
Die Vorteile der synthetischen Datengenerierung für moderne Workflows erkunden

Eine kürzlich durchgeführte Gartner-Umfrage unter über 2.500 Führungskräften ergab enthüllte, dass 45% ihre KI-Investitionen als Reaktion auf den Hype um ChatGPT erhöht haben. Bei DataSunrise halten wir mit diesem Trend Schritt. Sie haben wahrscheinlich unseren vorherigen Artikel über die KI-basierten Tools zur Generierung synthetischer (zufälliger oder gefälschter) Daten gelesen. Dieser Artikel befasst sich mehr mit dem Thema der synthetischen Datengenerierung mit DataSunrise und einigen anderen kostenlos verfügbaren Tools.
Ob für Tests, Schulungen oder Entwicklung – reale Daten zu erhalten, stellt eine Herausforderung dar. Datenschutzbedenken, Datenverfügbarkeitsprobleme und regulatorische Einschränkungen behindern oft den Zugang zu echten Daten. Hier kommt die zufällige Datengenerierung ins Spiel. Sie bietet eine Lösung, indem sie künstliche Daten erstellt, die die Eigenschaften realer Daten nachahmen, ohne die Privatsphäre oder Sicherheit zu gefährden.
Was sind synthetische Daten?
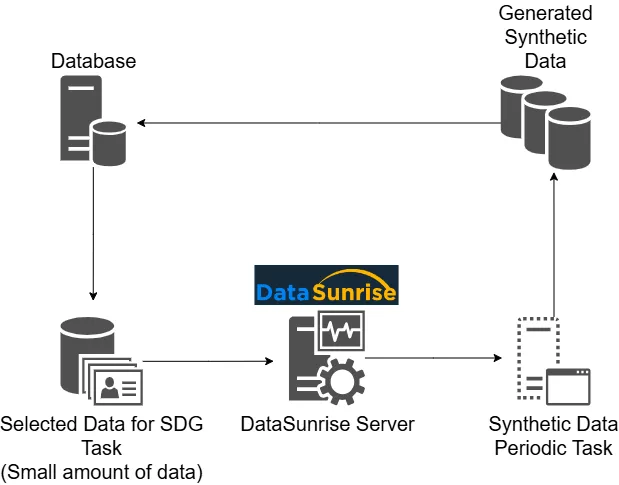
Synthetische Daten sind künstlich generierte Daten, die realen Daten hinsichtlich statistischer Eigenschaften, Muster und Strukturen ähneln. Sie enthalten keine tatsächlichen Informationen über Einzelpersonen oder Entitäten. Stattdessen erstellen Sie diese Daten mithilfe von Algorithmen und mathematischen Modellen, um Authentizität zu wahren und gleichzeitig die Risiken im Zusammenhang mit dem Umgang mit sensiblen Daten zu vermeiden.
Fähigkeiten von DataSunrise in der synthetischen Datengenerierung
DataSunrise bietet eine robuste Funktion zur zufälligen Datengenerierung, die reale Daten genau nachahmt. Diese Funktion wird für verschiedene Geschäftszwecke genutzt, von der Entwicklung und dem Testen bis zur Verbesserung von maschinellen Lernalgorithmen. Lassen Sie uns in die Fähigkeiten von DataSunrise im Bereich der synthetischen Datengenerierung eintauchen.
Daten-, Datenschutz- und Sicherheitstest
Eine der Hauptanwendungen von Daten ist in Datenschutz– und Sicherheitstests. Organisationen, insbesondere in Bereichen wie Finanzen, Gesundheitswesen und Recht, können synthetische Daten verwenden, um ihre Sicherheitssysteme zu bewerten, ohne echte sensible Informationen preiszugeben. Ein Finanzinstitut kann beispielsweise synthetische Transaktionsdaten generieren, um seine Betrugserkennungssysteme zu testen.
