
Dynamisches Datenmaskieren in PostgreSQL: Echtzeit-Schutz für sensible Informationen

PostgreSQL, ein leistungsfähiges Open-Source-Datenbanksystem, bietet verschiedene Sicherheitsfunktionen zum Schutz sensibler Daten. Eine solche Funktion ist das dynamische Datenmaskieren. Diese Technik hilft Organisationen, vertrauliche Informationen zu schützen, ohne die Originaldaten zu verändern. Lassen Sie uns erkunden, wie dynamisches Datenmaskieren in PostgreSQL funktioniert und warum es für den Datenschutz entscheidend ist.
Was ist dynamisches Datenmaskieren?
Dynamisches Datenmaskieren ist eine Sicherheitstechnik, die sensible Daten in Echtzeit verbirgt. Es transformiert die Daten, wenn sie aus der Datenbank abgerufen werden. Die Originalinformationen bleiben intakt, aber Benutzer sehen nur maskierte oder veränderte Versionen. Dieser Ansatz stellt sicher, dass sensible Daten geschützt werden, während autorisierte Benutzer weiterhin auf die notwendigen Informationen zugreifen können.
Implementierung von dynamischem Datenmaskieren in PostgreSQL
PostgreSQL implementiert dynamisches Datenmaskieren durch Ansichten und Row-Level-Sicherheitsrichtlinien. Diese Funktionen erlauben es Datenbankadministratoren, zu steuern, welche Daten Benutzer basierend auf ihren Rollen und Berechtigungen sehen können.
Um dynamisches Datenmaskieren in PostgreSQL nativ zu implementieren, können Sie Ansichten erstellen, die sensible Spalten verändern. Hier ist ein Beispiel:
CREATE VIEW masked_customers AS SELECT id, CASE WHEN current_user = 'admin' THEN full_name ELSE 'REDACTED' END AS full_name, CASE WHEN current_user = 'admin' THEN email ELSE LEFT(email, 2) || '****' || RIGHT(email, 4) END AS email, city, state FROM customers;
Diese Ansicht maskiert die Spalten full_name und email für Nicht-Admin-Benutzer. Admins können die Originaldaten sehen, während andere Benutzer nur redaktierte oder teilweise maskierte Informationen sehen.
Dies kann jedoch bei großen Datenmengen kompliziert sein. Um den Prozess zu vereinfachen, empfehlen wir die Nutzung von Drittanbieter-Lösungen. Um DataSunrise zu betreiben, müssen Sie zuerst eine Instanz der erforderlichen Datenbank erstellen.
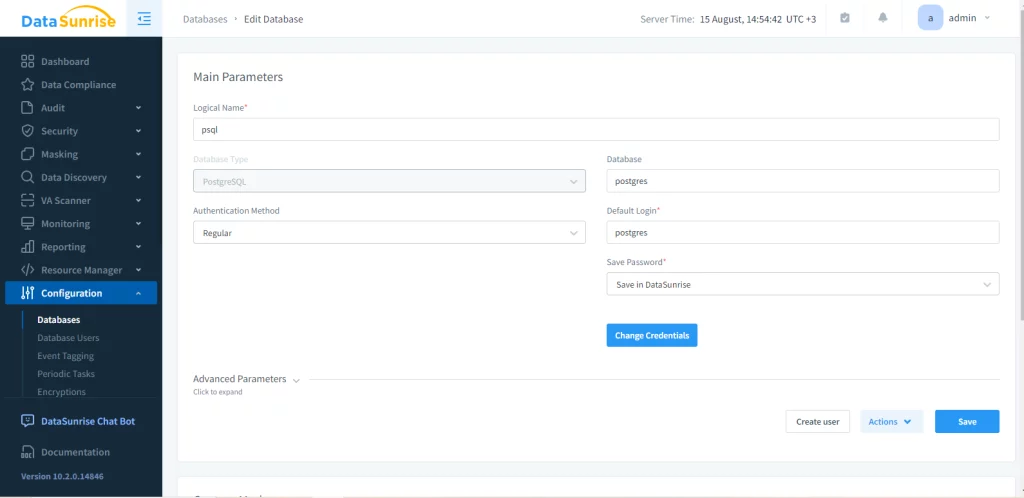
Nun können Sie verschiedene Arten von Regeln für den Proxy der Datenbankinstanz erstellen. Für dynamisches Datenmaskieren gehen wir zum entsprechenden Menü und fügen eine neue Regel hinzu. In diesem Beispiel maskieren wir die Spalte ‘first_name’ der Tabelle ‘gauss_types1’ in der Datenbank ‘Test’.
