
Buffer-Overflow-Angriffe: Eine gefährliche digitale Bedrohung

Buffer-Overflow-Angriffe stellen eine erhebliche Bedrohung für die Softwaresicherheit dar. Diese Angriffe treten auf, wenn böswillige Personen Schwachstellen im Buffer-Overflow ausnutzen. Dies kann zu Programmabstürzen, Datenkorruption, Diebstahl von sensiblen Informationen und unbefugtem Systemzugriff führen. Dieser Artikel erklärt Buffer-Overflows, wie Angreifer sie nutzen und Methoden zu ihrer Verhinderung in der Softwareentwicklung.
Die Grundlagen von Buffer-Overflows
Ein Puffer (Buffer) ist im Kontext der Informatik ein Speicherbereich, der temporär Daten speichert. Programme nutzen Buffer, um verschiedene Arten von Daten zu halten, wie Benutzereingaben, Dateiinhalte oder Zeichenketten.
Jeder Buffer hat eine festgelegte Größe. Probleme treten auf, wenn ein Programm versucht, mehr Daten zu speichern, als der Puffer halten kann. In solchen Fällen überschreiten die zusätzlichen Daten den Puffer und fließen in benachbarte Speicherbereiche. Dieses unbeabsichtigte Verhalten kann zu Programmabstürzen, Datenkorruption und Sicherheitslücken führen.
Betrachten Sie das folgende Beispiel in der Programmiersprache C:
char buffer[8];
scanf("%s", buffer);
Dieser Codeausschnitt ordnet einen 8-Byte-Puffer zu, um eine Zeichenkette zu speichern, die aus Benutzereingaben stammt. Wenn der Benutzer mehr als 8 Zeichen eingibt, werden benachbarte Speicherbereiche überschrieben.
Ausnutzen von Buffer-Overflow-Schwachstellen
Angreifer nutzen Buffer-Overflow-Schwachstellen aus, indem sie gezielt Speicherbereiche überschreiben, die ausführbaren Code enthalten, und diesen durch bösartigen Code ersetzen. Der Angreifer identifiziert zunächst ein Programm mit einer bekannten Buffer-Overflow-Schwachstelle. Der Angreifer sendet absichtlich zu viele Daten, um das System zu überwältigen und Speicherbeschädigungen zu verursachen.
Der Angreifer möchte den Puffer durch bösartigen Code ersetzen. Dieser Code kann schädliche Aktionen ausführen, wie das Öffnen einer Shell oder das Ausführen von Befehlen ohne Erlaubnis. Der Angriff ist erfolgreich, wenn der Angreifer eine Rücksprungadresse oder einen Ausnahmehandler ändert. Wenn der Benutzer den veränderten Code ausführt, wird der bösartige Code ausgeführt.
Um dieses Konzept zu veranschaulichen, betrachten Sie ein Serverprogramm, das Benutzernamen von Clients empfängt. Wenn der Benutzernamenspeicherplatz 128 Bytes beträgt, könnte ein Hacker einen schädlichen Benutzernamen in einem bestimmten Format senden.
"A" * 132 + bösartiger_code + falsche_rücksprungadresse
Die Serie von “A”-Zeichen überschreibt den Puffer und ermöglicht es dem bösartigen Code, in den Speicher zu schreiben. Die falsche Rücksprungadresse stellt sicher, dass der bösartige Code ausgeführt wird, wenn die überschreibene Funktion zurückkehrt.
Reale Beispiele für Buffer-Overflow
Jeder Buffer-Overflow-Angriff läuft nach der gleichen Strategie ab:
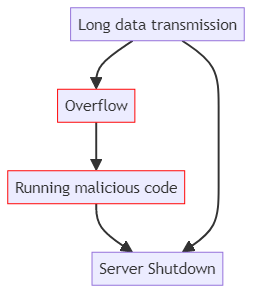
Hier sind einige reale Beispiele für Overflow-Schwachstellen, die im Laufe der Jahre in beliebten DBMS gefunden wurden.
