
Nutzung des Redshift-Informationsschemas zur Verbesserung der Datenbankleistung

Einführung
Dieser Artikel befasst sich mit dem Redshift-Datenbankschema, insbesondere mit der Implementierung des Informationsschemas. Wir werden untersuchen, wie es im Vergleich zu ähnlichen Tools in anderen Datenbanksystemen wie Microsoft SQL Server und PostgreSQL steht. Am Ende dieses Leitfadens werden Sie ein solides Verständnis davon haben, wie Sie die Systemtabellen von Redshift nutzen können, um Ihre Datenmanagement-Strategien zu optimieren.
Was ist ein Informationsschema in MS SQL Server?
Bevor wir in die spezifischen Details von Redshift eintauchen, beginnen wir mit einem vertrauten Referenzpunkt: dem Informationsschema von Microsoft SQL Server.
Grundlagen verstehen
Im MS SQL Server ist das Informationsschema eine Reihe von Ansichten, die Metadaten zu den Objekten in einer Datenbank bereitstellen. Es ist eine standardisierte Möglichkeit, Informationen über Tabellen, Spalten, Ansichten und andere Datenbankobjekte zuzugreifen.
Beispielsweise könnten Sie zum Anzeigen aller Tabellen in einer Datenbank mithilfe des Informationsschemas von MS SQL Server eine Abfrage wie diese verwenden:
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE';
Diese Abfrage würde eine Liste aller Basistabellen in der aktuellen Datenbank zurückgeben.
Redshift-Datenbankschema: Informationstools
Wenden wir uns nun Redshift zu, einem Datenspeicher von Amazon Web Services im Petabyte-Bereich. Obwohl Redshift auf PostgreSQL basiert, hat es seine eigenen Systemtabellen und Ansichten, die einen ähnlichen Zweck wie das Informationsschema in anderen Datenbanksystemen erfüllen.
Systemtabellen in Redshift
Redshift bietet eine Reihe von Systemtabellen, die Metadaten über die Cloud-Daten, ihre Tabellen und andere Objekte speichern. Diese Systemtabellen sind mit „PG_“, „STL_“, „STV_“ oder „SVV_“ vorangestellt.
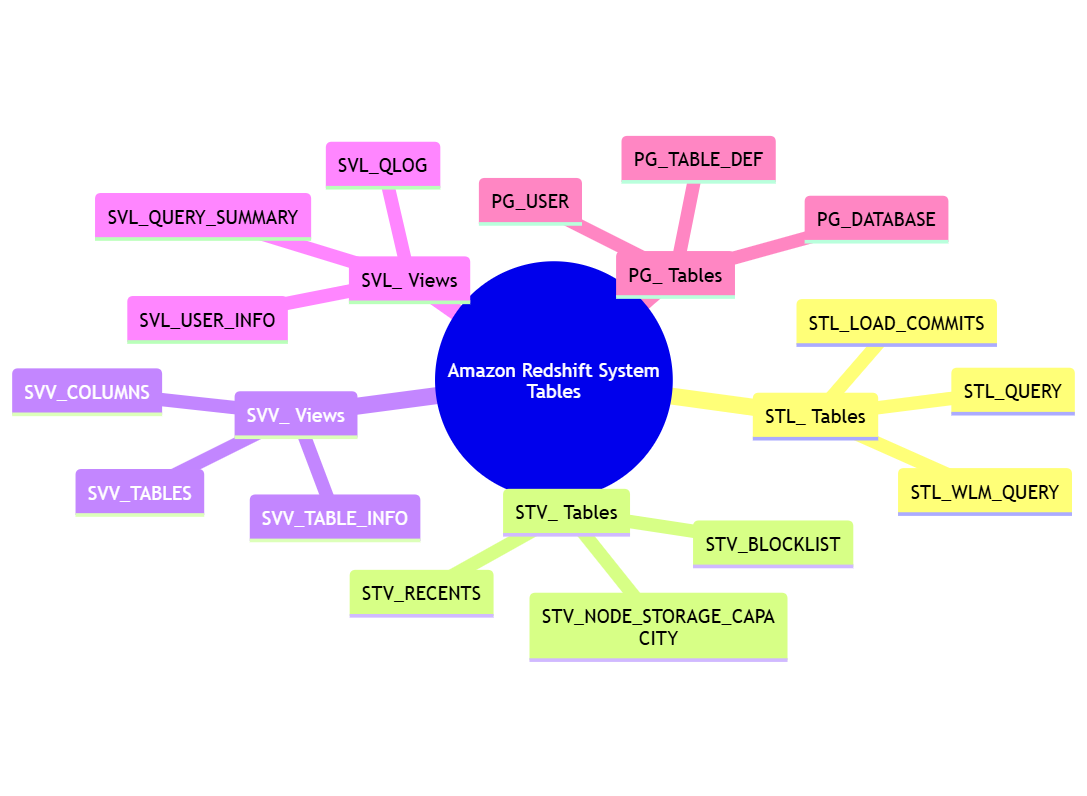
Hier sind einige wichtige Systemtabellen in Redshift:
- PG_TABLE_DEF: Enthält Informationen über Tabellendefinitionen.
