
Umfassender Leitfaden zur Datenmaskierung für die Sicherheit und den Datenschutz von Dataframes

Einführung
Vielleicht sind Ihnen unsere Artikel über Datenmaskierung aus der Perspektive der Datenspeicherung begegnet, in denen wir statische, dynamische und inplace-Maskierungstechniken diskutiert haben. Das Maskierungsverfahren in der Datenwissenschaft unterscheidet sich jedoch etwas. Während wir immer noch die Privatsphäre wahren und den Datenschutz für Dataframes gewährleisten müssen, streben wir auch danach, datengestützte Erkenntnisse abzuleiten. Die Herausforderung besteht darin, die Daten informativ zu halten und gleichzeitig ihre Vertraulichkeit zu gewährleisten.
Da Organisationen stark auf Datenwissenschaft zur Gewinnung von Erkenntnissen und zur Entscheidungsfindung angewiesen sind, war der Bedarf an robusten Datenschutztechniken noch nie größer. Dieser Artikel befasst sich mit dem wichtigen Thema der Datenmaskierung in Dataframes und untersucht, wie dieses Verfahren sensible Daten schützt und gleichzeitig deren Nutzen für die Analyse erhält.
Verständnis der Datenmaskierung in der Datenwissenschaft
Die Datenmaskierung ist ein kritischer Prozess im Bereich des Datenschutzes. Obwohl wir nicht zu tief in ihre allgemeinen Aspekte eintauchen werden, ist es wichtig, ihre Rolle in der Datenwissenschaft zu verstehen.
Im Kontext der Datenwissenschaft spielen Maskierungstechniken eine wichtige Rolle bei der Erhaltung der statistischen Eigenschaften von Datensätzen, während sensible Informationen verborgen bleiben. Dieses Gleichgewicht ist entscheidend, um die Nützlichkeit der Daten zu erhalten und gleichzeitig die Privatsphäre und die Einhaltung gesetzlicher Anforderungen zu gewährleisten.
Format erhaltene Maskierung: Balance zwischen Nützlichkeit und Privatsphäre
Format erhaltene Maskierungstechniken sind besonders wertvoll in Anwendungen der Datenwissenschaft. Diese Methoden helfen, die statistischen Parameter des Datensatzes zu bewahren und gleichzeitig sensible Informationen effektiv zu schützen. Durch die Erhaltung des Formats und der Verteilung der Originaldaten können Forscher und Analysten mit maskierten Datensätzen arbeiten, die den echten Daten sehr ähnlich sind und die Gültigkeit ihrer Ergebnisse gewährleisten, ohne die Privatsphäre zu gefährden.
Was ist ein Dataframe?
Bevor wir uns mit Maskierungsverfahren befassen, lassen Sie uns klären, was ein Dataframe ist. In der Datenwissenschaft ist ein Dataframe eine zweidimensionale, beschriftete Datenstruktur mit Spalten verschiedener Typen. Es ist vergleichbar mit einer Tabelle in einer Datenbank oder einer Tabelle in einer Tabellenkalkulation und ist ein grundlegendes Werkzeug für die Datenmanipulation und -analyse in vielen Programmiersprachen, insbesondere in Python mit Bibliotheken wie Pandas.
Maskierung von Daten in Dataframes
Beim Schutz sensibler Informationen in Dataframes gibt es zwei Hauptansätze:
- Maskierung während der Dataframe-Erstellung
- Anwendung von Maskierungstechniken nach der Dataframe-Erstellung
Untersuchen wir beide Methoden im Detail.
Maskierung während der Dataframe-Erstellung
Dieser Ansatz beinhaltet die Anwendung von Maskierungstechniken, während die Daten in den Dataframe geladen werden. Es ist besonders nützlich, wenn man mit großen Datensätzen arbeitet oder sicherstellen möchte, dass sensible Daten niemals in ihrer Rohform in die Arbeitsumgebung gelangen.
Beispiel: Maskierung während des CSV-Imports
Hier ist ein einfaches Beispiel mit Python und Pandas, um sensible Daten beim Import einer CSV-Datei zu maskieren:
import pandas as pd
import hashlib
def mask_sensitive_data(value):
return hashlib.md5(str(value).encode()).hexdigest()
# Lesen der CSV-Datei mit angewandter Maskierungsfunktion auf die 'ssn'-Spalte
df = pd.read_csv('employee_data.csv', converters={'ssn': mask_sensitive_data})
print(df.head())In diesem Beispiel verwenden wir eine Hashfunktion, um die ‘ssn’ (Sozialversicherungsnummer)-Spalte zu maskieren, während die Daten in den Dataframe gelesen werden. Das Ergebnis ist ein Dataframe, in dem die ‘ssn’-Spalte gehashte Werte statt der ursprünglichen sensiblen Daten enthält.
