
Verständnis von Informationstypen: Dateninspirierte Sicherheit in DataSunrise
Einführung
DataSunrise bietet dateninspirierte Sicherheit und damit einzigartige und leistungsfähige Funktionen für die schnelle Datenermittlung bei jeder Datenanfrage für eine bestimmte Datenquelle. Obwohl dieser Ansatz einen gewissen Overhead bei der Ausführungszeit erzeugt, bietet er einen äußerst flexiblen Datenbankschutz.
Informationstypen wurden erstmals in DataSunrise mit der Funktion zur Erkennung sensibler Daten eingeführt, die Datenbanken und Speichersysteme wie S3 nach sensiblen Daten durchsucht.
Informationstypen bieten Funktionalitäten über die grundlegende Datenermittlung hinaus. Sie ermöglichen die Echtzeit-Erkennung von Datentypen und können automatisch Schutz- oder Überwachungsregeln durch dateninspirierte Sicherheit bei jeder Datenbankabfrage auslösen. Außerdem erleichtern sie das Labeling von Audit-Trails, was es einfacher macht, spezifische Datenzugriffsereignisse sowohl in Transaktions-Trails als auch in Logdateien nachzuverfolgen.
Entdecken von Informationstypen
Datenmerkmale müssen in einer Entität zur Analyse gespeichert werden. Manchmal haben diese Daten eine strikte Struktur mit Spaltennamen, Tabellennamen und Typen. Andernfalls können sie als JSON, CSV-Dateien, Klartext oder sogar als gescannte Dokumentbilder erscheinen. DataSunrise ermöglicht die Suche nach sensiblen Daten in all diesen Objekten.
Dies führt zu flexiblen Beschreibungen von Informationstypen. Zum Beispiel kann E-Mail-Daten mehrere Eigenschaften haben:
- Spaltenname enthält “email”
- Tabellenname enthält “email”
- Daten entsprechen dem regulären Ausdruck “.*@.*“
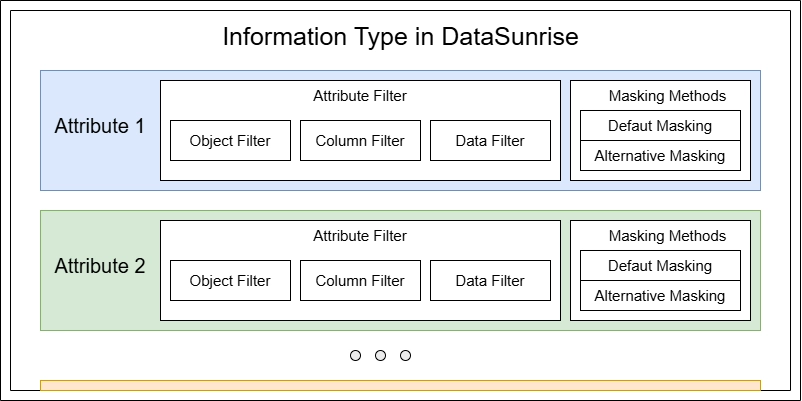
Um als E-Mail-Information klassifiziert zu werden, müssen die Daten mehrere Anforderungen erfüllen. Dies führt zu einer weiteren wichtigen DataSunrise-Entität, die als Informationsattribut bezeichnet wird. Ein Informationstyp ist im Wesentlichen eine Sammlung von Attributen, die die Daten erfüllen müssen, um als spezifischer Typ zu gelten.
Bei der Suche nach sensiblen Daten in einer einfachen Textdatei ohne Spalten und Tabellen kann der Attributsatz anders sein. Beispielsweise könnte ein Klartext-E-Mail-Informationstyp nur Regex-Abstimmung erfordern, ohne dass zusätzliche Attribute benötigt werden.
Verfügbare Informationstypen in DataSunrise
DataSunrise enthält zahlreiche integrierte Informationstypen, die jeweils mit populären Sicherheitsstandards (GDPR, HIPAA, SOX und andere) verbunden sind. Obwohl diese Zuordnung für benutzerdefinierte Typen nicht obligatorisch ist, hilft sie, Aktivitäten zu verfolgen und Nutzungsdaten für Compliance-Audits zu sammeln.