- SVV_COLUMNS: Bietet eine Ansicht aller Spalten in der Datenbank.
- SVV_TABLES: Bietet eine Ansicht aller Tabellen in der Datenbank.
Sehen wir uns ein Beispiel an, wie diese Tabellen verwendet werden können:
SELECT tablename, "column", type, encoding FROM pg_table_def WHERE schemaname = 'public';
Diese Abfrage liefert Informationen zu allen Spalten in Tabellen im Schema ‘public’, einschließlich ihrer Namen, Datentypen und Codierung.
Abfragen des Redshift-Datenbankschemas
Um eine umfassende Ansicht Ihres Redshift-Datenbankschemas zu erhalten, können Sie Abfragen verwenden, die Informationen aus mehreren Systemtabellen kombinieren. Hier ist ein Beispiel:
SELECT
n.nspname AS schema_name,
c.relname AS table_name,
a.attname AS column_name,
t.typname AS data_type
FROM
pg_catalog.pg_class c
JOIN
pg_catalog.pg_namespace n ON n.oid = c.relnamespace
JOIN
pg_catalog.pg_attribute a ON a.attrelid = c.oid
JOIN
pg_catalog.pg_type t ON t.oid = a.atttypid
WHERE
c.relkind = 'r' -- Only regular tables
AND n.nspname NOT IN ('pg_catalog', 'information_schema')
AND a.attnum > 0 -- Exclude system columns
ORDER BY
schema_name, table_name, a.attnum;Diese Abfrage liefert eine detaillierte Ansicht Ihres Redshift-Datenbankschemas, einschließlich Schema-Namen, Tabellen-Namen, Spalten-Namen und Datentypen.
Vergleich von Redshift und PostgreSQL Informationstools
Da Redshift auf PostgreSQL basiert, ist es naheliegend, über die Ähnlichkeiten und Unterschiede ihrer Informationsschema-Tools nachzudenken.
PostgreSQL-Informationsschema
PostgreSQL verfügt, ähnlich wie MS SQL Server, über ein INFORMATION_SCHEMA, das dem SQL-Standard entspricht. Es bietet Ansichten, die Informationen zu allen Datenbankobjekten liefern.
Zum Beispiel könnten Sie zur Auflistung aller Tabellen in PostgreSQL diese Abfrage verwenden:
SELECT table_name FROM information_schema.tables WHERE table_schema = 'public';
Redshift vs. PostgreSQL
Obwohl Redshift auf PostgreSQL basiert, enthält es nicht das standardmäßige INFORMATION_SCHEMA. Stattdessen bietet es seine eigenen Systemtabellen und Ansichten. Dies liegt an der spezialisierten Natur von Redshift als spaltenarmer Datenspeicher, der andere Optimierungs- und Verwaltungstools benötigt.
Viele Konzepte sind jedoch ähnlich. Während PostgreSQL beispielsweise über information_schema.tables verfügt, hat Redshift SVV_TABLES. Beide bieten Metadaten zu den Tabellen in der Datenbank, aber die spezifischen verfügbaren Informationen und wie darauf zugegriffen wird, können sich unterscheiden.
