
Statische Datenmaskierung in Greenplum
Greenplum, ein leistungsstarkes Open-Source-Data Warehouse, bietet robuste Funktionen für das Verwalten und Analysieren großer Datensätze. Da Organisationen mit zunehmenden Mengen an sensiblen Informationen umgehen müssen, ist der Bedarf an effektiven Datenschutzmethoden von größter Bedeutung geworden. Die statische Datenmaskierung schützt sensible Informationen in Greenplum und ermöglicht gleichzeitig den Benutzern, diese für unterschiedliche Zwecke zu nutzen. Dieser Artikel untersucht das Konzept der statischen Datenmaskierung in Greenplum, ihre Vorteile, Herausforderungen und bewährten Praktiken für die Implementierung.
Statische Datenmaskierung: Definition und Vorteile
Die statische Datenmaskierung ist ein Prozess, der sensible Daten durch realistische, aber fiktive Informationen ersetzt. Diese Methode hilft Organisationen, ihre wichtigen Daten sicher zu halten und ermöglicht gleichzeitig die Verwendung der maskierten Daten für Tests, Entwicklung oder Analyse.
In Greenplum bietet die statische Datenmaskierung zusätzliche Sicherheit. Sie hält sensible Informationen privat, selbst wenn sie mit unautorisierten Benutzern geteilt oder in nicht-produktive Umgebungen verschoben werden.
Das Hauptziel der statischen Datenmaskierung besteht darin, eine Version der Daten zu erstellen, die wie das Original aussieht und sich verhält, aber keine sensiblen Informationen enthält.
Diese Methode ermöglicht es Organisationen, versteckte Daten für verschiedene Zwecke zu verwenden und gleichzeitig die ursprünglichen Daten sicher und privat zu halten.
Die Implementierung der statischen Datenmaskierung in Greenplum bietet mehrere bedeutende Vorteile:
Erhöhte Datensicherheit: Durch den Ersatz sensibler Informationen durch fiktive Daten können Organisationen das Risiko von Datenverletzungen erheblich reduzieren. Selbst wenn unautorisierte Benutzer Zugriff auf die maskierten Daten erhalten, können sie keine wertvollen oder sensiblen Informationen extrahieren.
Regulatorische Compliance: Viele Branchen unterliegen strengen Datenschutzbestimmungen wie GDPR, HIPAA oder PCI DSS. Die statische Datenmaskierung hilft Organisationen, diese Regeln einzuhalten, indem sie sicherstellt, dass sensible Daten nicht in nicht-produktiven Umgebungen erscheinen.
Verbesserte Tests und Entwicklung: Die statische Datenmaskierung ermöglicht es Organisationen, produktionsähnliche Daten in Test- und Entwicklungsumgebungen zu verwenden. Dieser Ansatz liefert genauere und zuverlässigere Testergebnisse. Entwickler und Tester können Daten verwenden, die realen Situationen ähneln, ohne dabei sensible Informationen zu gefährden.
Kosteneinsparungen: Das Verwenden maskierter Daten anstelle von synthetischen Datensätzen hilft Organisationen, insbesondere bei der Vorbereitung von Daten für nicht-produktive Zwecke. Diese Effizienz kann langfristig zu erheblichen Kosteneinsparungen führen.
Datenaustausch: Die statische Datenmaskierung ermöglicht es Organisationen, Daten mit Drittanbietern, Partnern oder Offshore-Entwicklungsteams zu teilen, ohne sensible Informationen preiszugeben. Diese Fähigkeit erleichtert die Zusammenarbeit bei gleichzeitiger Wahrung der Datensicherheit.
Herausforderungen und Techniken
Obwohl die statische Datenmaskierung zahlreiche Vorteile bietet, gibt es auch einige Herausforderungen, denen sich Organisationen stellen müssen:
Datenkonsistenz beibehalten: Eine der größten Herausforderungen besteht darin, sicherzustellen, dass maskierte Daten in verbundenen Tabellen konsistent bleiben. Um die referenzielle Integrität der Datenbank zu erhalten, müssen die Beziehungen zwischen verschiedenen Datenelementen beibehalten werden.
Nutzen der Daten beibehalten: Die maskierten Daten sollten die gleichen Muster und Merkmale wie die Originaldaten behalten, da dies für Analysen und Tests wichtig ist. Die richtige Balance zwischen Datenschutz und Datenverwendbarkeit zu finden, kann eine Herausforderung sein.
Leistungsanforderungen: Der Maskierungsprozess kann je nach verwendeter Technik und Datenmenge viel Zeit und Ressourcen in Anspruch nehmen. Organisationen müssen die Auswirkungen auf die Leistung ihrer Greenplum-Umgebung berücksichtigen.