Benutzer können benutzerdefinierte Informationstypen erstellen, die von einfach bis komplex reichen. Der integrierte E-Mail-Typ beinhaltet beispielsweise Attribute, die auf Spaltennamen und komplexe Mustermatchings für E-Mail-Inhalte passen.
DataSunrise bietet mehrere Datumsinformationstypen, um verschiedene Datumsformatierungskonventionen zu berücksichtigen. Es ist erwähnenswert, dass verschiedene Informationstypen verwendet werden können, um dieselbe Art von Daten zu identifizieren, wenn sie in verschiedenen Formaten gespeichert sind.
Für eine einfachere Zuordnung von Informationstypen empfehlen wir die Erstellung benutzerdefinierter Typen mit flexibleren Attributen. In unserer Praxis erstellen die meisten Benutzer einen benutzerdefinierten E-Mail-Datentyp, der nur erfordert, dass der Dateninhalt einem grundlegenden regex-Pattern entspricht, wie “@.*”.
Benutzerdefinierte Typen ermöglichen es Ihnen, sowohl neue Informationstypen zur Erkennung hinzuzufügen als auch zu steuern, wie strikt diese Informationstypen mit Ihren Datenmustern übereinstimmen. Sie können Informationstypen erstellen, die mehrere Attribute erfordern, von denen jedes Spaltennamen und Datenmuster enthält. Alternativ können Sie einfachere Informationstypen mit nur einem einzigen Attribut erstellen, das nur das Datenmuster überprüft.
Wie man einen benutzerdefinierten Informationstyp erstellt
Schritt 1 – Neuen Informationstyp hinzufügen
- Navigieren Sie zu Datenentdeckung – Informationstypen
- Drücken Sie die Schaltfläche “+ Typ hinzufügen” und geben Sie einen geeigneten Namen für Ihren benutzerdefinierten Informationstyp ein.
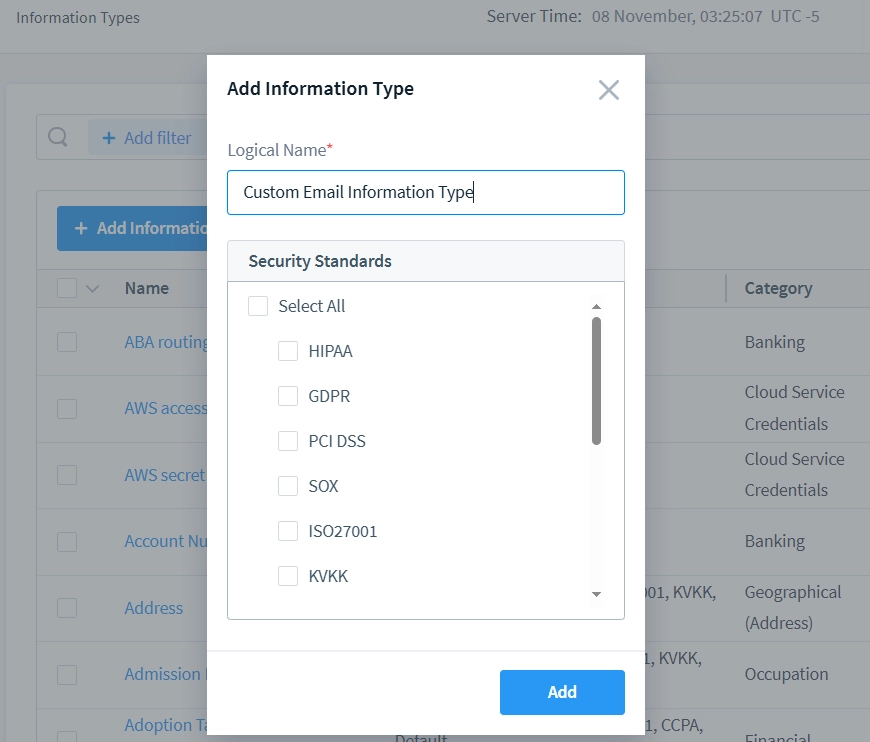
- Nachdem Sie den Informationstyp-Namen festgelegt haben, wird er in der Liste auf der Seite “Informationstypen” angezeigt. Klicken Sie auf den neuen Informationstyp, um seine internen Parameter und Attribute zu bearbeiten. Nehmen wir das Beispiel “Benutzerdefinierter E-Mail-Informationstyp”.
