
Schutz sensibler Informationen mittels statischer Datenmaskierung in SQL Server

SQL Server-Datenbanken enthalten wertvolle Informationen für Unternehmen. Diese Daten umfassen jedoch häufig sensible Details, die geschützt werden müssen. Statische Datenmaskierung in SQL Server bietet eine robuste Lösung, um vertrauliche Informationen zu schützen und gleichzeitig die Datenbankfunktionalität zu erhalten. Dieser Artikel untersucht die statische Datenmaskierung, ihre Bedeutung für SQL Server und wie man sie effektiv implementiert.
Was ist statische Datenmaskierung?
Statische Datenmaskierung ist eine Technik, die sensible Informationen dauerhaft durch fiktive, aber realistische Daten ersetzt. Es wird eine bereinigte Kopie der Datenbank erstellt, die ihre Struktur und Nützlichkeit beibehält, während vertrauliche Details geschützt werden. In SQL Server stellt die statische Datenmaskierung sicher, dass unbefugte Benutzer keine Zugriff auf oder Ansicht sensibler Informationen haben, selbst wenn sie Zugriff auf die maskierte Datenbankkopie erhalten.
SQL Server-Datenbanken speichern oft personenbezogene Informationen, Finanzaufzeichnungen und andere sensible Daten. Ohne ordnungsgemäßen Schutz werden diese Informationen anfällig für Verstöße und unbefugten Zugriff. Statische Datenmaskierung in SQL Server adressiert diese Sicherheitsbedenken, indem sie sensible Details in der kopierten Datenbank dauerhaft verschleiert.
Viele Branchen unterliegen strengen Vorschriften zum Datenschutz. SQL Server-Statische Datenmaskierung hilft Organisationen, Gesetze wie DSGVO, HIPAA und PCI DSS zu erfüllen. Durch die Implementierung von Maskierungstechniken demonstrieren Unternehmen ihr Engagement für den Datenschutz und vermeiden potenzielle rechtliche Probleme.
Softwareentwicklung und -tests erfordern realistische Daten. Die Verwendung von Produktionsdaten in diesen Umgebungen birgt jedoch erhebliche Risiken. Statische Datenmaskierung für SQL Server ermöglicht es Teams, mit sicheren, maskierten Versionen von Datenbanken zu arbeiten. Dieser Ansatz bewahrt die Datenintegrität, während die Gefahr der Offenlegung sensibler Informationen während der Entwicklungs- und Testprozesse eliminiert wird.
Implementierung der statischen Datenmaskierung in SQL Server
SQL Server bietet verschiedene Maskierungstechniken, um unterschiedlichen Datentypen und Sicherheitsanforderungen gerecht zu werden. Einige beliebte Methoden umfassen Substitution (Ersetzen sensibler Werte durch realistische Alternativen), Umordnen (Neuanordnung vorhandener Daten innerhalb einer Spalte), Verschlüsselung (Umwandlung sensibler Daten in ein unleserliches Format) und Nullsetzen (Ersetzen sensibler Werte durch NULL).
Sobald Sie sensible Daten identifiziert und geeignete Techniken ausgewählt haben, ist es Zeit, Maskierungsregeln zu erstellen. In SQL Server können Sie eingebaute Funktionen oder benutzerdefinierte Skripte verwenden, um diese Regeln anzuwenden. Zum Beispiel, um eine Spalte für Sozialversicherungsnummern zu maskieren:
UPDATE Employees
SET SSN = CONCAT(
REPLICATE('X', 3),
'-',
REPLICATE('X', 2),
'-',
RIGHT(SSN, 4)
)
Diese Regel würde Sozialversicherungsnummern von “123-45-6789” in “XXX-XX-6789” ändern und nur die letzten vier Ziffern anzeigen.
Nach der Definition der Maskierungsregeln erstellen Sie eine Kopie der Quelldatenbank und wenden die Regeln auf diese neue Kopie an. Dieser Schritt stellt sicher, dass die Originaldaten intakt bleiben, während eine vollständig maskierte Version für den Einsatz in nicht-produktiven Umgebungen erstellt wird.
Die Nutzung solcher Methoden kann für unerfahrene Benutzer mühsam sein und bei großen Datenbanken extrem zeitaufwändig sein. DataSunrise vereinfacht den Prozess der statischen Maskierung erheblich. Zunächst muss ein Benutzer eine Instanz der MSSQL-Datenbank erstellen, um Regeln und Aufgaben dafür zu erstellen.
