
Name Shuffling
Einführung
Unternehmen stehen vor der Herausforderung, die Datenprivatsphäre zu wahren, während sie dennoch realistische Daten für Testumgebungen und Entwicklung verwenden. Hier kommen das Name Shuffling und Datenmaskierung ins Spiel.
Interessante Tatsache: Die SSA (Sozialversicherungsverwaltung) veröffentlicht Daten über die Namen, die jedes Jahr Babys gegeben werden. In einem typischen Jahr gibt es etwa 30.000 bis 35.000 einzigartige Namen, die für Neugeborene verwendet werden.
Dieser Artikel wird das Konzept des Shufflings, seine Implementierung und seine Vorteile bei der Erstellung sicherer Testdaten untersuchen.
DataSunrise bietet fortschrittliche Datenmaskierungslösungen mit leistungsstarken Shuffling-Techniken. Unsere fortschrittliche Plattform gewährleistet einen robusten Datenschutz und gleichzeitig die Nutzbarkeit der Daten. Mit DataSunrise können Organisationen mit Vertrauen die Einhaltung der Datenschutzbestimmungen sicherstellen und sensible Informationen schützen. Erleben Sie das perfekte Gleichgewicht zwischen Sicherheit und Benutzerfreundlichkeit in Ihren Datenmanagementprozessen.
DataSunrise ermöglicht die zufällige Auswahl von Werten aus benutzerdefinierten Lexika. Diese Lexika können manuell erstellt oder mit Werten aus der Datenbank gefüllt werden. Dieser Ansatz implementiert nicht nur Shuffle, sondern auch eine zufällige Wertauswahl.
Was ist Datenmaskierung?
Bevor wir uns dem Name Shuffling widmen, lassen Sie uns kurz auf die Datenmaskierung eingehen. Datenmaskierung ist eine Methode zur Erstellung einer strukturell ähnlichen, aber inauthentischen Version der Daten einer Organisation. Sie ersetzt sensible Informationen durch realistische, aber gefälschte Daten. Dadurch können Unternehmen maskierte Daten für Tests, Entwicklung und Analysen verwenden, ohne das Risiko der Offenlegung vertraulicher Informationen einzugehen.
Regulierungen und Compliance zur Datenmaskierung
Regulatorische Rahmenwerke verlangen zunehmend den Datenschutz durch Maskierungstechniken. Die DSGVO erfordert angemessene Schutzmaßnahmen für die Verarbeitung personenbezogener Daten. HIPAA verlangt den Schutz von Gesundheitsinformationen in Nicht-Produktionsumgebungen. PCI DSS verbietet die Verwendung echter Karteninhaberdaten für Tests. Der CCPA gibt Verbrauchern Kontrolle über die Nutzung persönlicher Informationen. Branchenstandards verlangen oft die Anonymisierung von Testdaten. Gesundheitsorganisationen unterliegen strengen Anforderungen an den Schutz von Patientendaten. Finanzinstitutionen müssen Kundendaten während der Entwicklung schützen. Strafen für Nichteinhaltung können Millionen von Dollar erreichen. Datenmaskierung bietet dokumentierte Nachweise für die Einhaltung der Datenschutzbestimmungen. Regulierungen verlangen häufig formelle Risikobewertungen für den Umgang mit Daten. Regelmäßige Compliance-Audits überprüfen die ordnungsgemäße Implementierung der Maskierung. Unternehmen müssen angemessene Sicherheitsmaßnahmen wie Shuffling demonstrieren.
Verständnis von Name Shuffling
Was ist Name Shuffling?
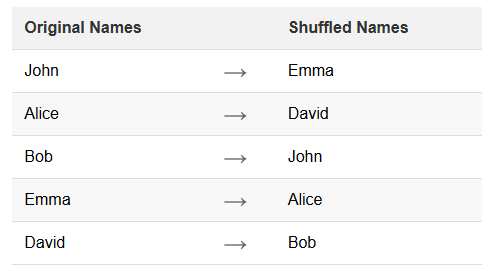
Name Shuffling ist eine spezifische Technik zur Datenmaskierung. Es umfasst das Umordnen bestehender Daten innerhalb eines Datensatzes. Diese Methode bewahrt die Datenintegrität und Realismus, während einzelne Identitäten verschleiert werden. Shuffling ist besonders nützlich, um persönliche Informationen in Datenbanken zu schützen.