Sensiblen Daten identifizieren: Das gründliche Identifizieren aller sensiblen Datenelemente innerhalb einer komplexen Datenbankstruktur kann eine entmutigende Aufgabe sein. Selbst das Übersehen eines einzigen sensiblen Feldes kann die gesamte Maskierungsbemühung gefährden.
Greenplum bietet verschiedene Methoden zur Implementierung der statischen Datenmaskierung, darunter integrierte Funktionen, Drittanbieter-Tools und benutzerdefinierte Skripte. Zu den in Greenplum häufig verwendeten Techniken zur statischen Datenmaskierung gehören:
Substitution: Diese Technik ersetzt sensible Daten durch realistische, aber fiktive Werte.
Durchmischung: Diese Methode randomisiert Werte innerhalb einer Spalte, behält dabei die statistischen Gesamteigenschaften der Daten bei und verschleiert gleichzeitig einzelne Datensätze. Dies ist besonders nützlich.
Verschlüsselung: Sie können sensible Daten mithilfe von Verschlüsselungsalgorithmen transformieren. Während diese Methode starken Schutz bietet, kann sie die Verwendbarkeit der Daten für bestimmte Zwecke einschränken.
Best Practices und Implementierung
Um die Effektivität der statischen Datenmaskierung in Greenplum zu maximieren, sollten Sie die folgenden Best Practices berücksichtigen:
Sensible Daten identifizieren: Analysieren Sie Ihre Greenplum-Datenbank gründlich, um alle sensiblen Datenelemente zu identifizieren. Dieser Schritt stellt sicher, dass der Maskierungsprozess keine vertraulichen Informationen übersieht.
Geeignete Maskierungstechniken auswählen: Wählen Sie Maskierungstechniken aus, die am besten zu Ihren Datentypen und Sicherheitsanforderungen passen. Unterschiedliche Datenelemente können unterschiedliche Maskierungsansätze erfordern, um die Datenintegrität und Verwendbarkeit zu erhalten.
Datenbeziehungen beibehalten: Wenn Sie Daten über mehrere Tabellen hinweg maskieren, stellen Sie sicher, dass die Beziehungen zwischen den Tabellen beibehalten werden. Dieser Schritt ist entscheidend, um die Konsistenz der Daten zu wahren und Probleme in Anwendungen zu vermeiden, die auf diese Beziehungen angewiesen sind.
Maskierungsregeln dokumentieren: Halten Sie klare Dokumentation aller Maskierungsregeln und -verfahren aufrecht. Diese Dokumentation sollte die maskierten Felder, die verwendeten Techniken sowie alle Ausnahmen oder Sonderfälle umfassen.
Erstellung einer separaten Tabelle mit maskierten Daten
Hier ist ein Beispiel, wie Sie eine separate Tabelle mit maskierten Daten in Greenplum erstellen können:
-- Originaltable
CREATE TABLE customer_data (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
credit_card VARCHAR(16),
date_of_birth DATE
);
-- Beispieldaten einfügen
INSERT INTO customer_data (name, email, credit_card, date_of_birth)
VALUES ('John Doe', 'john@example.com', '1234567890123456', '1980-05-15');
-- Maskierte Tabelle erstellen
CREATE TABLE masked_customer_data AS
SELECT
id,
'Customer_' || id AS masked_name,
'user_' || id || '@masked.com' AS masked_email,
SUBSTRING(credit_card, 1, 4) || 'XXXXXXXXXXXX' AS masked_credit_card,
date_of_birth + (RANDOM() * 365 * INTERVAL '1 day') AS masked_date_of_birth
FROM customer_data;
-- Maskierte Daten anzeigen
SELECT * FROM masked_customer_data;
Dieses Beispiel erstellt eine neue Tabelle namens `masked_customer_data` mit maskierten Versionen sensibler Felder. Wir ändern den `name` zu “Customer_” gefolgt von der ID.
Das System verbirgt die `email` in einem maskierten Format. Die `credit_card` zeigt nur die ersten vier Ziffern, der Rest wird durch ‘X’ ersetzt.
Ein zufälliger Anzahl von Tagen verschiebt das `date_of_birth` um bis zu ein Jahr. Dies bewahrt die allgemeine Altersverteilung, während genaue Geburtsdaten versteckt bleiben.
Implementierung über DataSunrise
Greenplum hilft Benutzern, statische Daten zu maskieren; dies kann jedoch bei großen Datenbanken kompliziert und langsam sein. In solchen Fällen empfehlen wir die Verwendung von Drittanbieter-Lösungen. Um dies in DataSunrise zu starten, müssen Sie eine Instanz einer Greenplum-Datenbank erstellen.