Die Seite zum Bearbeiten von Informationstypen enthält drei Hauptunterabschnitte:
- Im Abschnitt Attribute können Sie die tatsächlichen Abstimmungsparameter für den Informationstyp festlegen. Sie können ein oder mehrere Attribute erstellen, und jedes Attribut kann Anforderungen für das Datenbankobjekt, den Spaltennamen und das Datenmuster enthalten. Der Informationstyp stimmt, wenn ein einziges Attribut übereinstimmt. Für eingeschlossene Attribute müssen alle Bedingungen (Objekt-, Spaltennamens- und Datenmuster) erfüllt sein, falls angegeben.
- Im Abschnitt Sicherheitsstandards können Sie den Informationstyp mit einem oder mehreren Sicherheitsstandards verknüpfen. Dies wird von der Compliance-Funktion während der Erkennungsaufgaben verwendet, da die Compliance-Funktion auf Sicherheitsstandards basiert.
- Der Abschnitt Tags verwalten hilft Ihnen, Protokolleinträge in Protokollen oder Berichten leicht zu finden. Zu diesem Zweck können Sie benutzerdefinierte Tags erstellen.
Schritt 2 – Attribut zum Informationstyp hinzufügen
- Erstellen wir ein einfaches Attribut für den “Benutzerdefinierten E-Mail-Informationstyp”. Drücken Sie die Schaltfläche “+ Attribut hinzufügen”, um zu beginnen. Wir werden es so einstellen, dass Daten, die einem einfachen E-Mail-Muster folgen, übereinstimmen: “.*@.*“
Hinweis: Dieses Muster ist viel zu einfach und wird ungültige Einträge wie “@.” oder “!!!@…” fälschlicherweise übereinstimmen. In Produktionsumgebungen sollte ein robusteres E-Mail-Validierungsmuster verwendet werden.
