
Datensicherheit durch statische Datenmaskierung in MongoDB gewährleisten

Einführung
In unserer zunehmend datengetriebenen Welt ist der Schutz unserer wertvollen Datenressourcen von größter Bedeutung. Da Organisationen große Mengen an Informationen sammeln und verarbeiten, ist der Schutz sensibler Daten heute wichtiger denn je. Organisationen, die personenbezogene Daten verarbeiten, müssen strenge Vorschriften einhalten und gleichzeitig die Datenintegrität für Entwicklungs- und Testzwecke aufrechterhalten. Statische Datenmaskierung für MongoDB bietet eine leistungsstarke Lösung für diese Herausforderung.
Wussten Sie, dass laut einem Bericht der IBM-Experten im Jahr 2024 eine besorgniserregende Tendenz bei den Ursachen von Datenlecks zu beobachten ist? Erstaunliche 55 % der Verstöße resultieren aus böswilligen Angriffen, während IT-Systemausfälle 23 % ausmachen, und menschliches Versagen trägt zu den verbleibenden 22 % der Vorfälle bei. Diese erstaunliche Zahl unterstreicht die Bedeutung robuster Daten Schutzmaßnahmen. Lassen Sie uns erkunden, wie die statische Datenmaskierung Ihre MongoDB-Datenbanken schützen kann.
Verstehen der statischen Datenmaskierung
Was ist statische Datenmaskierung?
Statische Datenmaskierung ist ein Prozess, der eine separate, bereinigte Kopie einer Datenbank erstellt. Es ersetzt sensible Daten durch fiktive, aber realistische Informationen. Diese Technik ermöglicht es Organisationen, maskierte Daten in Nicht-Produktionsumgebungen zu verwenden, ohne das Risiko der Offenlegung vertraulicher Informationen.
Die Bedeutung der Datenmaskierung
Datenmaskierung ist entscheidend für:
- Schutz der Privatsphäre der Kunden
- Einhaltung von Vorschriften wie GDPR und CCPA
- Verhinderung von Datenlecks in Nicht-Produktionsumgebungen
- Ermöglichung des sicheren Datenaustauschs mit Dritten
Fähigkeiten von MongoDB zur statischen Datenmaskierung
MongoDB bietet integrierte Funktionen für grundlegende Datenmaskierung. Diese Fähigkeiten sind zwar nicht so umfassend wie spezialisierte Werkzeuge, können aber für einfache Maskierungsaufgaben nützlich sein.
Verwendung des $redact-Operators von MongoDB
Der $redact-Operator von MongoDB ermöglicht es Ihnen, Felder in Dokumenten selektiv zu entfernen oder zu ersetzen. Hier ein einfaches Beispiel:
db.collection.aggregate([
{
$redact: {
$cond: {
if: { $eq: [ "$sensitive_field", true ] },
then: "$$PRUNE",
else: "$$DESCEND"
}
}
}
])Dieser Befehl entfernt alle als sensibel markierten Felder aus den Dokumenten.
Erstellen einer maskierten Kopie einer Datenbank
Um eine neue Datenbank mit maskierten Datenkopien zu erstellen:
Erstellen Sie eine neue Datenbank:
use masked_database
Daten kopieren und maskieren:
db.source_collection.aggregate([
{
$project: {
_id: 1,
masked_field: { $concat: ["MASKED-", { $substr: ["$sensitive_field", 0, 4] }] },
// Weitere Felder hier hinzufügen
}
},
{ $out: "masked_collection" }
])Dieses Beispiel maskiert ein sensibles Feld durch Ersetzen mit einem “MASKED-” Präfix und den ersten vier Zeichen des Originalwerts.
Erweiterte statische Datenmaskierung mit DataSunrise
Während die nativen Fähigkeiten von MongoDB nützlich sind, erfüllen sie möglicherweise nicht alle Anforderungen an eine umfassende Datenmaskierung. Hier kommen spezialisierte Werkzeuge wie DataSunrise ins Spiel.