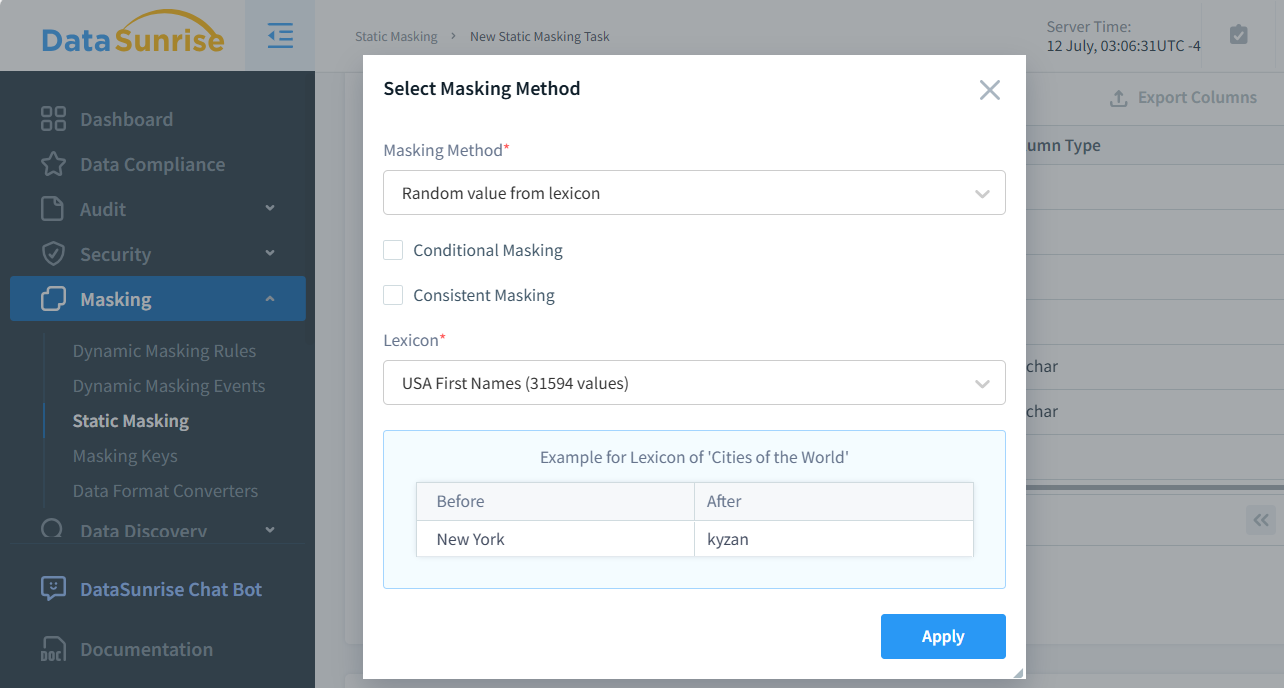
Wie in der Einführung erwähnt, ermöglicht DataSunrise die erstellung lexikonbasierter Zufallsauswahlmethoden zur Maskierung. Die Abbildung unten zeigt die Auswahl dieser Maskierungsmethode in der DataSunrise-Benutzeroberfläche. Wie Sie sehen können, sind 31.594 Werte verfügbar, was viel zuverlässiger ist als einfaches Shuffling eines gegebenen Sets. Diese erhöhte Zuverlässigkeit resultiert daraus, dass bei n einzigartigen Werten in einer Spalte die Wahrscheinlichkeit, dass ein einzelner Wert sich selbst zugeordnet wird, 1/n beträgt.