Schulung von maschinellen Lernmodellen
Industrien verwenden zunehmend gefälschte Daten zur Schulung von maschinellen Lernmodellen. Dieser Ansatz stellt sicher, dass die Privatsphäre realer Daten nicht gefährdet wird. Ein Gesundheitsunternehmen kann beispielsweise synthetische Patientendaten generieren, um ein prädiktives Modell für die Krankheitsdiagnose zu trainieren, ohne die Vertraulichkeit der Patienten zu verletzen.
Softwareentwicklung und -tests
Synthetische Daten sind in der Softwareentwicklung von unschätzbarem Wert. Sie bieten realistische Datensätze für die Erstellung und Bewertung von Anwendungen, insbesondere in Branchen wie Telekommunikation. Ein Telekommunikationsunternehmen kann beispielsweise synthetische Gesprächsdatensätze generieren, um seine Abrechnungssoftware zu testen.
Gesundheitsanalytik
Im Gesundheitswesen ermöglichen solche Daten Forschern und Datenwissenschaftlern, Studien und Experimente durchzuführen, ohne die Vertraulichkeit der Patienten zu gefährden. Ein Forschungsteam kann beispielsweise synthetische Patientendaten generieren, um die Auswirkungen eines neuen Medikaments zu untersuchen.
Wie man synthetische Daten mit DataSunrise generiert
