
Wie man statische Datenmaskierung in Amazon DynamoDB implementiert
Einführung
Im Jahr 2022 machten cloudbasierte Lösungen 53 % des globalen DLP-Softwaremarktes aus, wobei das Marktwachstum insgesamt eine nicht-lineare Expansion aufwies. Amazon DynamoDB, ein beliebter NoSQL-Datenbankdienst, speichert große Mengen an Daten, einschließlich potenziell sensibler Informationen. Statische Datenmaskierung bietet eine leistungsstarke Lösung, um diese Daten zu schützen. Lassen Sie uns erkunden, wie statische Datenmaskierung für Amazon DynamoDB implementiert werden kann, wobei der Schwerpunkt auf praktischen Techniken und Werkzeugen liegt.
Führende DLP-Anbieter priorisieren die Entwicklung von cloud-nativen und cloud-kompatiblen Lösungen, um der steigenden Nachfrage gerecht zu werden. Bei DataSunrise sind wir mit diesen Branchentrends bestens vertraut und bieten moderne Lösungen an, die darauf ausgelegt sind, cloudbasierte Dateninfrastrukturen effektiv zu schützen.
Verstehen der statischen Datenmaskierung
Statische Datenmaskierung ist eine Sicherheitstechnik, die sensible Daten durch realistische, aber fiktive Informationen ersetzt. Im Gegensatz zur dynamischen Maskierung, die in Echtzeit erfolgt, verändert die statische Maskierung die Daten dauerhaft im Ruhezustand. Dieser Ansatz eignet sich ideal zur Erstellung sicherer, nicht-produktiver Umgebungen für Tests und Entwicklung.
Vorteile der statischen Datenmaskierung
- Verbesserte Datensicherheit
- Einhaltung von Datenschutzvorschriften
- Reduziertes Risiko von Datenverletzungen
- Sichere Umgebung für Entwicklung und Tests
Native Maskierungsfunktionen bei Amazon DynamoDB
Amazon DynamoDB bietet native Maskierungsfunktionen, die wir in unseren früheren Artikeln zur Maskierung und dynamischen Maskierung für DynamoDB behandelt haben. Diese Funktionen ermöglichen die Nachbearbeitung von Abfrageergebnissen nach dem Abrufen von Daten mithilfe der Python-API oder CLI.
Implementierung von statischer Datenmaskierung mit Python und Boto3
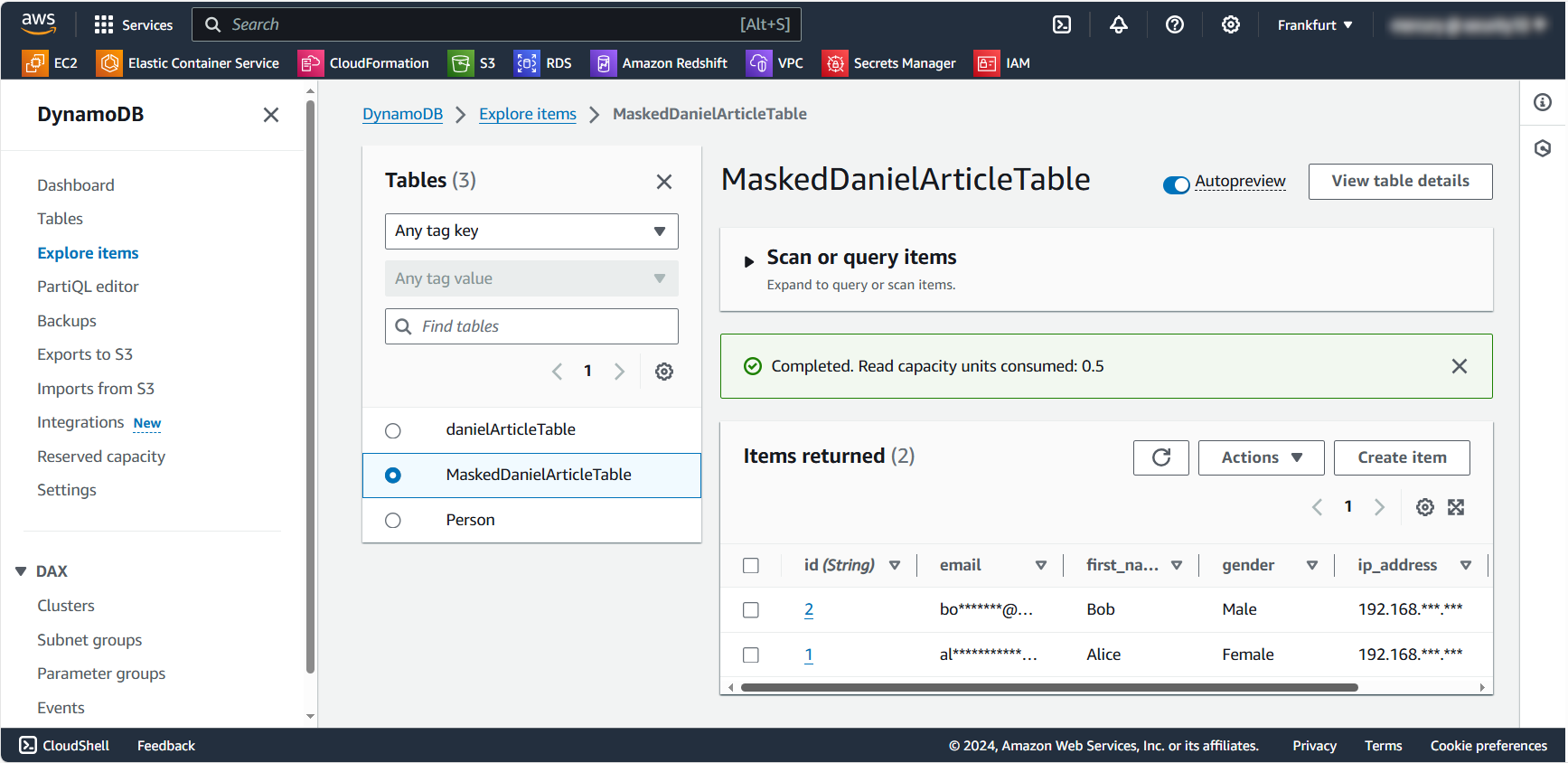