Die Ausgabe des Codes sollte folgendermaßen aussehen:
index name age ssn salary department 0 Tim Hernandez 37 6d528… 144118.53 Marketing 1 Jeff Jones 29 5787e… 73994.32 IT 2 Nathan Watts 64 86975… 45936.64 Sales …
Anwendung von Maskierungstechniken nach der Dataframe-Erstellung
Diese Methode umfasst die Suche nach und Maskierung sensibler Daten in einem bestehenden Dataframe. Sie ist nützlich, wenn man zunächst mit den Originaldaten arbeiten muss, sie aber vor der Weitergabe oder Speicherung schützen möchte.
Beispiel: Maskierung bestehender Dataframe-Spalten
Hier ist ein Beispiel dafür, wie spezifische Spalten in einem bestehenden Dataframe maskiert werden können:
import pandas as pd
import numpy as np
# Erstellen eines Beispiel-Dataframes
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'ssn': ['123-45-6789', '987-65-4321', '456-78-9012']
})
# Funktion zur Maskierung der SSN
def mask_ssn(ssn):
return 'XXX-XX-' + ssn[-4:]
# Anwenden der Maskierung auf die 'ssn'-Spalte
df['ssn'] = df['ssn'].apply(mask_ssn)
print(df)Dieses Skript erstellt einen Beispieldataframe und wendet dann eine benutzerdefinierte Maskierungsfunktion auf die ‘ssn’-Spalte an. Das Ergebnis ist ein Dataframe, in dem nur die letzten vier Ziffern der SSN sichtbar sind, während der Rest mit ‘X’ Zeichen maskiert ist.
Dies wird folgendermaßen ausgegeben:
name age ssn 0 Alice 25 XXX-XX-6789 1 Bob 30 XXX-XX-4321 2 Charlie 35 XXX-XX-9012
Erweiterte Maskierungstechniken für Dataframes
Wenn wir tiefer in den Datenschutz von Dataframes eintauchen, ist es wichtig, raffiniertere Maskierungstechniken zu erkunden, die auf verschiedene Datentypen und Szenarien angewendet werden können.
Numerische Datenmaskierung
Beim Umgang mit numerischen Daten kann es entscheidend sein, statistische Eigenschaften zu bewahren, während sie maskiert werden. Hier ist ein Beispiel, wie man Rauschen zu numerischen Daten hinzufügt und dabei deren Mittelwert und Standardabweichung beibehält:
import pandas as pd
import numpy as np
# Erstellen eines Beispiel-Dataframes mit numerischen Daten
df = pd.DataFrame({
'id': range(1, 1001),
'salary': np.random.normal(50000, 10000, 1000)
})
# Funktion zur Hinzufügung von Rauschen bei Beibehaltung des Mittelwerts und der Standardabweichung
def add_noise(column, noise_level=0.1):
noise = np.random.normal(0, column.std() * noise_level, len(column))
return column + noise
# Anwenden von Rauschen auf die Gehaltspalte
df['masked_salary'] = add_noise(df['salary'])
print("Originale Gehaltsstatistiken:")
print(df['salary'].describe())
print("\nMaskierte Gehaltsstatistiken:")
print(df['masked_salary'].describe())Dieses Skript erstellt einen Beispieldataframe mit Gehaltsdaten und wendet dann eine Rauschfunktion an, um die Gehälter zu maskieren. Die resultierenden maskierten Daten behalten ähnliche statistische Eigenschaften wie die Originaldaten bei, was sie für die Analyse nützlich macht und gleichzeitig individuelle Werte schützt.
Beachten Sie, dass es keine großen Änderungen in den statistischen Parametern gibt, während die sensiblen Daten durch das Hinzufügen des Rauschens erhalten bleiben.