DataSunrise vereinfacht den Prozess der zufälligen Datengenerierung und macht es einfach, Daten in verschiedene Workflows zu integrieren. Hier ist eine Schritt-für-Schritt-Anleitung zur Generierung von Daten mit DataSunrise.
Schritt 1: Allgemeine Einstellungen
Gehen Sie zu Konfiguration – Periodische Aufgaben. Klicken Sie auf +Neue Aufgabe. Im Abschnitt Allgemeine Einstellungen geben Sie den Namen für Ihre Periodische Aufgabe ein. Wählen Sie den Aufgabentyp – Synthetische Datengenerierung – und auf welchem Server gestartet werden soll (optional).
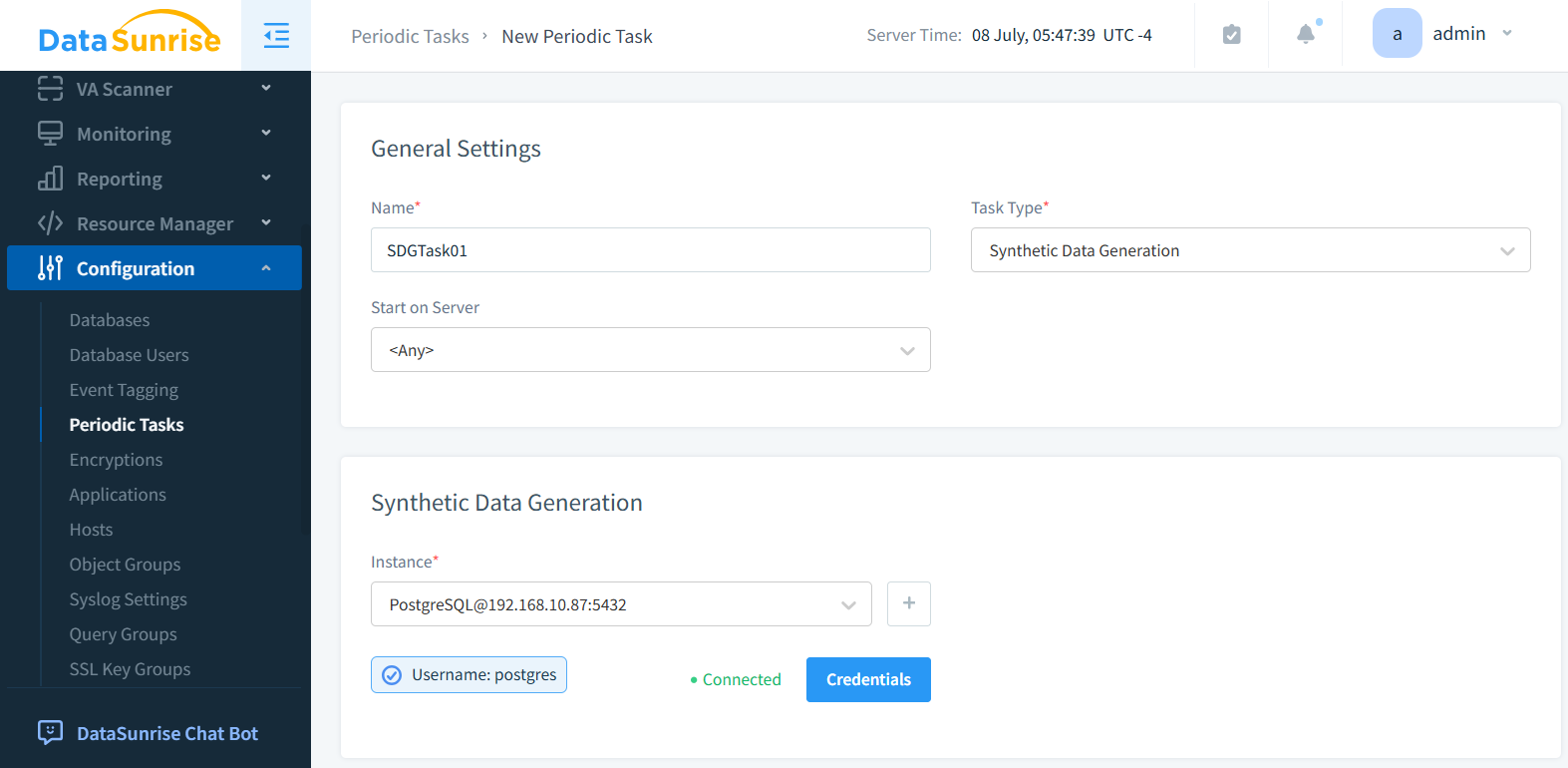
Schritt 2: Wählen Sie die Datenbankinstanz
Im Abschnitt Synthetische Datengenerierung wählen Sie die Datenbankinstanz aus. Die PostgreSQL-Instanz ist auf der nachstehenden Abbildung ausgewählt.
Schritt 3: Generierte Tabellen
Im Abschnitt Generierte Tabellen wählen Sie die erforderlichen Kontrollkästchen (z. B. Leere Zieltabelle und Tabellen generieren bei Fehler überspringen). Klicken Sie auf +Auswählen, um ein Fenster zu öffnen, in dem Sie die benötigten Datenbankobjekte auswählen können. Wählen Sie eine Datenbank, ein Schema, eine Tabelle und eine Spalte aus, für die synthetische Daten generiert werden sollen. Nach Abschluss Ihrer Auswahl klicken Sie auf Speichern.