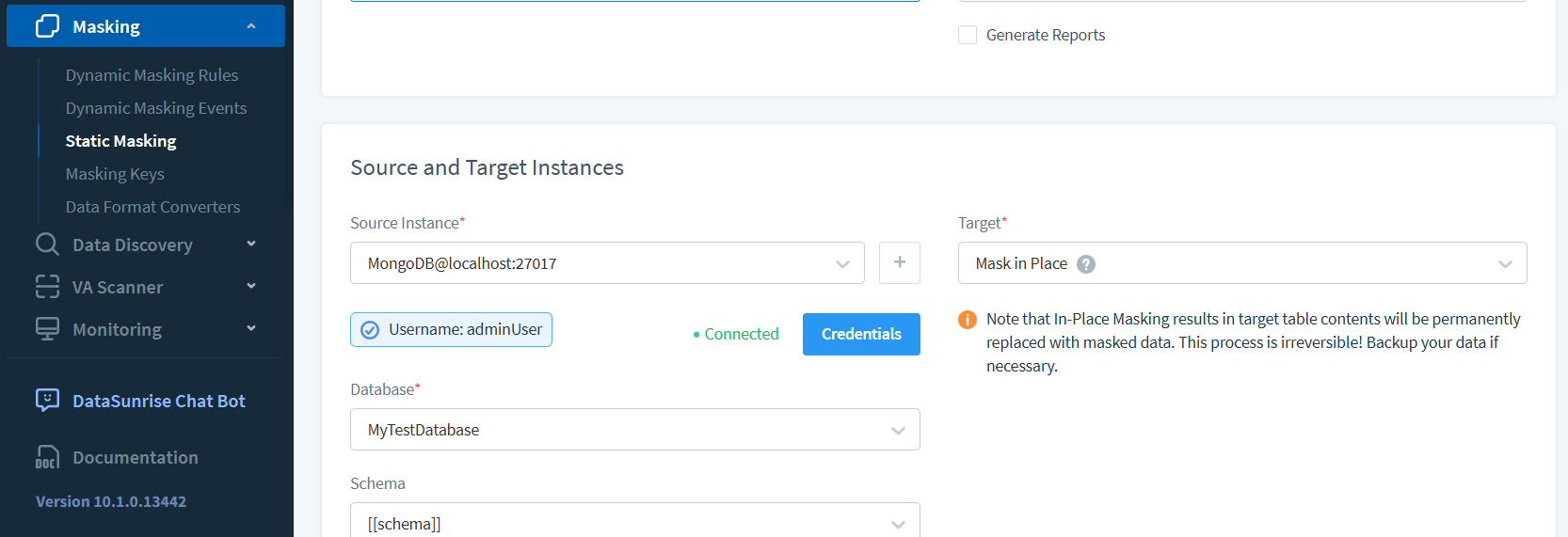
Erstellen einer DataSunrise-Instanz für Quell- und Zielbasen
Setup einer DataSunrise-Instanz:
- Verbindung zu Ihren MongoDB-Instanzen herstellen
- Einstellungen testen und speichern
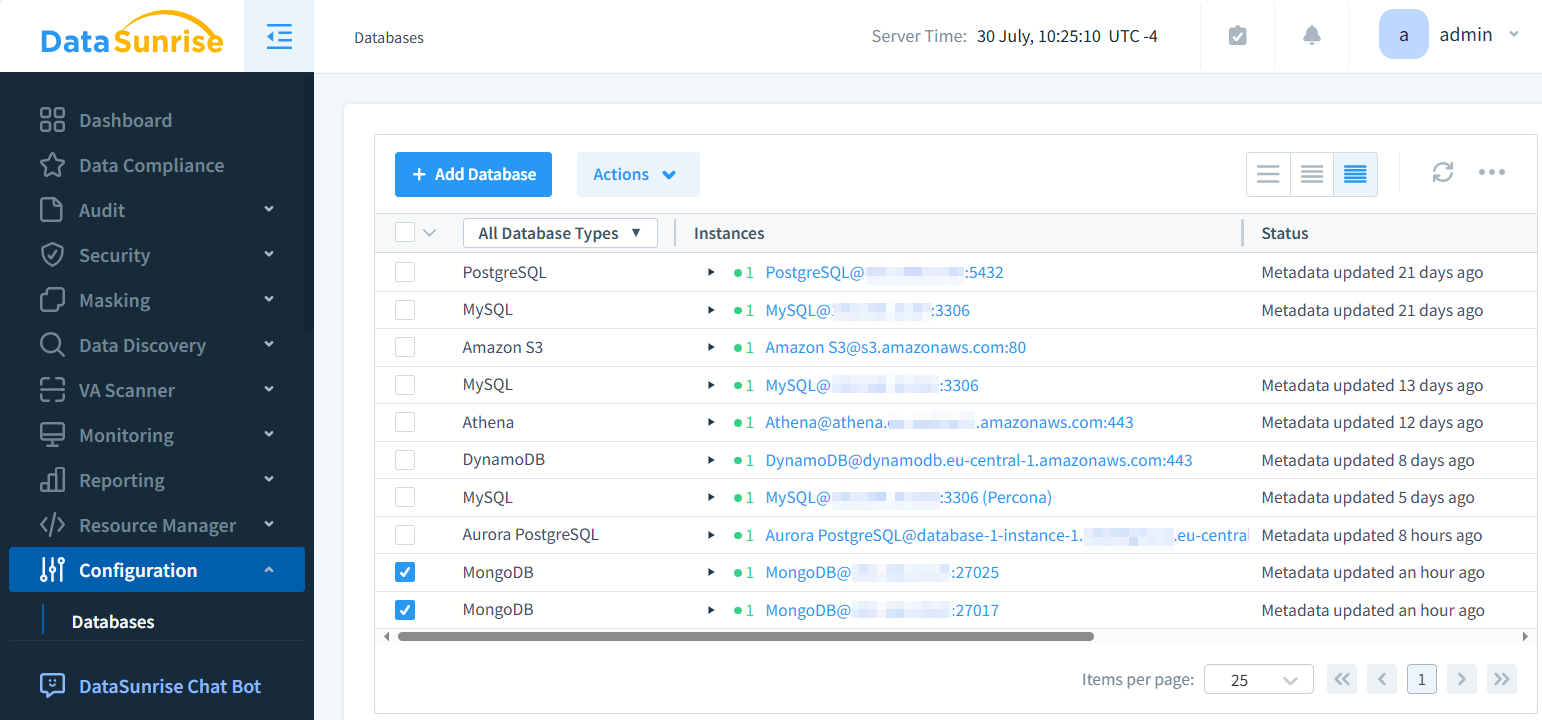