Der neue Attributdialog erscheint mit zwei Tafeln: “Attribut” auf der linken und “Testen” auf der rechten Seite. Das Attributfeld wird verwendet, um die Einstellungen für Ihr neues Attribut zu konfigurieren, während das Testfeld es Ihnen ermöglicht, diese Einstellungen zu überprüfen, während Sie sie erstellen.
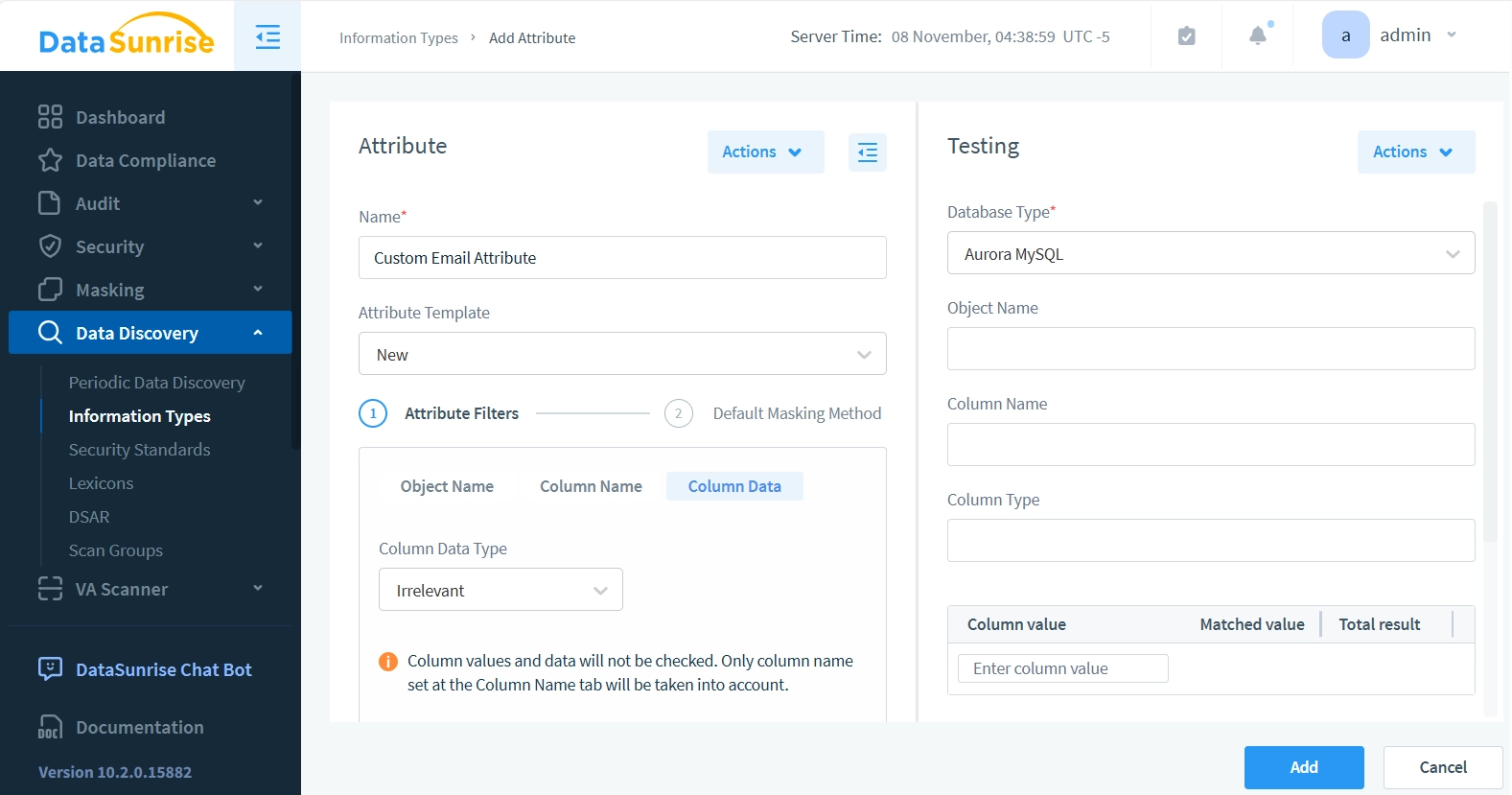
- Geben Sie im Feld “Attribut” im Namensfeld “Benutzerdefiniertes E-Mail-Attribut” ein. Für das Attributemplate behalten wir die Standardeinstellung “Neu” bei, da wir noch keine anderen Vorlagen haben.
Im nächsten Schritt konzentrieren wir uns auf zwei Schlüsselbereiche: Attributfilter und Standard-Maskierungsmethode.
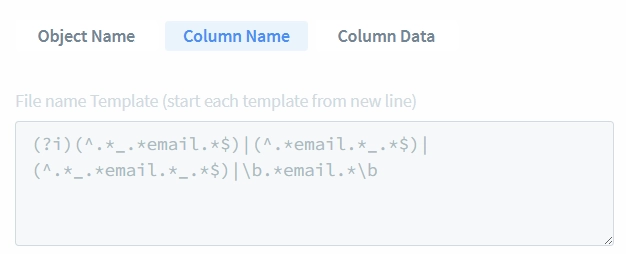
- Für Attributfilter lassen Sie die Felder Objektname und Spaltenname unverändert. Klicken Sie nur auf die Spaltendatenoption. Das bedeutet, dass unser Attribut Datenbank-Objektnamen und Spaltennamensmuster ignoriert und sich ausschließlich auf die Überprüfung konzentriert, ob die Datenzeichenfolge ein E-Mail-ähnliches Muster enthält (mit einem @ Zeichen).
- Setzen Sie den Spaltendatentyp auf “Nur Zeichenfolgen” und die Suchmethode auf “Unstrukturierter Text”.
- Geben Sie “.*@.*” in das Feld “Vorlage für Spalteninhalte (beginnen Sie jede Vorlage mit einer neuen Zeile)” ein. Bevor Sie das Attribut speichern oder in Regeln oder Aufgaben verwenden, können wir testen, ob es E-Mail-Muster korrekt übereinstimmt.