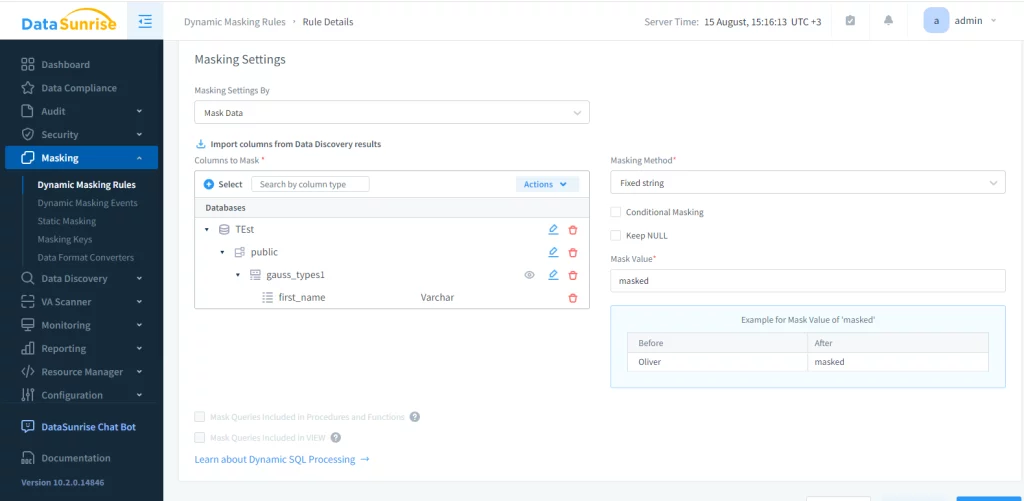
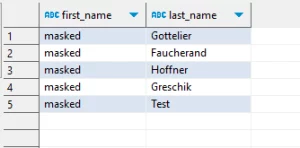
Nach dem Anwenden der Regel und Ausführen der Abfrage erhalten wir folgendes Ergebnis:
Vorteile und Herausforderungen
Dynamisches Datenmaskieren in PostgreSQL bietet mehrere Vorteile. Es verbessert den Datenschutz, indem es unbefugten Zugriff auf sensible Informationen verhindert. Dies hilft, das Risiko von Datenverletzungen und Insider-Bedrohungen zu reduzieren. Es hilft auch bei der Einhaltung strenger Datenschutzbestimmungen, indem es den Zugriff auf sensible Daten einschränkt.
Für die Entwicklung und Tests ermöglicht dynamisches Datenmaskieren den Teams, mit realistischen Datensätzen zu arbeiten, ohne sensible Informationen zu offenbaren. Benutzer können benutzerdefinierte Datenmaskierungsregeln basierend auf Benutzerrollen, Datentypen und spezifischen Anforderungen erstellen. Dies gibt Administratoren Flexibilität beim Schutz von Daten.
Die Implementierung von dynamischem Datenmaskieren bringt jedoch Herausforderungen mit sich. Es kann die Abfrageleistung beeinflussen, insbesondere bei komplexen Maskierungsregeln oder großen Datensätzen. Die Aufrechterhaltung der Datenintegrität ist von entscheidender Bedeutung und erfordert eine sorgfältige Planung und Prüfung der Maskierungsregeln. Schulungen der Benutzer sind ebenfalls wichtig, da diese verstehen müssen, wie dynamisches Datenmaskieren funktioniert und warum es notwendig ist.
Best Practices
Für eine effektive Implementierung von dynamischem Datenmaskieren in PostgreSQL sollten Sie diese Best Practices berücksichtigen:
- Identifizieren Sie sensible Datenelemente, die Schutz benötigen.
- Verwenden Sie rollenbasierte Zugriffskontrollen (RBAC), um Benutzerberechtigungen effektiv zu verwalten.
- Überprüfen und aktualisieren Sie regelmäßig die Maskierungsregeln, um sicherzustellen, dass sie effektiv und relevant bleiben.
- Implementieren Sie Protokollierungs- und Auditierungsmechanismen, um zu verfolgen, wer wann auf maskierte Daten zugreift.
- Testen Sie Maskierungsregeln und -richtlinien gründlich, bevor Sie sie in der Produktion einsetzen.
- Erwägen Sie die Verwendung von Verschlüsselung für extrem sensible Informationen zusätzlich zum dynamischen Datenmaskieren.
Durch die Befolgung dieser Praktiken können Organisationen eine robuste Datenschutzstrategie entwickeln, die Sicherheit und Benutzerfreundlichkeit in Einklang bringt.
Fazit
Dynamisches Datenmaskieren in PostgreSQL ist ein leistungsstarkes Werkzeug zum Schutz sensibler Informationen. Es ermöglicht Organisationen, Datensicherheit mit Benutzerfreundlichkeit in Einklang zu bringen und dafür zu sorgen, dass Benutzer die benötigten Informationen erhalten, während vertrauliche Daten geschützt bleiben. PostgreSQL-Benutzer können einen starken Datenschutzplan erstellen, indem sie dynamisches Datenmaskieren mit anderen Sicherheitsmaßnahmen kombinieren. Dieser Plan folgt Regeln und reduziert das Risiko von Datenlecks.
Da der Datenschutz immer wichtiger wird, wird dynamisches Datenmaskieren weiterhin eine entscheidende Rolle für PostgreSQL-Benutzer spielen. Organisationen, die PostgreSQL nutzen, sollten diese Funktion in ihren Sicherheitsplan aufnehmen, um sensible Daten zu schützen und die Einhaltung der Datenschutzgesetze zu gewährleisten.
