
Junk-Daten

In der heutigen datengesteuerten Welt spielt die Qualität der Informationen eine entscheidende Rolle bei Entscheidungsprozessen. Organisationen kämpfen jedoch oft mit der Herausforderung von Junk-Daten, weil nicht alle Daten gut genug sind. Dieser Artikel untersucht die Verarbeitung solcher Daten und deren Auswirkungen auf Datensätze. Wir bieten auch Lösungen an, um die Genauigkeit der Daten zu erhalten.
Was sind Junk-Daten?
Junk-Daten beziehen sich auf Informationen, die innerhalb eines Datensatzes ungenau, unvollständig, irrelevant oder beschädigt sind. Sie können auch menschliche Fehler enthalten. Diese Daten können verschiedene Formen annehmen, wie zum Beispiel:
- Doppelte Einträge
- Veraltete Informationen
- Formatierungsfehler
- Unvollständige Aufzeichnungen
- Unrelevante Datenpunkte
Diese Daten können die Datenanalyse weniger effektiv machen und zu falschen Erkenntnissen führen, wenn sie nicht behoben werden.
Die Auswirkungen von Junk-Daten auf die Datenanalyse
Junk-Daten können weitreichende Konsequenzen auf den Datenanalyseprozess haben. Hier sind einige wichtige Wege, wie Junk-Daten die Integrität und Nützlichkeit Ihrer Daten beeinflussen können:
1. Verzerrte Ergebnisse
Wenn irreführende Daten in einem Datensatz vorhanden sind, können sie zu ungenauen statistischen Berechnungen und falsch dargestellten Trends führen. Diese Verzerrung der Ergebnisse kann dazu führen, dass Organisationen schlechte Entscheidungen auf der Grundlage fehlerhafter Informationen treffen.
2. Reduzierte Effizienz
Die Verarbeitung und Analyse von Daten verbraucht wertvolle Zeit und Ressourcen. Datenanalysten können stundenlang mit der Bereinigung und Sortierung irrelevanter Informationen verbringen, was die Gesamtproduktivität verringert.
3. Erhöhte Kosten
Das Vorhandensein von doppelten Daten erfordert oft zusätzlichen Speicherplatz und Verarbeitungsleistung. Dies kann zu erhöhten Infrastrukturkosten für Organisationen führen, die mit großen Datenmengen umgehen.
4. Verlust an Glaubwürdigkeit
Erkenntnisse, die aus fehlerhaften Daten gewonnen werden, können das Vertrauen in die Entscheidungsprozesse einer Organisation untergraben. Dieser Vertrauensverlust kann langfristige Auswirkungen auf interne Abläufe und externe Beziehungen haben.
Datenklassifikationsansätze mit Open-Source-Tools
Um Junk-Daten effektiv zu verwalten, können Organisationen verschiedene Datenklassifikationsansätze implementieren. Hier sind einige Open-Source-Tools, die bei diesem Prozess helfen können:
1. Apache NiFi
Apache NiFi ist ein leistungsstarkes Datenintegrations- und Verarbeitungstool, das bei der Klassifizierung und Weiterleitung von Daten auf Basis vordefinierter Regeln helfen kann. Es bietet eine benutzerfreundliche Oberfläche zum Erstellen von Datenflüssen und Anwenden von Filtern zur Identifizierung und Trennung von Junk-Daten.
Beispiel:
Apache NiFi Datenklassifikations-Flow
- Erstellen Sie eine neue Prozessgruppe
- Fügen Sie einen GetFile-Prozessor hinzu, um Daten zu importieren
- Verbinden Sie sich mit einem RouteOnAttribute-Prozessor
- Definieren Sie Regeln zur Klassifizierung von Daten (z. B. ${filename:contains(‘junk’)})
- Leiten Sie klassifizierte Daten zu den entsprechenden Zielen weiter
Ergebnis: Diese Konfiguration klassifiziert eingehende Dateien automatisch basierend auf ihren Attributen und leitet sie entsprechend weiter. Es hilft, potenziell fehlerhafte Daten zur weiteren Verarbeitung oder Entfernung zu isolieren.
2. OpenRefine
OpenRefine (ehemals Google Refine) ist ein vielseitiges Tool zur Bereinigung und Transformation unordentlicher Daten. Es bietet Funktionen zur Erkennung und Entfernung doppelter Einträge, zur Standardisierung von Formaten und zum Clustern ähnlicher Datenpunkte.
Beispiel:
OpenRefine Duplikaterkennung
- Laden Sie Ihren Datensatz in OpenRefine
- Wählen Sie die Spalte, die potenzielle Duplikate enthält
- Wählen Sie “Facet” > “Customized facets” > “Duplicates facet”
- Überprüfen und zusammenführen oder entfernen Sie doppelte Einträge
Ergebnis: Dieser Prozess identifiziert doppelte Einträge in Ihrem Datensatz, sodass Sie redundante Informationen bereinigen können.