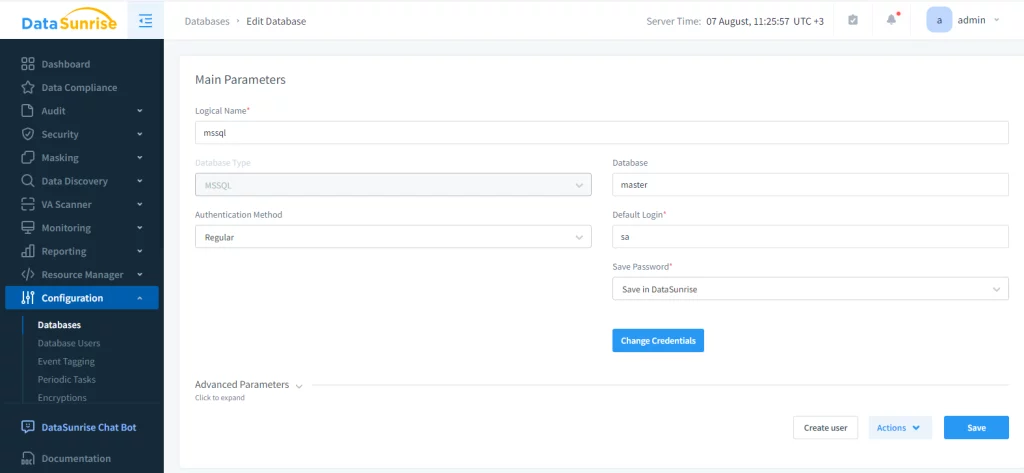
Als nächstes muss eine statische Maskierungsaufgabe erstellt werden. Zuerst wird die Quelldatenbank und das zu maskierende Schema ausgewählt, dann die Zieldatenbank spezifiziert. Das Ziel muss natürlich auch MSSQL sein. Vor der Maskierung werden alle Daten im Zielschema gelöscht, daher muss ein Benutzer vorsichtig vorgehen.
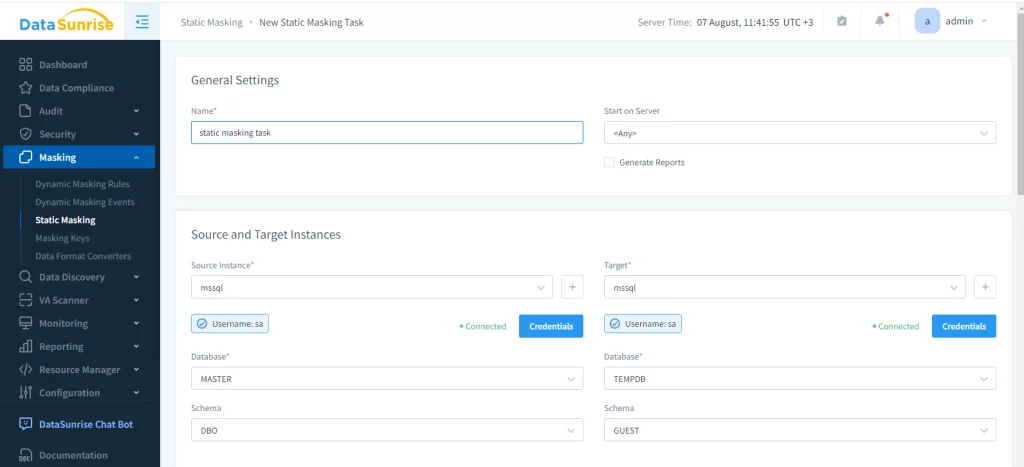
Schließlich müssen die Maskierungsregeln festgelegt werden. Genau wie bei der dynamischen Maskierung wählt ein Benutzer die zu maskierenden Tabellen und den Maskierungsalgorithmus aus.