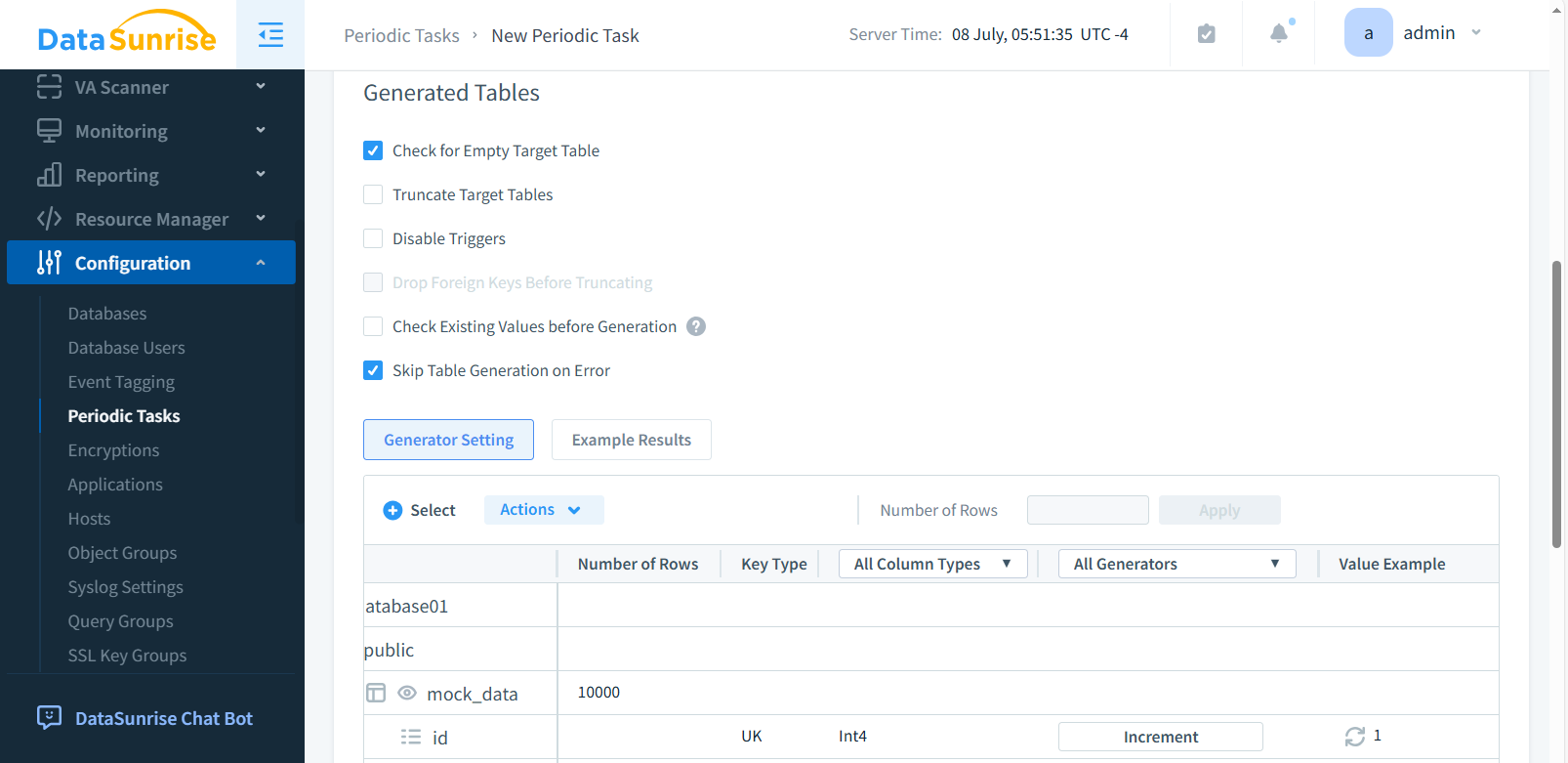
Schritt 4: Auswahl der Datengeneratoren (optional)
In der Spalte Alle Generatoren können Sie den Generator auswählen oder erstellen. Im Abschnitt Beispielergebnisse sehen Sie die Liste der generierten Daten. Nach Abschluss klicken Sie auf Anwenden oder Speichern. Dies ist optional, da das System den ausgewählten Spalten Standardgeneratoren zuweist.
Wenn Sie Ihren eigenen spezifischen Generator erstellen möchten (vor der Erstellung der Aufgabe zur synthetischen Datengenerierung), gehen Sie zu Konfiguration – Generatoren und klicken Sie auf +Generator erstellen. Wählen Sie einen Generatortyp aus und geben Sie seine Parameter an. Klicken Sie auf Speichern, und Sie können Ihrem Generator in der Aufgabe zur synthetischen Datengenerierung anwenden.
„Anzahl der Zeilen“ wird oben in der Tabelle aktiv, wenn die Spalte ausgewählt ist.
Schritt 5: Die Aufgabe speichern und ausführen
Hier können Sie die periodischen Aufgaben mit der Aufgabe zur synthetischen Datengenerierung sowie einige zuvor erstellte periodische Aufgaben mit Benutzerverhalten sehen.
