_csv('transformed_data.csv', index=False)
Dieser Ansatz lädt den gesamten Datensatz in den Speicher, führt Transformationen durch und schreibt dann das Ergebnis. Für große Datensätze kann dies speicherintensiv und langsam sein.
Optimierter Ansatz
import pandas as pd
# Chunks verwenden, um große Datensätze zu verarbeiten
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
# Transformationen auf jedem Chunk durchführen
chunk['new_column'] = chunk['column_a'] + chunk['column_b']
chunk = chunk[chunk['category'] == 'important']
chunk['date'] = pd.to_datetime(chunk['date'])
# Transformierten Chunk zur Ausgabedatei hinzufügen
chunk.to_csv('transformed_data.csv', mode='a', header=False, index=False)
Dieser optimierte Ansatz verarbeitet Daten in Chunks, reduziert die Speichernutzung und ermöglicht parallele Verarbeitung. Er ist effizienter für große Datensätze und kann leicht in ETL- oder ELT-Workflows integriert werden.
Datenschutz bei ETL und ELT
Beim Umgang mit sensiblen Daten ist Datenschutz von größter Bedeutung. Sowohl ETL als auch ELT können so gestaltet werden, dass sie sensible Informationen sicher verarbeiten:
ETL und Datenschutz
- Datenmaskierung: Techniken zur Maskierung werden während der Transformationsphase angewendet.
- Verschlüsselung: Verschlüsseln Sie sensible Daten, bevor sie ins Zielsystem geladen werden.
- Zugriffskontrolle: Implementieren Sie strenge Zugriffskontrollen auf dem Transformationsserver.
Beispiel für Datenmaskierung in ETL:
import pandas as pd
def mask_sensitive_data(df):
df['email'] = df['email'].apply(lambda x: x.split('@')[0][:3] + '***@' + x.split('@')[1])
df['phone'] = df['phone'].apply(lambda x: '***-***-' + x[-4:])
return df
# ETL-Prozess
df = pd.read_csv('source_data.csv')
df = mask_sensitive_data(df)
# Weitere Transformationen...
df.to_csv('masked_data.csv', index=False)
ELT und Datenschutz
- Spaltenbasierte Verschlüsselung: Verschlüsseln Sie sensible Spalten vor dem Laden.
- Dynamische Datenmaskierung: Anwenden von Maskierungsregeln im Zielsystem.
- Rollenbasierte Zugriffskontrolle: Implementieren Sie feingranulare Zugriffspolicen im Data Warehouse.
Beispiel für spaltenbasierte Verschlüsselung in ELT:
import pandas as pd
from cryptography.fernet import Fernet
def encrypt_column(df, column_name, key):
f = Fernet(key)
df[column_name] = df[column_name].apply(lambda x: f.encrypt(x.encode()).decode())
return df
# Generieren des Verschlüsselungsschlüssels (in der Praxis sollte dieser Schlüssel sicher gespeichert und verwaltet werden)
key = Fernet.generate_key()
# ELT-Prozess
df = pd.read_csv('source_data.csv')
df = encrypt_column(df, 'sensitive_column', key)
# Laden der Daten ins Zielsystem
df.to_sql('target_table', engine) # Annahme: 'engine' ist Ihre Datenbankverbindung
# Transformation der Daten im Zielsystem
Optimierung der Datenworkflows für sensible Daten
Um Datenworkflows zu optimieren und gleichzeitig den Datenschutz zu wahren, sollten Sie diese Best Practices berücksichtigen:
- Datenklassifizierung: Identifizieren und kategorisieren Sie sensible Daten frühzeitig im Prozess.
- Minimierung der Datenbewegung: Reduzieren Sie die Anzahl der Übertragungen sensibler Daten zwischen Systemen.
- Sichere Protokolle verwenden: Anwenden von Verschlüsselung für Daten in Bewegung und ruhenden Daten.
- Implementierung von Daten-Governance: Etablieren Sie klare Richtlinien für den Umgang mit Daten und den Zugriff darauf.
- Regelmäßige Audits: Führen Sie regelmäßige Überprüfungen Ihrer Datenverarbeitungsworkflows durch.
Fazit
Es ist wichtig, Datenworkflows zu optimieren. Wir müssen auch sicherstellen, dass sensible Informationen durch starke Datenschutzmaßnahmen geschützt werden. Beide Ansätze, ETL und ELT, haben ihre eigenen Vorteile und Organisationen können sie optimieren, um sowohl Leistung als auch Sicherheit zu gewährleisten.
Dieser Artikel spricht über Möglichkeiten, wie Unternehmen sichere Datenworkflows schaffen können. Diese Workflows schützen sensible Informationen und ermöglichen wertvolle Einblicke. Unternehmen können diese Strategien und Best Practices nutzen, um dieses Ziel zu erreichen.
Denken Sie daran, dass die Entscheidung zwischen ETL und ELT von Ihrem spezifischen Anwendungsfall, Datenvolumen und Datenschutzanforderungen abhängt. Es ist wichtig, Ihre Datenverarbeitungsstrategien regelmäßig zu überprüfen und zu aktualisieren, um sicherzustellen, dass sie den sich entwickelnden Bedürfnissen Ihres Unternehmens entsprechen und den Datenschutzgesetzen entsprechen.
Für benutzerfreundliche Werkzeuge zur Verbesserung der Datensicherheit und Compliance in Ihren Datenprozessen, schauen Sie sich die Optionen von DataSunrise an. Besuchen Sie unsere Website unter DataSunrise, um eine Demo zu sehen und zu erfahren, wie wir Ihre Datenverarbeitung verbessern können. Wir legen großen Wert darauf, Ihre Daten sicher und geschützt zu halten.