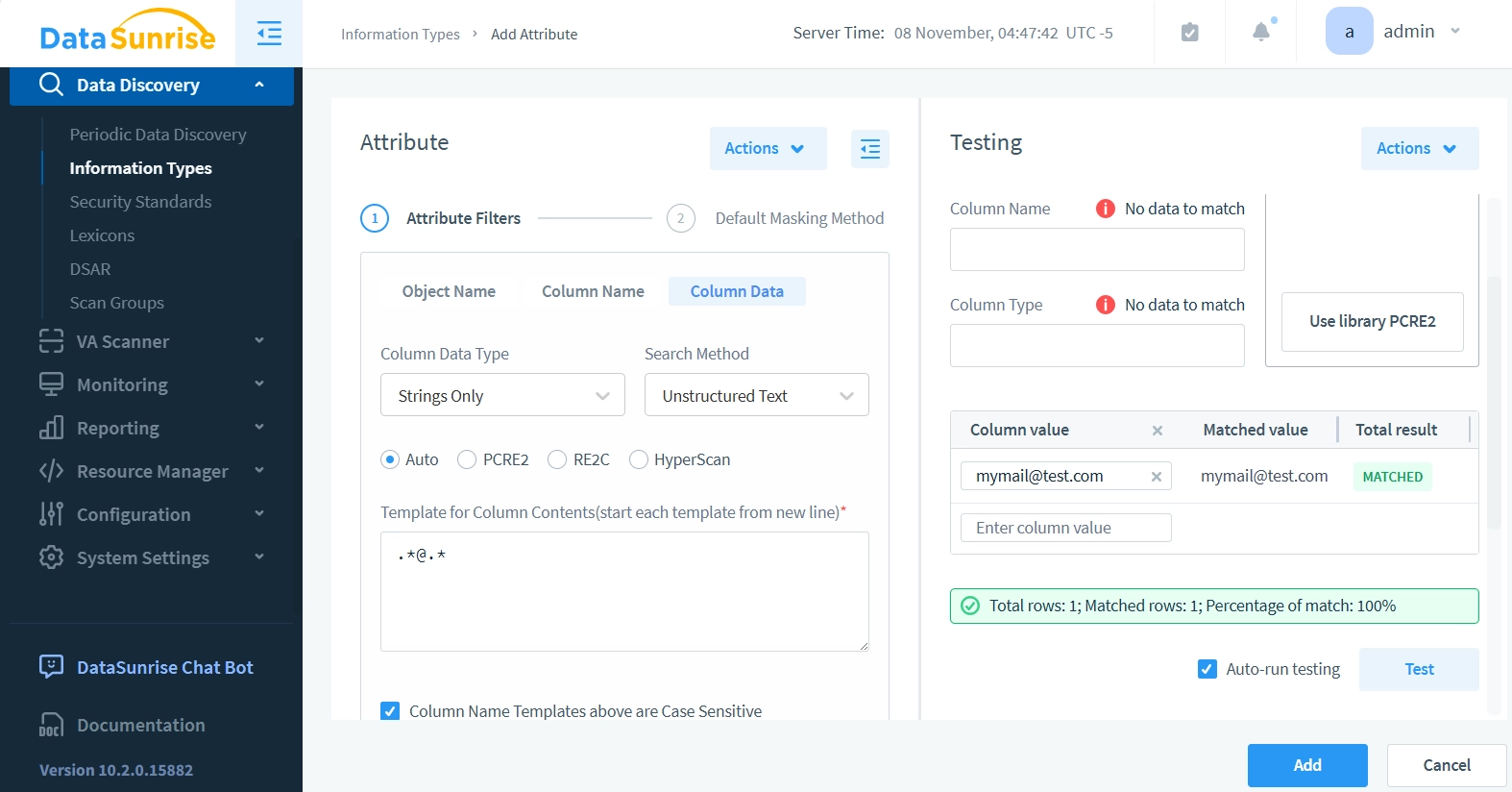
- Nun verwenden wir das Testfeld auf der rechten Seite. Lassen Sie alle vorherigen Felder unverändert und geben Sie eine Beispiel-E-Mail, wie “mymail@test.com”, in das Feld Spaltenwert ein. Klicken Sie auf die Schaltfläche Test – die Ergebnisse sollten zeigen, dass das Attribut erfolgreich E-Mails in den Spaltendaten erkennt.