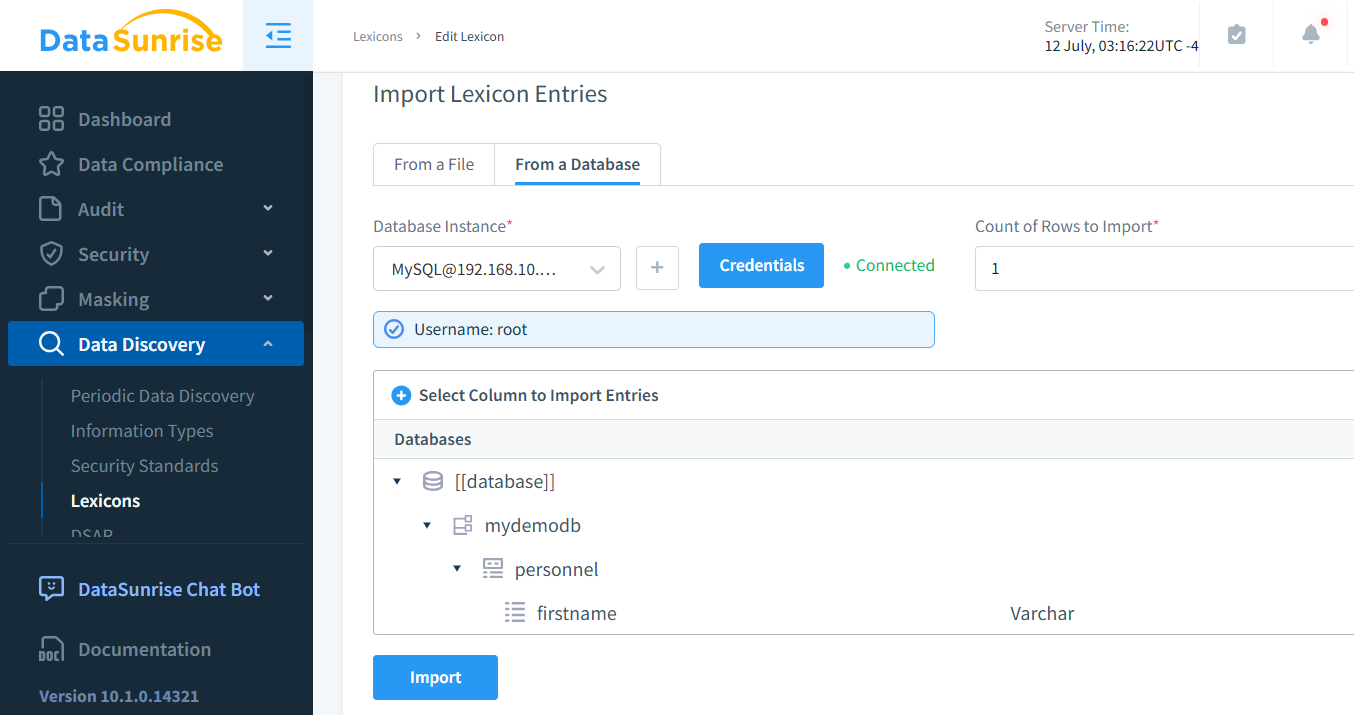
Wenn Sie es vorziehen, mit bestehenden Werten zuzuordnen, können Sie dies problemlos durch die Erstellung eines benutzerdefinierten Lexikons erreichen. Dieser Ansatz ist besonders nützlich in Situationen, in denen die gemischten Werte keine US-amerikanischen Vornamen sind, da er eine kontextuell angemessenere Datenmaskierung ermöglicht.
Wie funktioniert Name Shuffling?
Der Prozess ist einfach:
- Wählen Sie eine Spalte mit Namen (Vornamen, Nachnamen oder beides).
- Ordnen Sie die Werte innerhalb dieser Spalte zufällig neu.
- Ersetzen Sie die Originalwerte durch die gemischten.
Diese Technik bewahrt die Verteilung und Eigenschaften der Originaldaten. Sie durchbricht jedoch die Verbindung zwischen Individuen und ihren Informationen.
Implementierung von Name Shuffling in R und Python
Schauen wir uns an, wie das einfachste Name Shuffling in zwei beliebten Programmiersprachen implementiert wird: Python und R.
Es ist wichtig zu beachten, dass der von DataSunrise gebotene Nutzungsgrad in diesem Zusammenhang unübertroffen ist. Eine flexible All-in-One-Lösung mit nur wenigen Codezeilen zu erstellen, ist mit Standardprogrammiersprachen nicht möglich. Unser Ziel hier ist es, die Fähigkeiten spezialisierter Werkzeuge wie DataSunrise im Vergleich zu allgemeinen Programmiersprachen hervorzuheben.
Name Shuffling in Python
Python bietet einfache und effiziente Methoden zur Datenmischung. Hier ist ein Beispiel unter Verwendung von pandas, einer leistungsstarken Datenmanipulationsbibliothek:
import pandas as pd
import numpy as np
# Erstellen Sie einen Beispieldatensatz
data = pd.DataFrame({
'FirstName': ['John', 'Alice', 'Bob', 'Emma', 'David'],
'LastName': ['Smith', 'Johnson', 'Williams', 'Brown', 'Jones'],
'Age': [32, 28, 45, 36, 51],
'Salary': [50000, 60000, 75000, 65000, 80000]
})
# Mischen der Spalte 'FirstName'
data['FirstName'] = np.random.permutation(data['FirstName'])
# Mischen der Spalte 'LastName'
data['LastName'] = np.random.permutation(data['LastName'])
print(data)Dieses Skript erstellt einen Beispieldatensatz und mischt sowohl die Spalte ‘FirstName’ als auch ‘LastName’. Das Ergebnis bewahrt die Originalnamen, randomisiert jedoch deren Reihenfolge, wodurch einzelne Identitäten effektiv maskiert werden.