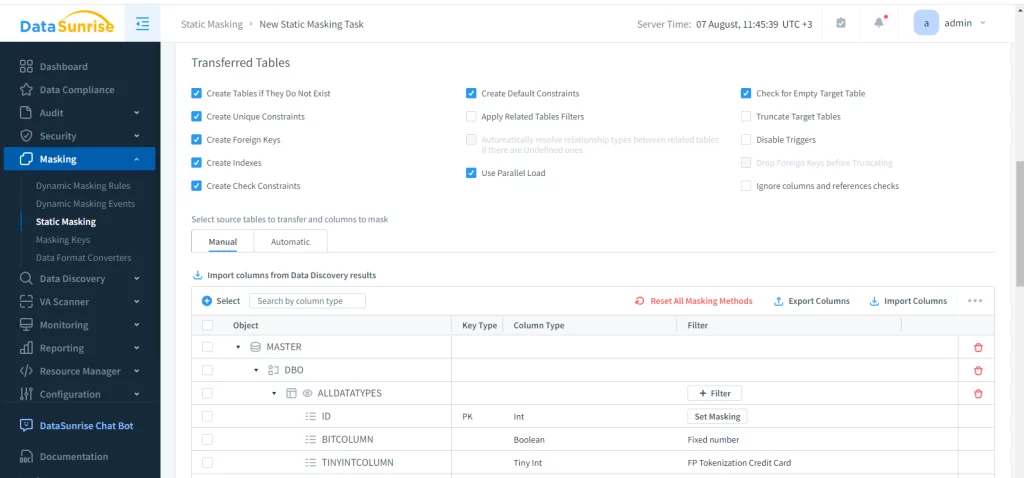
Es bleibt nur noch die Konfiguration der Maskierungsregeln und das Ausführen der Aufgabe. Damit wird eine voll funktionsfähige Dummy-Speicherung mit intakten Beziehungen erstellt, aber die erforderlichen Daten sind versteckt.
Best Practices und Herausforderungen
Beim Implementieren der statischen Datenmaskierung ist es wichtig, Best Practices zu befolgen. Stellen Sie sicher, dass verwandte Daten in verschiedenen Tabellen konsistent maskiert werden, um die referentielle Integrität zu gewährleisten. Versuchen Sie, das ursprüngliche Datenformat beizubehalten, damit Anwendungen korrekt weiterarbeiten können. Wählen Sie Maskierungswerte, die echten Daten ähneln, für genauere Tests und Analysen.
Dokumentieren Sie Ihre SQL Server statische Datenmaskierungsverfahren klar. Diese Praxis gewährleistet Konsistenz und hilft bei Prüfungs- und Compliance-Bemühungen. Überprüfen und aktualisieren Sie Ihre Maskierungsregeln regelmäßig, insbesondere wenn sich die Datenbankstrukturen ändern oder neue Arten von sensiblen Daten eingeführt werden.
Statische Datenmaskierung bringt jedoch auch Herausforderungen mit sich. Komplexe Datenbeziehungen können es schwierig machen, eine konsistente Maskierung über verwandte Tabellen hinweg sicherzustellen. Es ist entscheidend, das richtige Gleichgewicht zwischen Datenschutz und Benutzerfreundlichkeit zu finden, da eine zu aggressive Maskierung die Daten für bestimmte Zwecke unbrauchbar machen könnte. Bei sehr großen Datenbanken kann der Prozess der Erstellung einer maskierten Kopie erhebliche Speicher- und Verarbeitungsressourcen erfordern.
Werkzeuge und Lösungen
Während benutzerdefinierte Skripte die statische Datenmaskierung bewältigen können, erleichtern verschiedene Tools den Prozess erheblich. SQL Server Data Tools (SSDT) umfasst Maskierungsfunktionen, die sich in SQL Server-Projekte integrieren lassen. Verschiedene Drittanbieter-Lösungen bieten erweiterte Funktionen für statische Datenmaskierung in SQL Server. Für Organisationen mit spezifischen Anforderungen können benutzerdefinierte PowerShell-Skripte den Prozess der statischen Datenmaskierung automatisieren.
Da sich die Bedürfnisse im Bereich Datenschutz ständig weiterentwickeln, können wir Fortschritte in den Fähigkeiten der statischen Datenmaskierung erwarten. Mögliche Entwicklungen umfassen KI-gesteuerte Maskierungsalgorithmen, verbesserte Integration mit cloudbasierten SQL Server-Instanzen und verbesserte Leistung für die Maskierung von groß angelegten Datenbanken.
Vergessen Sie nicht, die Website von DataSunrise zu besuchen und eine Demo-Sitzung zu vereinbaren, um alles zu erfahren, was unser Team zu bieten hat.
Fazit
Statische Datenmaskierung in SQL Server bietet ein leistungsstarkes Werkzeug zum Schutz sensibler Informationen und zur Aufrechterhaltung der Datenbankfunktionalität in nicht-produktiven Umgebungen. Durch das Verständnis verschiedener Maskierungstechniken, die Implementierung von Best Practices und die Bewältigung potenzieller Herausforderungen können Organisationen ihre Datensicherheitslage erheblich verbessern. Da Bedrohungen der Datenprivatsphäre weiter zunehmen, bleibt die statische Datenmaskierung in SQL Server ein wesentlicher Bestandteil einer umfassenden Sicherheitsstrategie für das Datenbankmanagement.