MySQL COM_FIELD_LIST
Bis 2012 waren MySQL und MariaDB anfällig für die COM_FIELD_LIST-Schwachstelle. Die Grundlagen der Schwachstelle waren wie folgt:
Ein Angreifer würde eine Abfrage an den MySQL-Server mit einer ‘FROM’-Klausel senden und einen sehr langen Tabellennamen angeben, um einen Buffer-Overflow zu verursachen.
SELECT * FROM 'sehr_langer_tabellenname'.
Die genaue Länge war nicht spezifiziert, aber 5000 Bytes reichten aus, um einen Overflow zu verursachen. Dies würde zum Serverabsturz führen, aber im Moment zwischen dem Overflow und dem Absturz würde der Server anfällig für Angriffe. An diesem Punkt würden Angreifer bösartigen Code in hexadezimaler Byteform einfügen.
SELECT * FROM 'sehr_langer_name'.\x31\xc0\x50\x68\x2f\x2f\x73'
Der Code musste Bash-Befehle ausführen, zum Beispiel ‘rm -rf /bin/’.
Für eine höhere Erfolgschance würden Angreifer ein No-Operation-Segment in den Code einfügen, mit anderen Worten, Code, der nichts ausführt.
Eine vollständige Abfrage sähe so aus:
SELECT * FROM 'AAAAAAAAAAA..' verursacht Buffer-Overflow '\x0\x0\x0\x0\x0' - No-Operation-Segement '\xe3\x50\x53\x89\xe1\xb0\x0b' - Bösartiger Code.
Die Schwachstelle wurde in den MySQL-Versionen 5.5.23, 5.1.63 und 5.6.6 sowie in den MariaDB-Versionen 5.5.23, 5.3.12, 5.2.14 und 5.1.63 behoben. Ein Update auf diese oder spätere Versionen schloss die Schwachstelle und schützte die Datenbanken vor diesem spezifischen Angriff.
PostgreSQL 9.3 RESETXLOG Buffer Overflow
2013 wurde entdeckt und schnell behoben, dass die Funktion pg_resetxlog() in PostgreSQL anfällig für diese Angriffe war.
postgres=# SELECT pg_resetxlog('A' * 1000 + *bösartiger_code*);
SQL Server Slammer Wurm
2003 wurde der SQL Server Slammer Wurm entdeckt. Er zielte auf den SQL Server Resolution Service ab, der UDP-Pakete auf Port 1434 akzeptiert. Wenn ein speziell gestaltetes Paket an diesen Port gesendet wurde, wurde der Puffer überflutet und der Wurm konnte beliebigen Code ausführen. Dieser Code führte dazu, dass der Server mehr Kopien des Wurms versendete, was zu einer schnellen Verbreitung und massiven Netzwerkausfällen führte. Ein Beispiel könnte so aussehen:
payload = create_malicious_packet()
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
sock.sendto('A' * 1000, *bösartiger_code*, (ziel_ip, 1434))
sock.close()
Oracle 9i XDB HTTP Buffer Overflow
2003 wurde eine Overflow-Schwachstelle im Oracle Server entdeckt. Angreifer konnten einen sehr langen Benutzernamen in einer HTTP-GET-Anfrage senden, was den Puffer überflutete und dann bösartigen Code ausführte.
long_username = 'A' * 1000 + *bösartiger_code*
password = 'passwort'
credentials = f"{long_username}:{password}"
encoded_credentials = base64.b64encode(credentials.encode()).decode()
http_request = ( "GET / HTTP/1.1\r\n" f"
Host: {ziel_ip}\r\n" "User-Agent: Mozilla/5.0\r\n" f"
Authorization: Basic {payload}\r\n" "Accept: */*\r\n" "\r\n" )
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((ziel_ip, ziel_port))
sock.sendall(http_request.encode())
Dieses Snippet zeigt ein Python-Skript, das Anmeldeinformationen an den Oracle Server übermittelt, was dessen Puffer überflutet. Folglich führen die Anmeldeinformationen bösartigen Code aus.