Originale Gehaltsstatistiken: count 1000.000000 mean 49844.607421 std 9941.941468 min 18715.835478 25% 43327.385866 50% 49846.432943 75% 56462.098573 max 85107.367406 Name: salary, dtype: float64 Maskierte Gehaltsstatistiken: count 1000.000000 mean 49831.697951 std 10035.846618 min 17616.814547 25% 43129.152589 50% 49558.566315 75% 56587.690976 max 83885.686201 Name: masked_salary, dtype: float64
Die Normalverteilungen sehen jetzt so aus:
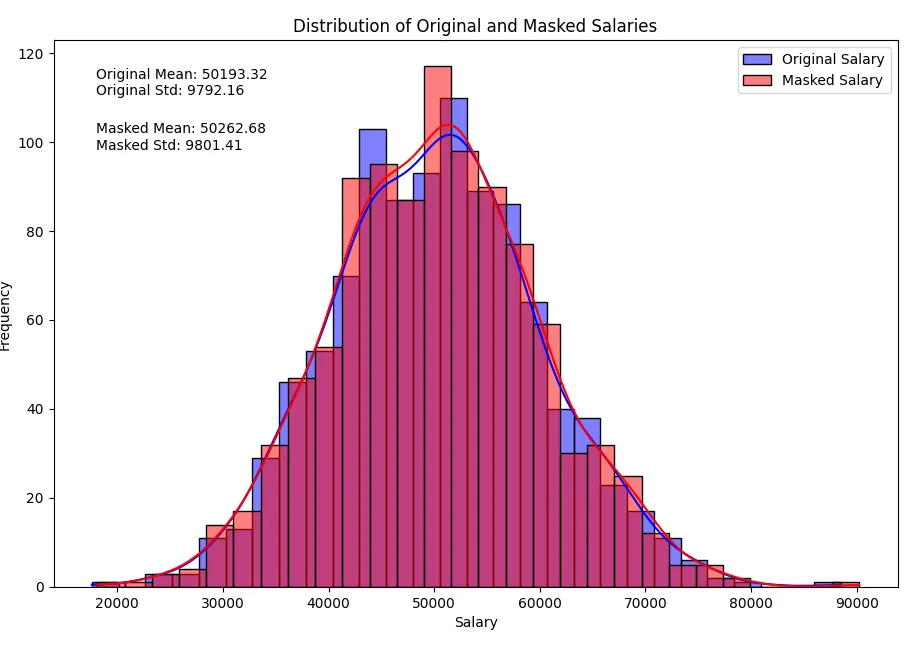
Kategorische Datenmaskierung
Bei kategorischen Daten möchten wir möglicherweise die Verteilung der Kategorien bewahren und gleichzeitig individuelle Werte maskieren. Hier ist ein Ansatz unter Verwendung einer Wertzuordnung:
import pandas as pd
import numpy as np
# Erstellen eines Beispiel-Dataframes mit kategorialen Daten
df = pd.DataFrame({
'id': range(1, 1001),
'department': np.random.choice(['HR', 'IT', 'Sales', 'Marketing'], 1000)
})
# Erstellen eines Zuordnungsdictionaries
dept_mapping = {
'HR': 'Dept A',
'IT': 'Dept B',
'Sales': 'Dept C',
'Marketing': 'Dept D'
}
# Anwenden der Zuordnung zur Maskierung der Abteilungsnamen
df['masked_department'] = df['department'].map(dept_mapping)
print(df.head())
print("\nOriginale Abteilungsverteilung:")
print(df['department'].value_counts(normalize=True))
print("\nMaskierte Abteilungsverteilung:")
print(df['masked_department'].value_counts(normalize=True))Dieses Beispiel zeigt, wie man kategoriale Daten (Abteilungsnamen) maskieren kann, während die ursprüngliche Verteilung der Kategorien erhalten bleibt.
Wenn Sie die Daten darstellen, könnte es folgendermaßen aussehen. Beachten Sie, dass die Balkenlängen für maskierte und unmaskierte Daten gleich sind, während die Beschriftungen unterschiedlich sind.