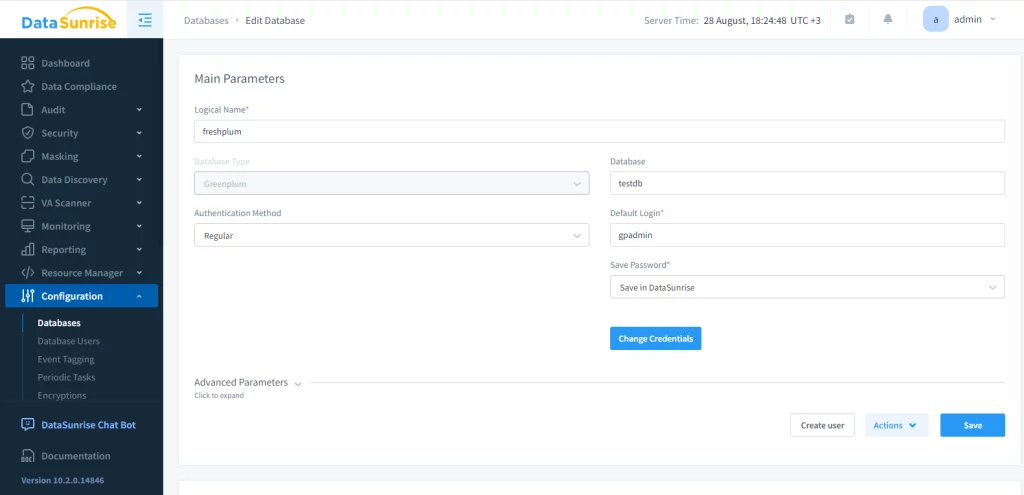
Die Instanz ermöglicht die Interaktion mit der Quell-Datenbank über Audit-, Maskierungs-, Sicherheitsregeln und Aufgaben. Anschließend müssen wir eine statische Maskierungsaufgabe konfigurieren. Dieser Schritt umfasst drei Aktionen: Wählen Sie den Startserver, wählen Sie die Quell- und Ziel-Datenbanken (beide müssen Greenplum sein), und legen Sie Maskierungsregeln fest. Aus Gründen der Integrität empfehlen wir, das Zielschema zu truncaten.
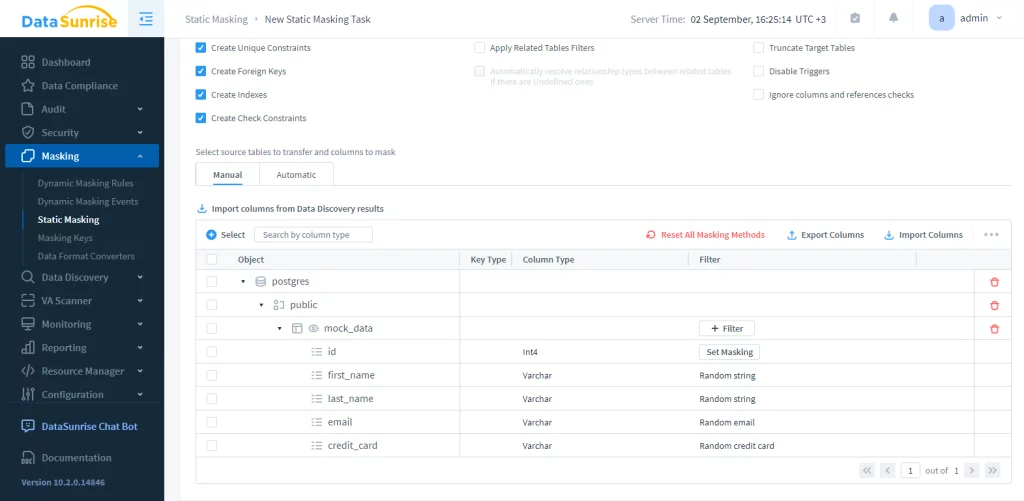
In diesem Beispiel ist die maskierte Tabelle mock_data in der Postgres-Datenbank. Sie müssen nur die Aufgabe starten. Das Ergebnis ist wie folgt:

Fazit
Die statische Datenmaskierung in Greenplum ist eine leistungsstarke Technik zur Verbesserung der Datensicherheit und Compliance. Organisationen können sensible Informationen schützen, indem sie effektive Methoden anwenden, die gleichzeitig die Verwendbarkeit der Daten für Tests, Entwicklung und Analyse beibehalten.
Da Datenschutzbedenken zunehmen und Vorschriften strenger werden, wird die statische Datenmaskierung für Unternehmen, die Greenplum verwenden, um ihre Daten sicher zu halten, immer wichtiger. Organisationen können die Erkenntnisse aus diesem Artikel nutzen, um effektive Strategien zur statischen Datenmaskierung zu entwickeln. Dies hilft, sensible Informationen zu schützen und gleichzeitig die effektive Nutzung ihrer wertvollen Daten zu ermöglichen.