Nutzung der Systemtabellen von Redshift zur Leistungsoptimierung
Das Verständnis der Systemtabellen von Redshift kann Ihnen helfen, die Leistung Ihrer Datenbank zu optimieren. Schauen wir uns einige praktische Anwendungen an.
Identifizierung von Tabellenschiefen
Tabellenschiefen treten auf, wenn Daten ungleichmäßig über die Slices in Redshift verteilt sind. Dies kann zu Leistungsproblemen führen. Sie können Systemtabellen verwenden, um Schiefen zu erkennen:
SELECT
trim(name) AS table,
slice,
count(*) AS num_values,
cast(100 * ratio_to_report(count(*)) over () AS decimal(5,2)) AS pct_of_total
FROM svv_diskusage
WHERE name IN ('your_table_name')
GROUP BY name, slice
ORDER BY name, slice;Diese Abfrage zeigt die Datenverteilung über die Slices für eine bestimmte Tabelle und hilft Ihnen, potenzielle Schiefenprobleme zu identifizieren.
Überwachung der Abfrageleistung
Die Tabellen STL_QUERY und SVL_QUERY_SUMMARY von Redshift können Ihnen helfen, die Abfrageleistung zu überwachen:
SELECT q.query, q.starttime, q.endtime, q.elapsed/1000000 AS elapsed_seconds, s.segment, s.step, s.maxtime/1000000 AS step_seconds, s.rows, s.bytes FROM stl_query q JOIN svl_query_summary s ON q.query = s.query WHERE q.starttime >= DATEADD(hour, -1, GETDATE()) ORDER BY q.query, s.segment, s.step;
Diese Abfrage liefert detaillierte Informationen zu Abfragen, die in der letzten Stunde ausgeführt wurden, einschließlich ihrer Ausführungszeit und Ressourcennutzung.
Best Practices für die Nutzung des Redshift-Informationsschemas
Um das Beste aus den Systemtabellen und Ansichten von Redshift herauszuholen, sollten die folgenden Best Practices berücksichtigt werden:
- Überwachen Sie regelmäßig die Tabellenstatistiken mithilfe von SVV_TABLE_INFO, um sicherzustellen, dass Ihre Tabellen optimiert sind.
- Verwenden Sie STL_ALERT_EVENT_LOG, um Leistungsprobleme proaktiv zu identifizieren und zu beheben.
- Nutzen Sie SVV_VACUUM_PROGRESS, um VACUUM-Operationen zu überwachen und zu verwalten.
- Verwenden Sie SVV_DATASHARE_OBJECTS, um die Datenfreigabe über Redshift-Cluster hinweg zu verwalten.
Denken Sie daran, dass häufige Abfragen dieser Systemtabellen die Leistung beeinträchtigen können. Nutzen Sie sie daher sparsam und ziehen Sie in Erwägung, Ergebnisse bei Bedarf zwischenspeichern.
Fazit
Das Verständnis und die effektive Nutzung der Informationsschema-Tools von Redshift sind entscheidend für die Verwaltung und Optimierung Ihres Datenspeichers. Obwohl es sich von dem standardmäßigen INFORMATION_SCHEMA in SQL Server und PostgreSQL unterscheidet, bieten die Systemtabellen und Ansichten von Redshift leistungsstarke Funktionen zur Überwachung, Fehlerbehebung und Optimierung Ihrer Datenbank.
Durch die Nutzung dieser Tools können Sie tiefe Einblicke in Ihr Redshift-Datenbankschema gewinnen, die Leistung überwachen und fundierte Entscheidungen über Datenmanagement und Abfrageoptimierung treffen. Wie bei jedem leistungsstarken Werkzeug sollten Sie diese Möglichkeiten weise nutzen, um das Sammeln von Erkenntnissen mit der Gesamtleistung des Systems auszubalancieren.
Für diejenigen, die fortschrittliche Datenbanksicherheits- und Compliance-Tools suchen, sollten Sie einen Blick auf DataSunrise werfen. Unsere benutzerfreundlichen und flexiblen Lösungen bieten umfassenden Datenschutz. Besuchen Sie unsere Website für eine Online-Demo und erfahren Sie, wie Sie Ihre Datensicherheit noch heute verbessern können.