Die Abbildung unten zeigt die zwei MongoDB-Instanzen, die wir zur statischen Maskierung vorbereitet haben.
Anzeigen von statisch maskierten Daten
Sobald konfiguriert, erstellt DataSunrise eine maskierte Kopie Ihrer Datenbank. Um die maskierten Daten anzuzeigen:
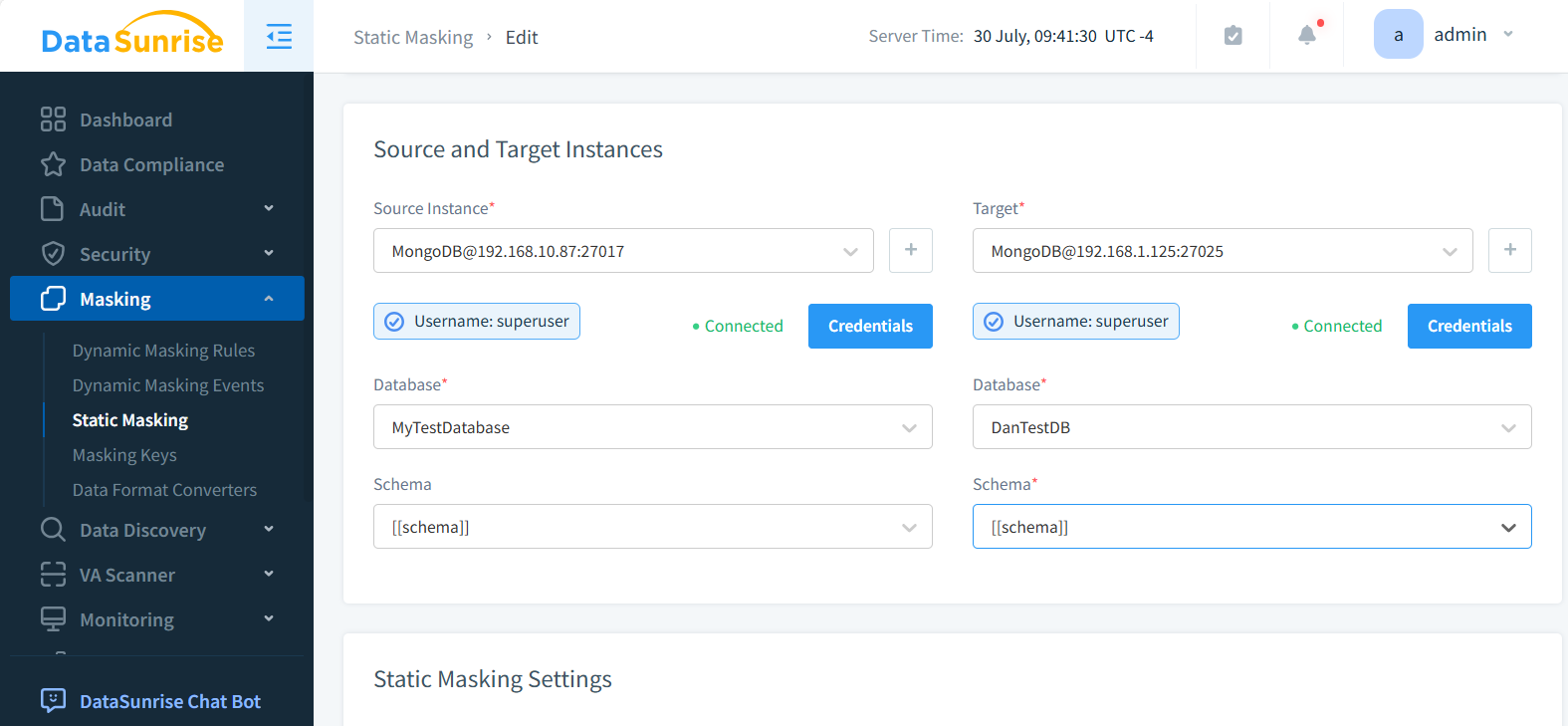
- Richten Sie eine statische Maskierungsaufgabe mit den zuvor erstellten Instanzen ein.
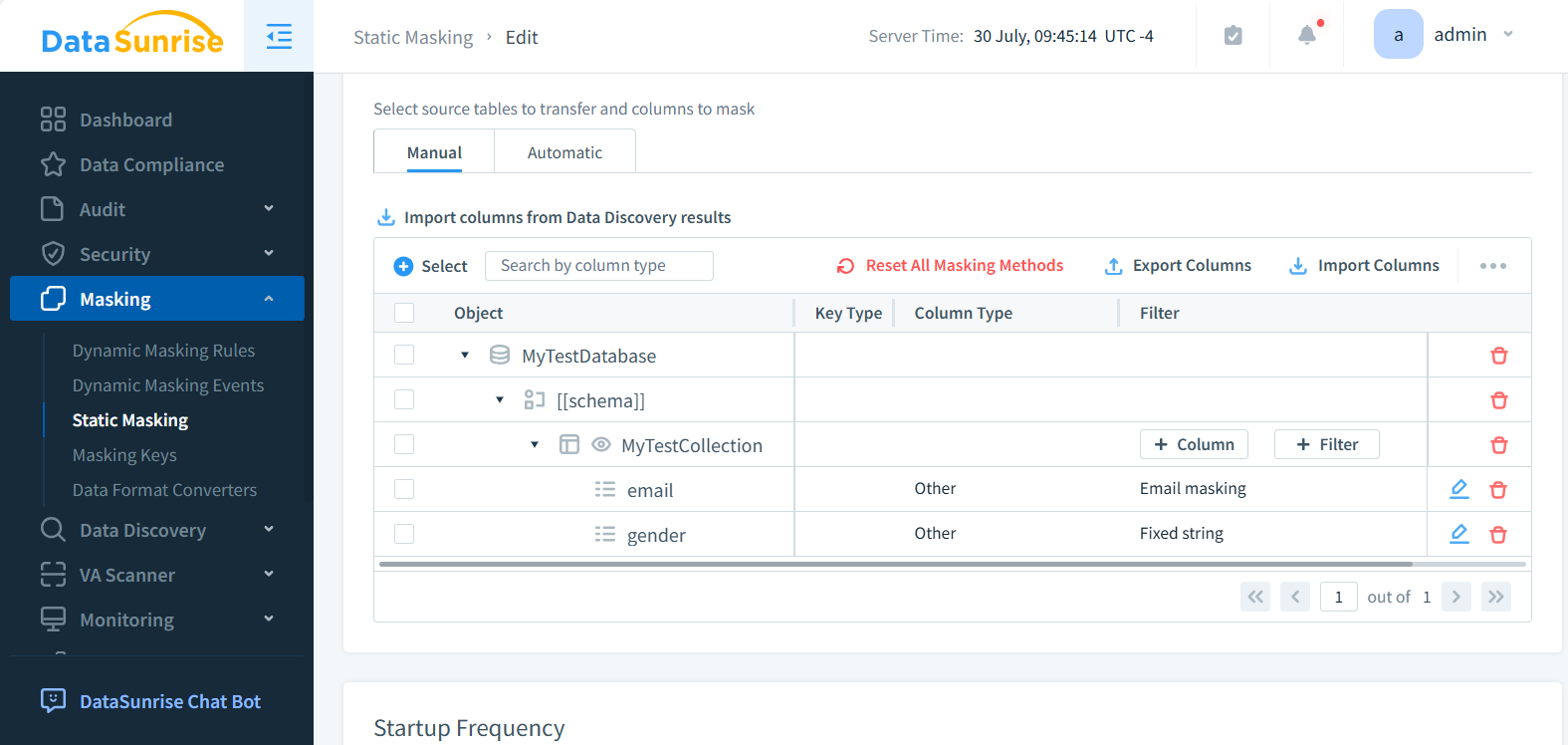
- Wählen Sie die zu maskierenden Daten und Maskierungsmethoden.
