
Statisches Datenmasking in PostgreSQL
Datenschutz ist entscheidend für Unternehmen, die sensible Informationen verarbeiten. PostgreSQL, ein leistungsstarkes Open-Source-Datenbanksystem, bietet verschiedene Sicherheitsfunktionen. Eine davon ist das statische Datenmasking. Dieser Artikel untersucht das statische Datenmasking in PostgreSQL, seine Vorteile und wie man es effektiv implementiert.
Was ist statisches Datenmasking?
Statisches Datenmasking ist eine Technik, die sensible Daten durch realistische, aber gefälschte Informationen ersetzt. Dieser Prozess findet statt, bevor Daten in Nicht-Produktionsumgebungen verschoben werden. Es hilft, vertrauliche Informationen zu schützen, während Entwicklern und Testern ermöglicht wird, mit genauen Datenrepräsentationen zu arbeiten.
Das statische Datenmasking in PostgreSQL umfasst mehrere Schritte. Zunächst identifizieren Sie sensible Daten.
Dann wählen Sie geeignete Maskierungstechniken aus. Anschließend erstellen Sie maskierte Kopien der Originaldaten. Schließlich ersetzen Sie in Nicht-Produktionsumgebungen die Originaldaten durch die maskierten Daten.
Häufige statische Datenmaskierungstechniken
PostgreSQL bietet verschiedene Maskierungstechniken. Substitution ersetzt sensible Daten durch gefälschte, aber realistische Werte. Zum Beispiel das Ersetzen echter Namen durch zufällig generierte.
Das Mischen von Daten ordnet Daten innerhalb einer Spalte neu an. Es bewahrt die Datenverteilung, aber bricht die Verbindung zwischen den Datensätzen. Numerische Veränderung modifiziert numerische Werte unter Beibehaltung ihrer statistischen Eigenschaften. Datumsverschiebung verschiebt Daten vorwärts oder rückwärts um einen festen Zeitraum.
Implementierung des statischen Datenmaskings in PostgreSQL
Um statisches Datenmasking in PostgreSQL zu implementieren, beginnen Sie mit der Identifizierung sensibler Daten. Überprüfen Sie Ihr Datenbankschema und identifizieren Sie Spalten, die sensible Informationen enthalten.
Erstellen Sie als Nächstes Maskierungsregeln. Entwickeln Sie Regeln für jeden sensiblen Datentyp. Stellen Sie sicher, dass die maskierten Daten für Tests und Entwicklungen nützlich bleiben.
Schreiben Sie Maskierungsabfragen, um Ihre Regeln anzuwenden. Hier ist ein Beispiel, das eine neue Tabelle mit maskierten Daten erstellt:
-- Erstellen Sie eine neue Tabelle für maskierte Daten
CREATE TABLE masked_customers AS
SELECT
id,
MD5(RANDOM()::TEXT) AS masked_name,
CONCAT(
SUBSTRING(MD5(RANDOM()::TEXT) FOR 8),
'@example.com'
) AS masked_email,
CASE
WHEN age < 18 THEN 'minor'
WHEN age BETWEEN 18 AND 65 THEN 'adult'
ELSE 'senior'
END AS masked_age_group,
ROUND(credit_score / 100) * 100 AS masked_credit_score
FROM customers;
-- Fügen Sie alle notwendigen Indizes hinzu
CREATE INDEX ON masked_customers (id);
Dieses Beispiel erstellt eine neue Tabelle namens `masked_customers` basierend auf der Originaltabelle `customers`. Es wendet verschiedene Maskierungstechniken an:
- Namen werden durch zufällige MD5-Hashes ersetzt.
- Das System maskiert E-Mails mit zufälligen Zeichenfolgen und einer generischen Domain.
- Menschen kategorisieren Altersgruppen.
- Kreditbewertungen werden auf die nächste hundert gerundet.