Schritt 3 – Einstellungen zur Attributmaskierung
- Klicken Sie auf ‘2. Standard-Maskierungsmethode’, um mit der Einrichtung der Maskierungsmethode fortzufahren. Dadurch wird das Attributfeld auf die Maskierungseinrichtung umgeschaltet.
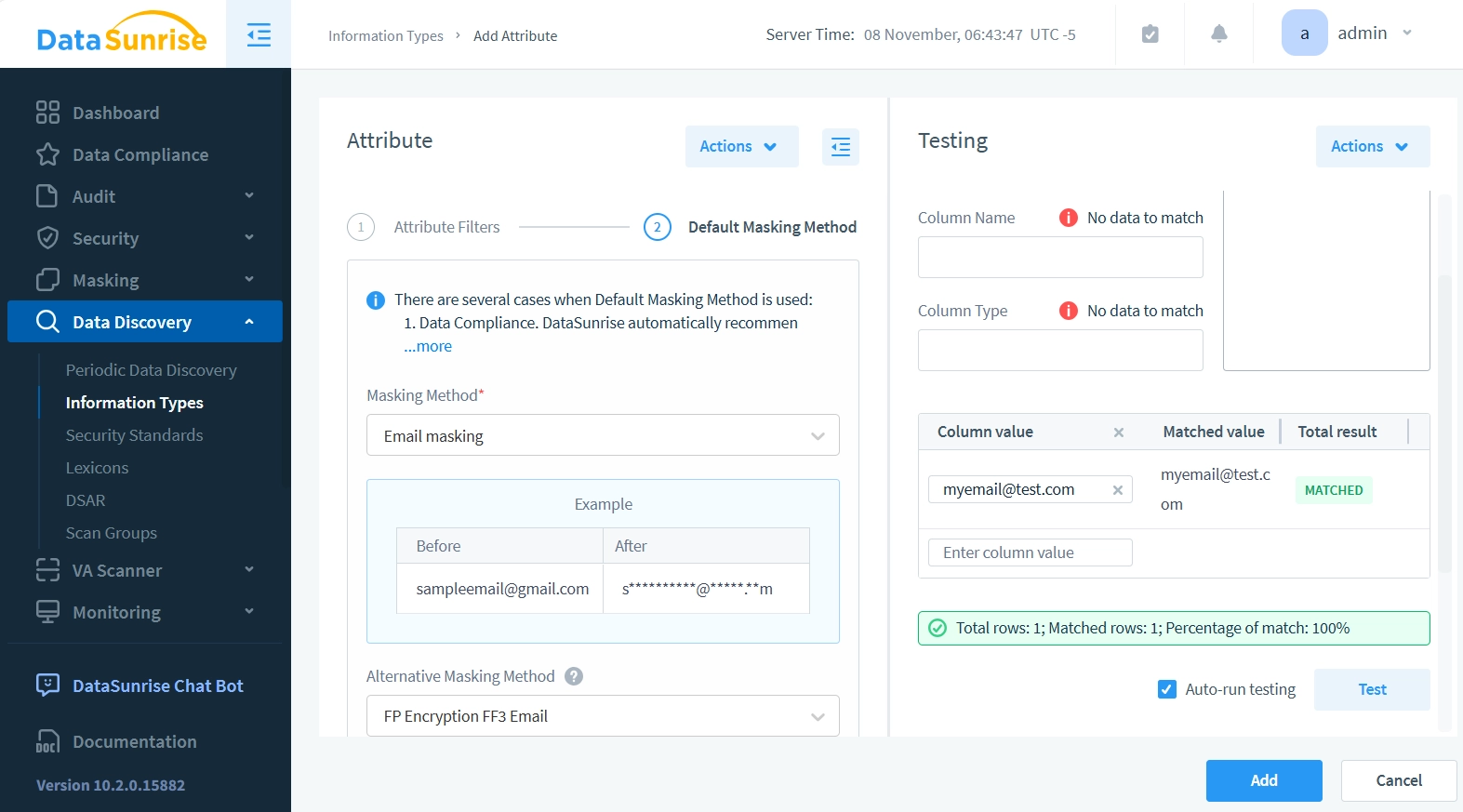
- Setzen Sie das Dropdown-Menü der Maskierungsmethode auf E-Mail-Maskierung. Die Standard-Maskierungsmethode wird im Data Compliance-Tool, bei dateninspiriertem dynamischen Maskieren und bei statischem Maskieren verwendet. DataSunrise wendet diese Maskierungsmethode an, wenn keine Schlüsselbeschränkungen vorhanden sind, die die Integrität der maskierten Datenbank gewährleisten müssen.