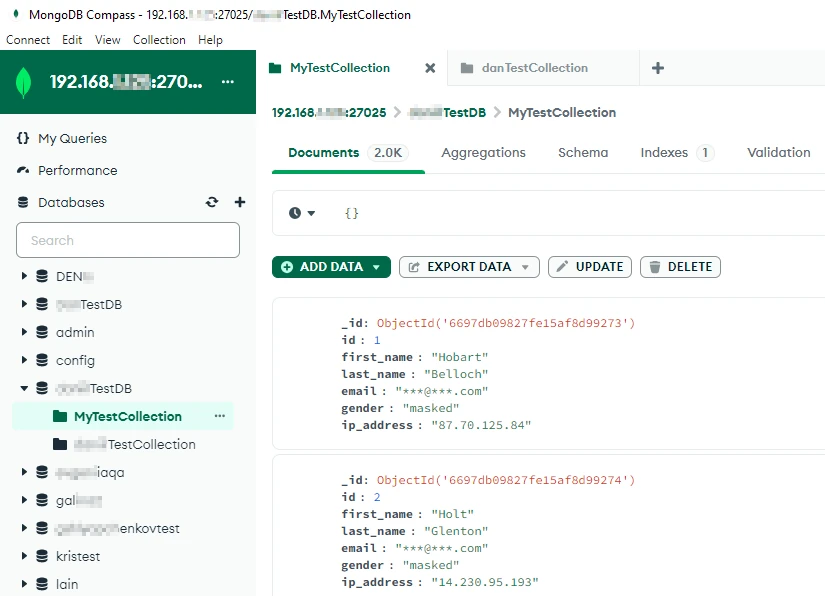
- Speichern und führen Sie die Aufgabe aus. Dann fragen Sie die Zieldatenbank ab. Sie sollte maskierte Daten enthalten:
Dieser Artikel führt auch die in-place-Maskierung von MongoDB ein, eine wichtige Verbesserung des zuvor veröffentlichten Artikels.
DataSunrise bietet fortschrittlichere Maskierungstechniken wie:
- Konsistente Maskierung über verwandte Felder hinweg
- Bewahrung des Datenformats und der referenziellen Integrität
- Anpassbare Maskierungsalgorithmen
Vorteile der statischen Datenmaskierung für MongoDB
Verbesserte Datensicherheit
Statische Datenmaskierung reduziert das Risiko der Offenlegung sensibler Informationen erheblich. Sie ermöglicht die Verwendung realistischer Daten in Nicht-Produktionsumgebungen, ohne die Vertraulichkeit zu gefährden.
Regulatorische Compliance
Im heutigen digitalen Zeitalter ist der Schutz personenbezogener Daten für Organisationen in verschiedenen Branchen zu einer obersten Priorität geworden. Da mehr Regeln zum Schutz der Datenprivatsphäre erstellt werden, müssen Organisationen Maßnahmen ergreifen, um sensible Informationen sicher zu halten. Dies umfasst die Einhaltung von Gesetzen wie GDPR und CCPA.
Durch die Implementierung der statischen Datenmaskierung können Organisationen die regulatorischen Anforderungen einhalten und das Risiko von Datenlecks oder unbefugtem Zugriff auf personenbezogene Informationen mindern. Dies hilft nicht nur, die Privatsphäre der Einzelpersonen zu schützen, sondern auch den Ruf der Organisation und mögliche rechtliche Konsequenzen zu vermeiden.
Statische Datenmaskierung ist wichtig für Organisationen, um persönliche Daten zu schützen, während sie dennoch realistische Tests und Entwicklungen ermöglichen. Sie hilft, das Bedürfnis nach Privatsphäre mit dem Bedarf an effektiver Datenverwaltung in Einklang zu bringen.