3. Talend Open Studio
Talend Open Studio (veraltet) ist eine Open-Source-Datenintegrationsplattform, die leistungsstarke Werkzeuge zur Datenqualität und -profilierung enthält. Es kann helfen, Muster und Anomalien in Ihren Daten zu identifizieren.
Beispiel:
Talend Datenqualitätsanalyse
- Erstellen Sie einen neuen Job in Talend Open Studio
- Ziehen Sie eine tFileInputDelimited-Komponente, um Ihre Daten zu lesen
- Verbinden Sie diese mit einer tDataProfiler-Komponente
- Konfigurieren Sie den Profiler zur Analyse bestimmter Spalten
- Führen Sie den Job aus und überprüfen Sie den Datenqualitätsbericht
Ergebnis: Dieser Job generiert einen umfassenden Bericht über die Qualität Ihrer Daten und hebt potenzielle Problemstellen wie fehlende Werte, Ausreißer und Formatinkonsistenzen hervor.
Vermeidung der Entfernung oder des Missbrauchs sensibler Daten
Beim Umgang mit schlechten Daten ist es wichtig sicherzustellen, dass sensible Informationen nicht versehentlich entfernt oder missbraucht werden. Hier sind einige Best Practices, die beachtet werden sollten:
1. Implementierung von Datenmaskierung
Verwenden Sie Datenmaskierungstechniken, um sensible Informationen zu verbergen und gleichzeitig die Gesamtstruktur der Daten zu erhalten. Dadurch wird eine Analyse ermöglicht, ohne vertrauliche Details offenzulegen.
2. Etablierung von Zugangskontrollen
Implementieren Sie strikte Zugangskontrollen, um sicherzustellen, dass nur autorisiertes Personal während der Junk-Daten-Verarbeitung auf sensible Daten zugreifen und diese manipulieren kann.
3. Führung von Audit-Trails
Führen Sie detaillierte Protokolle über alle Datenverarbeitungsaktivitäten, einschließlich wer auf die Daten zugegriffen hat, welche Änderungen vorgenommen wurden und wann. Dies hilft, möglichen Missbrauch oder versehentliche Entfernung wichtiger Informationen nachzuverfolgen.
4. Verwendung von Datenklassifikations-Tags
Wenden Sie Klassifikations-Tags auf Ihre Daten an und kennzeichnen Sie sensible Informationen eindeutig. Dies hilft bei der Identifizierung, welche Daten während des Junk-Daten-Entfernungsprozesses eine besondere Behandlung erfordern.
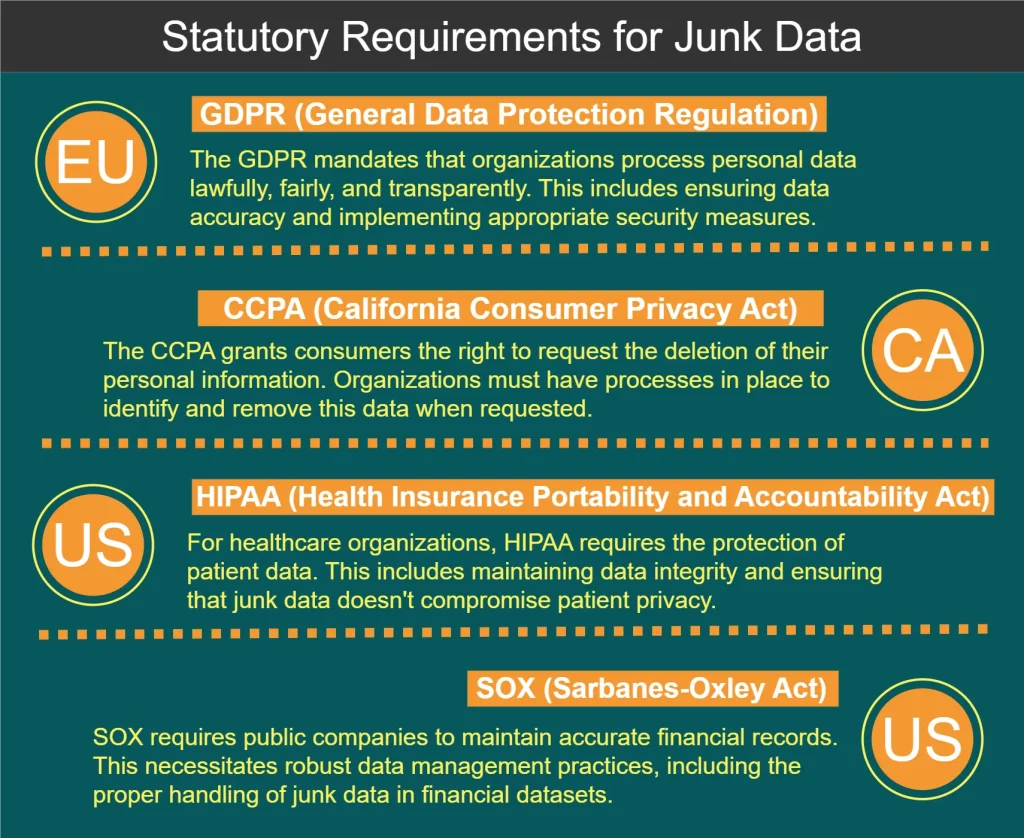
Gesetzliche Anforderungen an die Verarbeitung von Junk-Daten
Verschiedene Vorschriften und Standards regeln den Umgang mit Daten, einschließlich der Verarbeitung von Junk-Daten. Einige wichtige Anforderungen sind im untenstehenden Diagramm dargestellt:
Best Practices für die Verarbeitung von Junk-Daten
Um Daten effektiv zu verwalten und die Datenintegrität zu wahren, sollten folgende Best Practices beachtet werden:
- Implementieren Sie eine Datenvalidierung am Eingabepunkt, um zu verhindern, dass Junk-Daten in Ihre Systeme gelangen.