Verhinderung von Buffer-Overflow-Schwachstellen
Die Entwicklung sicherer Software erfordert einen proaktiven Ansatz zur Verhinderung von Buffer-Overflow-Schwachstellen. Die folgenden Strategien sind entscheidend für die Minderung der Risiken, die mit Buffer-Overflows verbunden sind:
- Eingabevalidierung: Stellen Sie sicher, dass alle vom Benutzer bereitgestellten Daten innerhalb der erwarteten Grenzen liegen, bevor sie in Buffern gespeichert werden. Validieren Sie die Eingabelänge, das Format und den Inhalt, um zu verhindern, dass bösartige oder unbeabsichtigte Daten Buffer-Overflows verursachen.
- Sichere String- und Speicherfunktionen: Vermeiden Sie die Verwendung von Standardbibliotheksfunktionen, die anfällig für Buffer-Overflows sind. Verwenden Sie stattdessen sicherere Alternativen wie `strncpy` und `memcpy_s`, die eingebaute Schutzmechanismen gegen Overflows enthalten.
- Systemschutzfunktionen: Aktivieren Sie wann immer möglich systemweite Sicherheitsfunktionen wie Address Space Layout Randomization (ASLR) und Data Execution Prevention (DEP). Diese Mechanismen erschweren es Angreifern, Speicherlayouts vorherzusagen und bösartigen Code auszuführen.
- Verwenden Sie speichersichere Sprachen wie Rust, Go oder Java, um sich gegen Buffer-Overflows zu schützen. Diese Sprachen erzwingen strenge Speicherverwaltungspraktiken und verhindern den direkten Zugriff auf Speicher, wodurch das Risiko von Overflow-Schwachstellen verringert wird.
- Regelmäßige Software-Updates: Aktualisieren Sie Softwarebibliotheken und Abhängigkeiten umgehend, sobald Buffer-Overflow-Schwachstellen entdeckt und Patches veröffentlicht werden. Auf dem neuesten Stand der Sicherheits-Patches zu bleiben, ist entscheidend für den Schutz vor bekannten Schwachstellen.
Die Verwendung von Fuzzing-Tools und SAST-Techniken wie Taint-Analyse kann dazu beitragen, Buffer-Overflow-Bugs während der Softwareentwicklung zu finden.
Reale Auswirkungen von Buffer-Overflow-Angriffen
Im Laufe der Computergeschichte haben Hacker zahlreiche hochkarätige Sicherheitsvorfälle auf Buffer-Overflow-Schwachstellen zurückgeführt. Der Morris-Wurm war einer der ersten Internet-Würmer. Er verbreitete sich, indem er eine Sicherheitslücke im Unix-Programm `finger` 1988 ausnutzte.
Im Jahr 2017 nutzte der WannaCry-Virus eine Schwachstelle im Windows Server Message Block-Protokoll aus, um sich zu verbreiten. Innerhalb eines einzigen Tages infizierte WannaCry über 230.000 Computer weltweit und verursachte erhebliche finanzielle Verluste und Störungen.
Fazit
Buffer-Overflow-Angriffe bleiben eine kritische Bedrohung im Bereich der Softwaresicherheit. Entwickler können ihre Software vor Angriffen schützen, indem sie Buffer-Overflows und ihre Ausnutzung durch Angreifer verstehen.
Es ist wichtig, sichere Programmierpraktiken zu verwenden. Diese Praktiken umfassen Eingabevalidierung und sichere Speicherfunktionen. Sie helfen dabei, Buffer-Overflow-Schwachstellen in Systemen zu verhindern. Die Verwendung speichersicherer Programmiersprachen und das Aktualisieren von Software-Abhängigkeiten weiter erhöht die Resilienz von Softwaresystemen.
Softwareentwickler können die Sicherheit digitaler Systeme verbessern, indem sie Buffer-Overflows verhindern und auf neue Bedrohungen achten. Dies schützt Daten und stellt sicher, dass Computersysteme zuverlässig bleiben.
Nächste