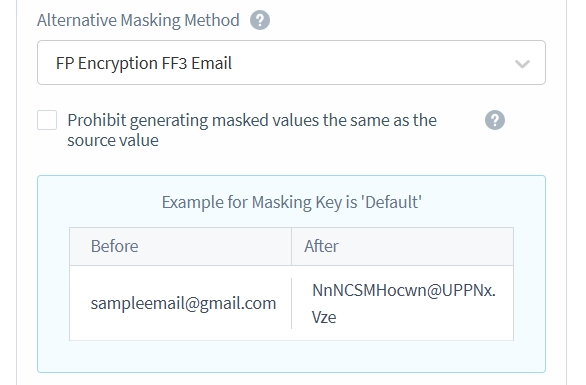
- Setzen Sie das Dropdown-Menü für die alternative Maskierungsmethode auf FP Encryption FF3 Email. Alternative Maskierungsmethoden sind notwendig, um die referenzielle Integrität der Tabelle aufrechtzuerhalten. Sie können Fremdschlüssel nicht einfach mit zufälligen Zeichenfolgen maskieren, da dies die Referenzen zwischen den Tabellen brechen würde. Die Maskierung muss sicherstellen, dass Referenzen aus anderen Tabellen auch nach der Anwendung der Maskierung noch auf die korrekten Zeilen zeigen. Ebenso müssen Primärschlüssel auch nach der Maskierung eindeutig bleiben und ihre referenziellen Beziehungen zu anderen Tabellen beibehalten.
Im folgenden Beispiel zum statischen Maskieren werden die Spalten ’email’ und ‘contact_email’ aufgrund von Schlüsselbeschränkungen mit unterschiedlichen Methoden maskiert. Zum Beispiel wird die E-Mail-Adresse von John Doe, die eine Fremdschlüsselbeschränkung hat, als ‘DmEP.YRV@qGpLQem.bwO’ maskiert. In der Zwischenzeit wird sein contact_email, das keine Beschränkungen hat, mit der Standard-Methode maskiert, was als ‘j***.***@.**m’ erscheint.
Wichtig: Während diese Einrichtung mit traditionellen Datenbanken kompatibel ist, folgen einige Speichersysteme wie Amazon S3 und unstrukturierte Textdateien nicht typischen Datenbankorganisationen mit Spalten und Objekten. Für diese Speichertypen sollten Sie beim Verwenden von Objekt- und Spaltennamensfiltern vorsichtig sein, da diese die ordnungsgemäße Datenabstimmung verhindern können.
- Klicken Sie auf die Schaltfläche ‘Hinzufügen’, um das Attribut mit dem Informationstyp zu verknüpfen.