- Überprüfen Sie regelmäßig Ihre Datensätze, um Datenqualitätsprobleme zu identifizieren und zu beheben.
- Entwickeln Sie eine umfassende Daten-Governance-Richtlinie, die Richtlinien zum Umgang mit Junk-Daten enthält.
- Investieren Sie in die Schulung der Mitarbeiter, um sicherzustellen, dass alle Teammitglieder die Bedeutung der Datenqualität verstehen.
- Verwenden Sie automatisierte Tools, um den Prozess der Identifizierung und Entfernung von Junk-Daten zu vereinfachen.
- Implementieren Sie ein Datenqualitätsbewertungssystem, um Verbesserungen im Laufe der Zeit zu verfolgen.
- Stellen Sie eine Rückkopplungsschleife mit Datenbenutzern her, um Datenqualitätsprobleme schnell zu identifizieren und zu beheben.
Am Ende dieses Artikels erwähnen wir auch, wie man einfache Methoden zur Erkennung von Junk-Daten in Python implementiert.
Datenanalyse und Identifizierung von Junk-Daten mit Python
Python hat sich aufgrund seiner Einfachheit, Vielseitigkeit und seines robusten Ökosystems datenbezogener Bibliotheken zur bevorzugten Sprache für die Datenanalyse entwickelt. Hier sind einige Möglichkeiten, wie man Daten analysieren und Junk-Daten mit Python identifizieren kann:
1. Pandas zur Datenmanipulation und -analyse
Pandas ist eine leistungsstarke Bibliothek zur Datenmanipulation und -analyse in Python. Sie bietet Datenstrukturen wie DataFrames, die die Arbeit mit strukturierten Daten erleichtern.
Beispiel: Fehlende Werte und Duplikate identifizieren
import pandas as pd
# Daten in ein DataFrame laden
df = pd.read_csv('your_data.csv')
# Nach fehlenden Werten suchen
missing_values = df.isnull().sum()
# Duplikate identifizieren
duplicates = df.duplicated().sum()
print("Fehlende Werte:\n", missing_values)
print("Anzahl der doppelten Reihen:", duplicates)Ergebnis: Dieses Skript gibt die Anzahl der fehlenden Werte für jede Spalte und die Gesamtzahl der doppelten Zeilen in Ihrem Datensatz aus, wodurch Sie potenzielle Junk-Daten identifizieren können.
2. Matplotlib und Seaborn zur Datenvisualisierung
Die Visualisierung Ihrer Daten kann helfen, Ausreißer und ungewöhnliche Muster zu identifizieren, die auf Junk-Daten hindeuten könnten.
Beispiel: Boxplot zur Erkennung von Ausreißern erstellen
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Daten laden
df = pd.read_csv('your_data.csv')
# Boxplot erstellen
plt.figure(figsize=(10, 6))
sns.boxplot(x='category', y='value', data=df)
plt.title('Verteilung der Werte nach Kategorien')
plt.show()Ergebnis: Dies generiert einen Boxplot, der die Verteilung der Werte über verschiedene Kategorien visuell darstellt, wodurch Ausreißer, die Junk-Daten sein könnten, leicht zu erkennen sind.
3. Scikit-learn zur Anomalieerkennung
Scikit-learn bietet maschinelle Lernalgorithmen, die zur Anomalieerkennung verwendet werden können, um ungewöhnliche Datenpunkte zu identifizieren, die Junk-Daten sein könnten.