Lassen Sie uns ein praktisches Beispiel für statische Datenmaskierung mit Python und der Boto3-Bibliothek erkunden. Wir werden uns mit der Datenbank verbinden, eine Kopie der Daten erstellen (MaskedDanielArticleTable-Tabelle) und sensible Informationen wie E-Mail-Adressen und IPs maskieren.
import boto3
from boto3.dynamodb.conditions import Key
import time
# Verbindung zu DynamoDB herstellen
dynamodb = boto3.resource('dynamodb')
source_table = dynamodb.Table('danielArticleTable')
# Die maskierte Tabelle erstellen
try:
masked_table = dynamodb.create_table(
TableName='MaskedDanielArticleTable',
KeySchema=[
{'AttributeName': 'id', 'KeyType': 'HASH'},
],
AttributeDefinitions=[
{'AttributeName': 'id', 'AttributeType': 'S'},
],
ProvisionedThroughput={
'ReadCapacityUnits': 5,
'WriteCapacityUnits': 5
}
)
print("Die maskierte Tabelle wird erstellt...")
masked_table.meta.client.get_waiter('table_exists').wait(TableName='MaskedDanielArticleTable')
print("Maskierte Tabelle erfolgreich erstellt")
except dynamodb.meta.client.exceptions.ResourceInUseException:
print("Die maskierte Tabelle existiert bereits")
masked_table = dynamodb.Table('MaskedDanielArticleTable')
# Funktion zum Maskieren von E-Mails
def mask_email(email):
username, domain = email.split('@')
masked_username = username[:2] + '*' * (len(username) - 2)
return f"{masked_username}@{domain}"
# Funktion zum Maskieren von IP-Adressen
def mask_ip(ip):
octets = ip.split('.')
masked_octets = octets[:2] + ['***', '***']
return '.'.join(masked_octets)
# Die Quelltabelle scannen
response = source_table.scan()
items = response['Items']
# Daten maskieren und kopieren
for item in items:
masked_item = item.copy()
if 'email' in masked_item:
masked_item['email'] = mask_email(masked_item['email'])
if 'ip_address' in masked_item:
masked_item['ip_address'] = mask_ip(masked_item['ip_address'])
# Das maskierte Element in die neue Tabelle einfügen
masked_table.put_item(Item=masked_item)
print("Statische Datenmaskierung abgeschlossen.")Die Ausgabe (ausgeführt in einem Jupyter Notebook) sieht wie folgt aus:
Dieses Skript demonstriert einen grundlegenden Ansatz zur statischen Datenmaskierung. Es erstellt eine neue Tabelle mit maskierten Daten, wodurch sichergestellt wird, dass die ursprünglichen sensiblen Informationen geschützt bleiben.