Testen von Informationstypen mit alternativen Maskierungsmethoden
Das folgende Beispiel zeigt, wie DataSunrise sowohl Standard- als auch alternative Maskierungsmethoden implementiert. Lassen Sie uns dies durch die Erstellung von Beispieltabellen untersuchen:
-- Erstellen der E-Mail-Tabelle (Elterntabelle)
CREATE TABLE emails (
email VARCHAR(50) PRIMARY KEY,
email_type VARCHAR(20),
created_date DATE
);
-- Erstellen der Mitarbeiter-Tabelle mit zusätzlicher contact_email
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(30),
last_name VARCHAR(30),
email VARCHAR(50),
contact_email VARCHAR(50),
hire_date DATE,
FOREIGN KEY (email) REFERENCES emails(email)
);
-- Einfügen von Daten in die E-Mail-Tabelle
INSERT INTO emails VALUES
('john.doe@company.com', 'corporate', '2023-01-15'),
('sarah.smith@company.com', 'corporate', '2023-02-20'),
…
('peter.jones@company.com', 'corporate', '2023-05-01');
-- Einfügen von Daten in die Mitarbeiter-Tabelle mit Kontakt-E-Mails
INSERT INTO employees VALUES
(1, 'John', 'Doe', 'john.doe@company.com', 'john.personal@gmail.com', '2023-01-16'),
(2, 'Sarah', 'Smith', 'sarah.smith@company.com', 'sarah.smith@outlook.com', '2023-02-21'),
…
(5, 'Peter', 'Jones', 'peter.jones@company.com', 'peterjones123@hotmail.com', '2023-05-02');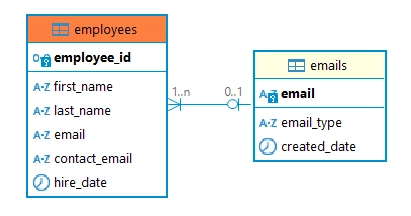
Statisches Maskieren mit Standard- und alternativer Maskierung
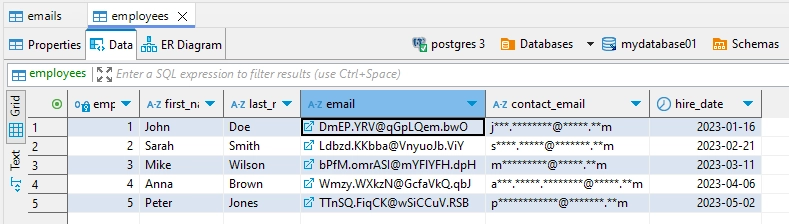
Statische Maskierung ermöglicht es Benutzern, sensible Daten, die während der Erkennung identifiziert wurden, automatisch zu maskieren. Dieser automatisierte Ansatz, bekannt als Automatikmodus, bestimmt, welche Quelltabellen übertragen und welche Spalten maskiert werden sollen. Das System implementiert zwei verschiedene Maskierungsstrategien: eine für Standarddatenfelder und eine andere für relationale Datenelemente (wie Fremd- und Primärschlüssel). Dieser duale Ansatz gewährleistet die Datenkonsistenz unter gleichzeitiger Beibehaltung der referenziellen Integrität über Datenbankbeziehungen hinweg.
Während der Ausführung der statischen Maskierungsaufgabe auf der Tabelle ’employees’ wurden unterschiedliche Maskierungsmethoden auf E-Mail-Felder angewendet. Die eingeschränkte ’email’-Spalte, die als Fremdschlüssel dient, behielt ihr Format durch Formatbewahrende Maskierung bei. In der Zwischenzeit unterzog sich die uneingeschränkte ‘contact_email’-Spalte einer einfachen Zeichenmaskierung, bei der nur der mittlere Teil der E-Mail-Adressen verschleiert wurde.
Fazit
Dieser Artikel bot eine eingehende Erkundung der DataSunrise-Informationstypen. Wir haben Sie durch die Hauptschritte zur Erstellung von Informationstypen und deren Attributdefinitionen geführt. Informationstypen werden vor allem in der Datenermittlung verwendet, um sensible Daten basierend auf spezifischen, durch ihre Attribute definierten Eigenschaften zu identifizieren. Zusätzlich werden diese Informationstypen während des Datenzugriffs durch eine Funktion genannt “dateninspirierte Sicherheit” aktiv genutzt, die Datenmaskierung, Blockierung und Ereignisprotokoll-Tagging ermöglicht.
Wir haben auch Anwendungsfälle für die Standard-Maskierung untersucht und diskutiert, wie alternative Maskierungsmethoden angewendet werden können, wenn statische Maskierungsaufgaben auf Schlüsselbeschränkungen in der maskierten Datenbank stoßen.