Testen Sie Ihre Maskierungsabfragen an einem kleinen Datensatz, um sicherzustellen, dass sie korrekt funktionieren. Erstellen Sie dann eine maskierte Kopie Ihrer Produktionsdatenbank und wenden Sie die Maskierungsabfragen auf diese Kopie an. Überprüfen Sie, ob die maskierten Daten sensible Informationen ordnungsgemäß verbergen. Verwenden Sie schließlich diese maskierte Tabelle für Nicht-Produktionsumgebungen.
Implementierung über DataSunrise
Es ist möglich, statisches Masking nur mit nativen Tools durchzuführen. Bei einer großen Datenbank kann es jedoch herausfordernd sein. Um den Prozess zu vereinfachen, empfehlen wir die Verwendung von Drittanbietern wie DataSunrise. Die Implementierungsreihenfolge ist wie folgt:
Zuerst muss eine Instanz der PostgreSQL-Datenbank erstellt werden.
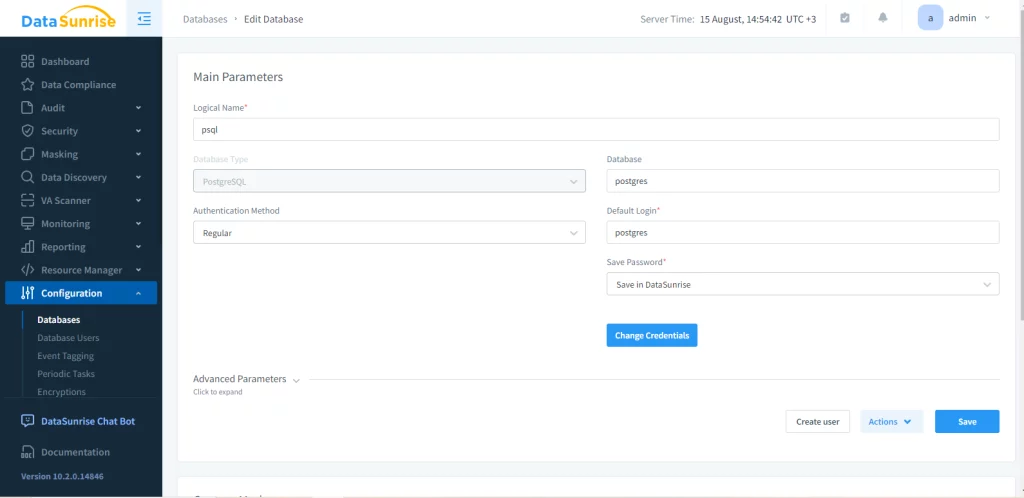
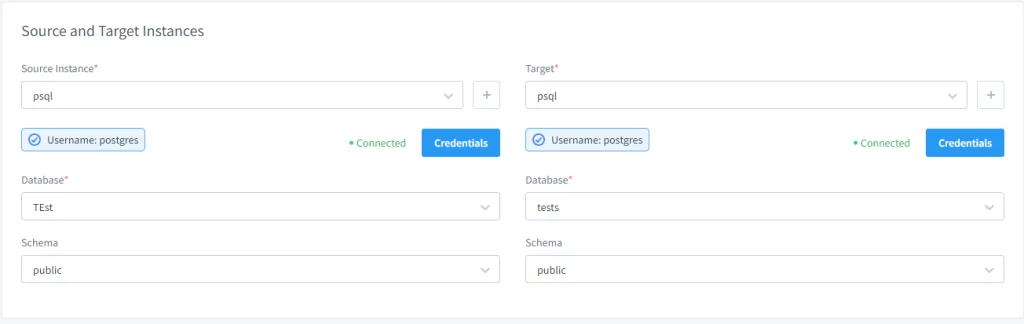
Konfigurieren Sie dann die statische Maskierungsaufgabe. Wählen Sie dazu die Quell- und Ziel-Datenbanken und -Schemas aus. Aus Integritätsgründen empfehlen wir, das Zielschema vor dem Übertragen der Daten zu löschen, obwohl dies optional ist.