Bevor wir fortfahren, ist es wichtig, einige Schlüsselpunkte zum bereitgestellten Code anzusprechen. Die flexible Schema-Natur von DynamoDB stellt einzigartige Herausforderungen für die automatisierte statische Datenmaskierung dar. Lassen Sie uns diese Komplexitäten untersuchen:
- Verschiedene Elemente in derselben Tabelle können unterschiedliche Attribute aufweisen.
- Neue Attribute können jederzeit zu Elementen hinzugefügt werden, ohne die Tabellenstruktur ändern zu müssen.
Um diesen Herausforderungen zu begegnen:
- Implementieren Sie flexible Maskierungsregeln, die sich an unterschiedliche Datenstrukturen anpassen können.
- Verwenden Sie Mustererkennung oder maschinelles Lernen, um potenziell sensible Daten zu identifizieren.
- Führen Sie einen umfassenden Katalog sensibler Datenmuster und -standorte.
- Verwenden Sie Stichprobenverfahren, um große Datensätze effizient zu verarbeiten.
Statische Datenmaskierung mit DataSunrise
Die aktuelle Version von DataSunrise (10.0) bietet vollwertige dynamische Maskierung für DynamoDB, unterstützt jedoch keine statische Maskierung für diese Datenbank. Für einen umfassenden Überblick über unterstützte Datenbanken und Funktionen konsultieren Sie bitte Kapitel 1.2, ‘Unterstützte Datenbanken und Funktionen’, in unserer Dokumentation. Folglich sind DynamoDB-Instanzen bei der Einrichtung einer statischen Maskierungsaufgabe nicht in den Quell- und Zieldatenbanklisten verfügbar.
Best Practices für statische Datenmaskierung in DynamoDB
Um die Effektivität Ihrer Maßnahmen zur statischen Datenmaskierung zu maximieren:
- Identifizieren Sie alle sensiblen Daten-Attribute
- Verwenden Sie realistische Maskierungstechniken, um die Datenverwendbarkeit zu erhalten
- Aktualisieren Sie regelmäßig die Maskierungsregeln, um neue Datentypen zu berücksichtigen
- Implementieren Sie Zugriffskontrollen für maskierte Daten
- Überwachen Sie die Maskierungsprozesse, um deren Wirksamkeit sicherzustellen
Herausforderungen und Überlegungen
Während die statische Datenmaskierung erhebliche Vorteile bietet, ist es wichtig, potenzielle Herausforderungen zu berücksichtigen:
- Leistungsbeeinträchtigung während des Maskierungsprozesses
- Aufrechterhaltung der referenziellen Integrität in maskierten Datensätzen
- Sicherstellung, dass maskierte Daten für Tests und Entwicklung brauchbar bleiben
- Aktualisierung der Maskierungsregeln und -aufgaben bei sich ändernden Datenstrukturen
Fazit
Statische Datenmaskierung für Amazon DynamoDB bietet ein leistungsstarkes Werkzeug zum Schutz sensibler Informationen. Durch die Implementierung robuster Maskierungstechniken können Organisationen das Risiko von Datenverletzungen erheblich reduzieren und die Einhaltung von Datenschutzvorschriften sicherstellen.
Egal, ob Sie native DynamoDB-Funktionen, benutzerdefinierte Python-Skripte oder spezialisierte Werkzeuge verwenden, die statische Datenmaskierung bietet einen flexiblen und effektiven Ansatz zum Schutz Ihrer wertvollen Datenbestände.
DataSunrise bietet eine umfassende Suite von Datenbanksicherheitstools, einschließlich fortschrittlicher Prüfungs- und Konformitätsfunktionen. Unsere modernen Lösungen bieten flexible und leistungsstarke Optionen zum Schutz Ihrer sensiblen Daten über verschiedenste Datenbankplattformen hinweg. Besuchen Sie unsere Website, um eine Online-Demo zu vereinbaren und zu erfahren, wie DataSunrise Ihre Datensicherheitsstrategie verbessern kann.