Verbesserte Entwicklung und Tests
Mit maskierten Daten können Entwickler und Tester mit realistischen Datensätzen arbeiten, ohne das Risiko, sensible Informationen versehentlich offenzulegen. Dies führt zu genaueren Tests und besserer Qualitätssicherung.
Best Practices für statische Datenmaskierung
- Die Identifizierung aller sensiblen Daten Felder ist entscheidend, um sensible Informationen wirksam zu schützen. Dazu gehören persönlich identifizierbare Informationen (PII) wie Namen, Adressen, Sozialversicherungsnummern und Finanzinformationen. Sobald diese sensiblen Datenfelder identifiziert wurden, ist es wichtig, geeignete Maskierungstechniken für jeden Datentyp auszuwählen. Maskierungstechniken können Techniken wie Verschlüsselung, Tokenisierung oder Datenanonymisierung umfassen.
- Es ist auch wichtig, Konsistenz über verwandte Felder hinweg zu gewährleisten, wenn Daten maskiert werden. Wenn bestimmte Datenfelder verbunden sind, sollten sie auf die gleiche Weise verborgen werden, um die Genauigkeit der Daten zu gewährleisten.
- Die regelmäßige Aktualisierung der Maskierungsregeln zur Bewältigung neuer Datentypen ist unerlässlich, um potenziellen Sicherheitsbedrohungen einen Schritt voraus zu sein. Da neue Arten von Daten entstehen, ist es wichtig, die Maskierungsmethoden zu überprüfen und zu verbessern, um sicherzustellen, dass alle sensiblen Daten geschützt sind.
- Es ist wichtig, die referenzielle Integrität in maskierten Datensätzen aufrechtzuerhalten. Dadurch bleibt die Beziehung zwischen Datenelementen auch nach der Maskierung intakt. Dies hilft, die Genauigkeit und Nutzbarkeit der Daten zu gewährleisten.
- Die Implementierung von Zugangskontrollen für maskierte Datenbanken ist entscheidend, um sicherzustellen, dass nur autorisierte Benutzer Zugang zu sensiblen Informationen haben. Richten Sie Zugangskontrollen ein, um zu beschränken, wer maskierte Daten sehen oder ändern darf. Nur Personen mit den entsprechenden Berechtigungen sollten darauf zugreifen können.
Herausforderungen und Überlegungen
Obwohl die statische Datenmaskierung viele Vorteile bietet, gibt es einige Herausforderungen zu beachten:
- Performance-Einbußen während des Maskierungsprozesses
- Aufrechterhaltung von Datenbeziehungen und -integrität
- Sicherstellen, dass maskierte Daten für Tests nützlich bleiben
- Die Maskierungsregeln an die sich ändernden Datenstrukturen anpassen
Zukunftstrends in der Datenmaskierung
Da der Datenschutz immer wichtiger wird, können wir Folgendes erwarten:
- Fortschrittlichere, KI-gesteuerte Maskierungstechniken
- Integration der Datenmaskierung mit anderen Sicherheitsmaßnahmen
- Erhöhter Fokus auf dynamische Datenmaskierung für Echtzeitschutz
Fazit
Statische Datenmaskierung für MongoDB ist ein leistungsstarkes Werkzeug zum Schutz sensibler Daten und zur Sicherstellung der Einhaltung von Vorschriften. Durch die Erstellung bereinigter Kopien von Datenbanken können Organisationen vertrauliche Informationen schützen und gleichzeitig realistische Daten für Entwicklungs- und Testzwecke nutzen. Die Implementierung der statischen Datenmaskierung ist wichtig für Datenmanagement- und Sicherheitsstrategien.
Dies kann durch die eingebauten Funktionen von MongoDB oder Werkzeuge wie DataSunrise erfolgen. Statische Datenmaskierung hilft dabei, sensible Informationen durch fiktive Daten zu ersetzen und sicherzustellen, dass nur autorisierte Benutzer auf die echten Daten zugreifen können.
DataSunrise bietet benutzerfreundliche und flexible Werkzeuge für eine umfassende Datenbanksicherheit, einschließlich Prüfungs-, Maskierungs- und Datenerkennungsfunktionen. Um mehr darüber zu erfahren, wie DataSunrise den Schutz Ihrer MongoDB-Daten verbessern kann, besuchen Sie unsere Website für eine Online-Demo und erkunden Sie unser vollständiges Angebot an Sicherheitslösungen.
Nächste