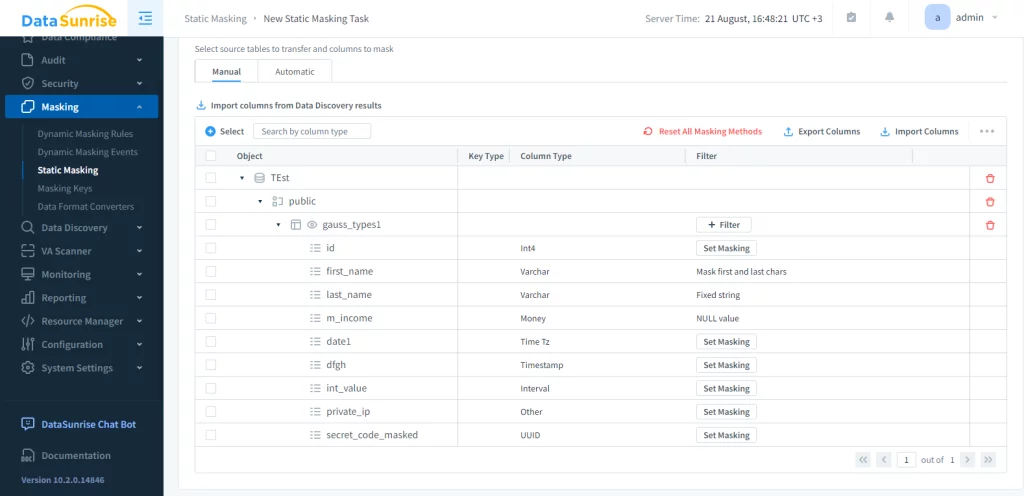
Der nächste Teil der Konfiguration der Aufgabe besteht in der Auswahl der Maskierungsmethoden.
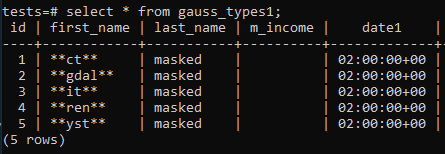
Starten Sie einfach die Aufgabe. Sie können diesen Vorgang jederzeit manuell oder nach einem Zeitplan starten. Das Ergebnis ist wie folgt:
Best Practices und Herausforderungen
Befolgen Sie bewährte Praktiken, um die Effektivität Ihres statischen Datenmaskings zu maximieren. Stellen Sie Konsistenz über Tabellen hinweg sicher und bewahren Sie die referenzielle Integrität. Aktualisieren Sie Ihre maskierten Daten regelmäßig und dokumentieren Sie Ihre Maskierungsregeln. Verwenden Sie starke Zugangskontrollen, um den Zugriff auf sowohl ursprüngliche als auch maskierte Daten zu beschränken.
Statisches Datenmasking bringt Herausforderungen mit sich. Das Maskieren großer Datensätze kann zeitaufwendig und ressourcenintensiv sein. Es kann schwierig sein, Daten zu schützen und gleichzeitig nützliche Daten für Tests zu erhalten. Das Maskieren von Daten in Datenbanken mit komplexen Beziehungen erfordert sorgfältige Planung.
Fazit
Mehrere Tools können beim statischen Datenmasking in PostgreSQL helfen. pgMemento ist eine Open-Source-PostgreSQL-Erweiterung für Auditing und Datenmaskierung. Dataedo ist ein Datenbank-Dokumentations- und Datenmaskierungstool, das PostgreSQL unterstützt. PostgreSQL Anonymizer ist eine Erweiterung, die dynamische Datenmaskierungsfunktionen bietet.
Statisches Datenmasking in PostgreSQL ist eine leistungsstarke Technik zum Schutz sensibler Informationen. Indem Organisationen sie richtig anwenden, können sie den Datenschutz gewährleisten, Vorschriften einhalten und die Genauigkeit der Daten für Nicht-Produktionszwecke bewahren. Da der Datenschutz immer wichtiger wird, ist die Beherrschung des statischen Datenmaskings in PostgreSQL eine wertvolle Fähigkeit für Datenbankadministratoren und Entwickler gleichermaßen.