Name Shuffling in R
R bietet ebenfalls einfache Methoden zur Datenmischung. Hier ist ein Beispiel:
# Erstellen Sie einen Beispieldatensatz
data <- data.frame(
FirstName = c("John", "Alice", "Bob", "Emma", "David"),
LastName = c("Smith", "Johnson", "Williams", "Brown", "Jones"),
Age = c(32, 28, 45, 36, 51),
Salary = c(50000, 60000, 75000, 65000, 80000)
)
# Mischen der Spalte 'FirstName'
data$FirstName <- sample(data$FirstName)
# Mischen der Spalte 'LastName'
data$LastName <- sample(data$LastName)
print(data)Dieses R-Skript erzielt das gleiche Ergebnis wie das Python-Beispiel. Es mischt die Spalten ‘FirstName’ und ‘LastName’, bewahrt die Datenintegrität und maskiert gleichzeitig individuelle Identitäten.
Vorteile des Name Shuffling
Name Shuffling bietet mehrere Vorteile:
- Erhält den Realismus der Daten: Gemischte Daten bewahren die Eigenschaften des originalen Datensatzes.
- Bewahrt die Datenverteilung: Die Häufigkeit der Namen bleibt gleich, was für statistische Analysen nützlich ist.
- Einfache Implementierung: Es ist leicht anzuwenden und zu verstehen.
- Rückgängig zu machen: Bei Bedarf kann der Prozess mit dem richtigen Schlüssel rückgängig gemacht werden.
Herausforderungen und Überlegungen
Obwohl Name Shuffling effektiv ist, ist es wichtig zu berücksichtigen:
- Einzigartigkeit: Seltene Namen könnten dennoch identifizierbar sein.
- Konsistenz: Stellen Sie sicher, dass das Shuffling in verwandten Tabellen konsistent ist.
- Kontextuelle Informationen: Andere Datenfelder könnten weiterhin Identitäten offenbaren.
Best Practices für Name Shuffling
Um die Effektivität des Name Shuffling zu maximieren:
- Große Datensätze verwenden: Je größer der Datensatz, desto effektiver ist das Shuffling.
- Techniken kombinieren: Verwenden Sie Name Shuffling in Kombination mit anderen Maskierungsmethoden für besseren Schutz.
- Konsistente Anwendung: Wenden Sie das Shuffling konsistent auf alle verwandten Daten an.
- Regelmäßige Aktualisierungen: Schütten Sie Daten regelmäßig neu, um eine Rückverfolgung zu verhindern.
Name Shuffling bei der Erstellung von Testdaten
Name Shuffling ist besonders wertvoll bei der Erstellung von Testdaten. Es ermöglicht Entwicklern und Testern, mit realistischen Daten zu arbeiten, ohne die Privatsphäre zu gefährden. Hier ist der Grund warum es wichtig ist:
- Realistisches Testen: Verschobene Namen bewahren die Eigenschaften echter Daten.
- Einhaltung der Datenschutzbestimmungen: Es hilft, Datenschutzbestimmungen zu erfüllen.
- Effiziente Entwicklung: Entwickler können Daten verwenden, die Produktionsumgebungen nahekommen.
Fazit
Name Shuffling ist eine leistungsstarke Technik zur Datenmaskierung. Es bietet ein Gleichgewicht zwischen Datennutzbarkeit und Datenschutz. Durch die Implementierung von Name Shuffling können Organisationen realistische Testdaten erstellen, während sie sensible Informationen schützen. Mit zunehmenden Sorgen über den Datenschutz werden Methoden wie Shuffling bei der Datenverwaltung an Bedeutung gewinnen.
Für diejenigen, die fortschrittliche Datenmaskierungslösungen suchen, bietet DataSunrise benutzerfreundliche und flexible Werkzeuge für die Datenbanksicherheit. Unser umfassendes dynamisches und statisches Datenmaskierungstool enthält robuste Shuffling- und Verschlüsselungsfunktionen. Besuchen Sie die Website von DataSunrise für eine Online-Demo und erfahren Sie, wie unsere Lösungen Ihre Datenschutzstrategien verbessern können.