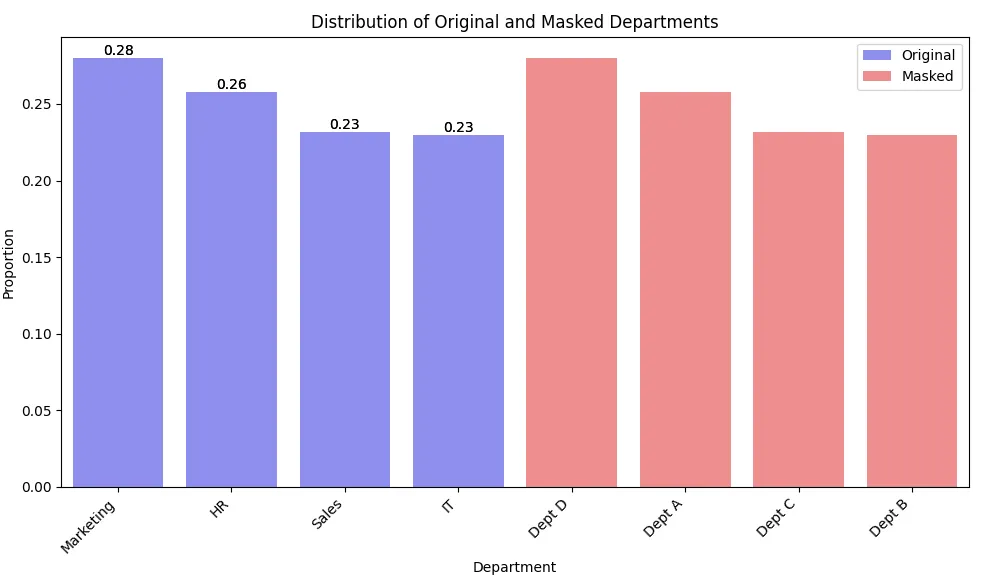
Herausforderungen beim Datenschutz in Dataframes
Während Maskierungsverfahren leistungsstarke Werkzeuge zum Schutz sensibler Daten in Dataframes bieten, haben sie ihre eigenen Herausforderungen:
- Erhaltung der Datenbrauchbarkeit: Das richtige Gleichgewicht zwischen Datenschutz und Nutzen für die Analyse zu finden, kann schwierig sein.
- Konsistenz über Datensätze hinweg: Sicherzustellen, dass maskierte Werte über mehrere verwandte Dataframes oder Datenbanktabellen konsistent sind, ist entscheidend für die Wahrung der Datenintegrität.
- Leistungsbeeinträchtigung: Einige Maskierungstechniken können rechenintensiv sein, insbesondere bei großen Datensätzen.
- Reversibilität: In einigen Fällen müssen Sie möglicherweise die Daten entmaskieren, was eine sorgfältige Verwaltung von Maskierungsschlüsseln oder -algorithmen erfordert.
Best Practices für die Datenmaskierung in der Datenwissenschaft
Um diese Herausforderungen zu bewältigen und eine effektive Datenmaskierung in Dataframes sicherzustellen, sollten Sie die folgenden Best Practices berücksichtigen:
- Verstehen Sie Ihre Daten: Analysieren Sie Ihre Daten gründlich, bevor Sie eine Maskierungstechnik anwenden, um deren Struktur, Beziehungen und Empfindlichkeitsstufen zu verstehen.
- Wählen Sie geeignete Techniken: Wählen Sie Maskierungsmethoden, die für Ihre spezifischen Datentypen und Analyseanforderungen geeignet sind.
- Erhalten Sie referenzielle Integrität: Stellen Sie sicher, dass die maskierten Werte die erforderlichen Beziehungen zwischen Tabellen oder Dataframes beibehalten, wenn Sie verwandte Datensätze maskieren.
- Regelmäßige Überprüfung: Überprüfen und aktualisieren Sie Ihre Maskierungsverfahren regelmäßig, um sicherzustellen, dass sie den sich entwickelnden Datenschutzstandards und Vorschriften entsprechen.
- Dokumentieren Sie Ihren Prozess: Führen Sie eine klare Dokumentation Ihrer Maskierungsverfahren zu Compliance- und Troubleshooting-Zwecken.
Fazit
Maskierung sollte die Eigenschaft der Daten erhalten, datengestützte Erkenntnisse zu produzieren. Die Datenmaskierung in Dataframes ist ein kritischer Aspekt der modernen Datenwissenschaft, der die Notwendigkeit einer aufschlussreichen Analyse mit dem Gebot des Datenschutzes in Einklang bringt. Durch das Verständnis verschiedener Maskierungstechniken und deren umsichtigen Einsatz können Datenwissenschaftler mit sensiblen Informationen arbeiten und gleichzeitig die Privatsphäre und Compliance wahren.
Wie wir untersucht haben, gibt es zwei Ansätze zur Maskierung von Daten in Dataframes, jeder mit seinen eigenen Stärken und Überlegungen. Ob Sie Daten während des Imports maskieren oder Techniken auf bestehende Dataframes anwenden, der Schlüssel liegt darin, Methoden zu wählen, die die Nützlichkeit Ihrer Daten bewahren und gleichzeitig sensible Informationen effektiv schützen.
Denken Sie daran, dass Datenschutz ein fortlaufender Prozess ist. Da sich die Datenwissenschaftstechniken weiterentwickeln und neue Herausforderungen im Bereich der Privatsphäre auftauchen, wird es entscheidend sein, informiert und anpassungsfähig in Ihrem Ansatz zum Datenschutz von Dataframes zu bleiben.