Beispiel: Verwendung von Isolation Forest zur Anomalieerkennung
import pandas as pd
from sklearn.ensemble import IsolationForest
# Daten laden und vorbereiten
df = pd.read_csv('your_data.csv')
X = df[['feature1', 'feature2']] # Relevante Merkmale auswählen
# Modell erstellen und anpassen
iso_forest = IsolationForest(contamination=0.1, random_state=42)
outliers = iso_forest.fit_predict(X)
# Ergebnisse zum DataFrame hinzufügen
df['is_outlier'] = outliers
# Potenzielle Junk-Daten (Ausreißer) anzeigen
junk_data = df[df['is_outlier'] == -1]
print(junk_data)Ergebnis: Dieses Skript verwendet den Isolation-Forest-Algorithmus, um potenzielle Ausreißer in Ihrem Datensatz zu identifizieren, die auf Junk-Daten hinweisen könnten.
4. Benutzerdefinierte Funktionen zur Datenqualitätsprüfung
Sie können benutzerdefinierte Python-Funktionen erstellen, um spezifische Datenqualitätsprüfungen durchzuführen, die auf Ihren Datensatz zugeschnitten sind.
Beispiel: Überprüfung auf unrealistische Werte in einem Temperaturdatensatz
import pandas as pd
def check_temperature_range(df, column, min_temp, max_temp):
"""Überprüfen, ob die Temperaturwerte innerhalb eines realistischen Bereichs liegen."""
outliers = df[(df[column] < min_temp) | (df[column] > max_temp)]
return outliers
# Daten laden
df = pd.read_csv('temperature_data.csv')
# Überprüfung auf unrealistische Temperaturen (z.B. unter -100°C oder über 60°C)
junk_temps = check_temperature_range(df, 'temperature', -100, 60)
print("Potentiell fehlerhafte Temperaturmessungen:")
print(junk_temps)Ergebnis: Diese Funktion identifiziert Temperaturmessungen, die außerhalb eines festgelegten realistischen Bereichs liegen, und hilft so, potenziell fehlerhafte oder Junk-Daten zu erkennen.
5. Datenprofilierung mit ydata-profiling
Die ydata-profiling-Bibliothek (ehemals pandas-profiling) bietet eine einfache Möglichkeit, umfassende Berichte über Ihren Datensatz zu erstellen, einschließlich potenzieller Qualitätsprobleme.
Beispiel: Erstellen eines Datenprofilberichts
import pandas as pd
from ydata_profiling import ProfileReport
# Daten laden
df = pd.read_csv('your_data.csv')
# Bericht erstellen
profile = ProfileReport(df, title="Data Profiling Report", explorative=True)
# Bericht als Datei speichern
profile.to_file("data_profile_report.html")Ergebnis: Dieses Skript generiert einen HTML-Bericht mit detaillierten Statistiken, Visualisierungen und potenziellen Qualitätsproblemen in Ihrem Datensatz, der einen umfassenden Überblick bietet und hilft, Junk-Daten zu identifizieren.
Durch die Einbindung dieser Python-basierten Techniken in Ihren Datenanalyse-Workflow können Sie Junk-Datenprobleme effektiver identifizieren und angehen und so die Gesamtqualität und Zuverlässigkeit Ihrer Datensätze verbessern.
Fazit: Der Weg zu besserer Datenintegrität
Die Verarbeitung von Junk-Daten ist ein kritischer Aspekt zur Aufrechterhaltung der Datenintegrität und zur Sicherstellung der Zuverlässigkeit Ihrer Datenanalysebemühungen. Durch die Nutzung starker Klassifikationsmethoden, kostenloser Tools und das Befolgen bewährter Verfahren können Organisationen die Datenqualität erheblich verbessern.
Denken Sie daran, dass die Datenbereinigung eine kontinuierliche Anstrengung erfordert, die ständige Wachsamkeit und Anpassung an sich verändernde Datenlandschaften benötigt. Indem Sie die Datenqualität priorisieren und effektive Strategien zur Verarbeitung irreführender Daten implementieren, können Organisationen das volle Potenzial ihrer Daten ausschöpfen und fundiertere Entscheidungen treffen.
Für benutzerfreundliche und flexible Tools, die die Datensicherheit verbessern und die Einhaltung gesetzlicher Vorschriften sicherstellen, sollten Sie die Angebote von DataSunrise in Betracht ziehen. Besuchen Sie unsere Website DataSunrise.com für eine Online-Demo und entdecken Sie, wie wir Ihnen helfen können, die Datenintegrität zu wahren und gleichzeitig gesetzliche Anforderungen zu erfüllen.