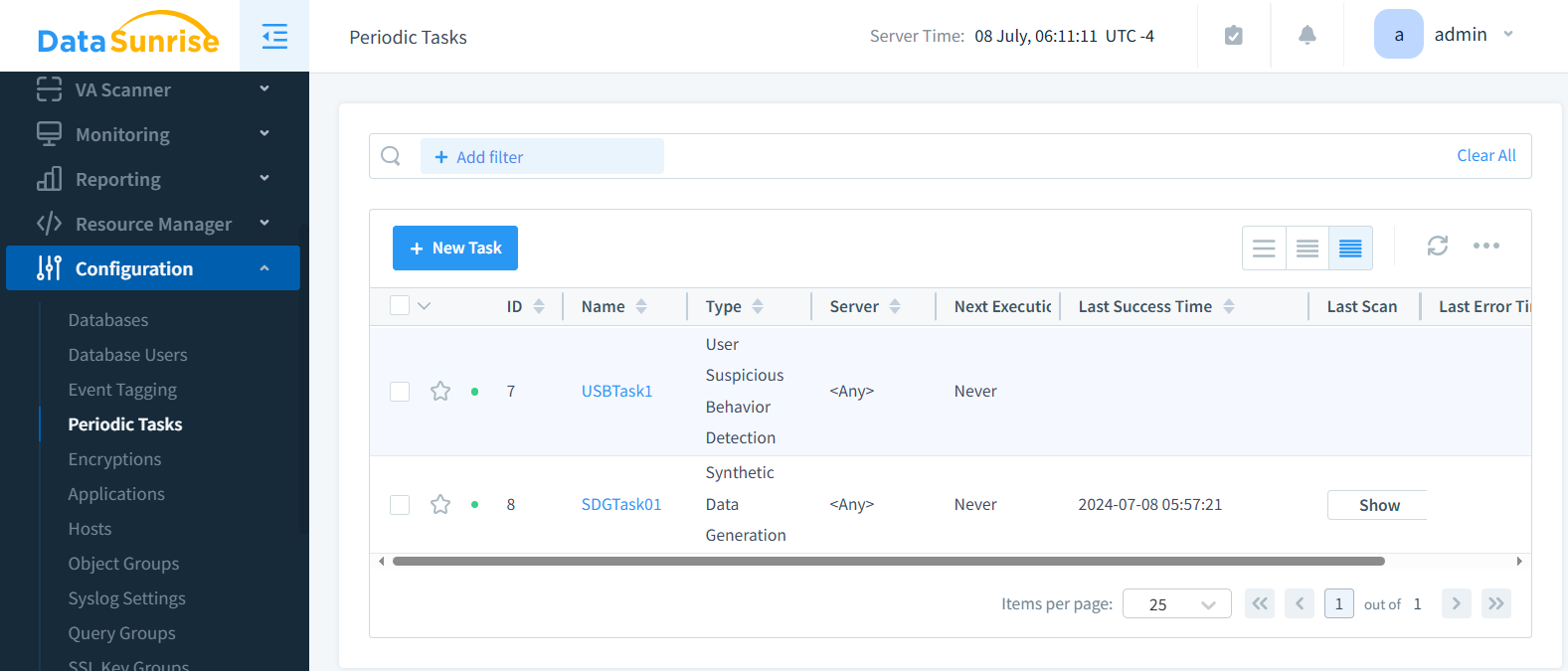
Die Aufgabe ist jetzt bereit. Führen Sie die Aufgabe nach Bedarf aus oder lassen Sie sie periodisch ausführen.
Online-Tools und Open-Source-Lösungen
DataSunrise bietet hochflexible und robuste Kontrolle über die zufällige Datengenerierung sowie erstklassige Datenbanksicherheitslösungen, die die größte Abdeckung von Datenbanken und Cloud-Lagern auf dem Markt bieten. Aber was ist mit kostenlosen Optionen? Es gibt mehrere Online-Tools und Open-Source-Bibliotheken zur Generierung gefälschter Daten ohne Kosten. Lassen Sie uns einige beliebte Optionen erkunden:
SDV (Synthetic Data Vault)
Wir haben dieses Thema kurz in unserem vorherigen Artikel über die Generierung von KI-Daten diskutiert. Dort erwähnten wir, dass CTGAN eine Komponente von SDV (Synthetic Data Vault) ist. Zur Erinnerung: SDV ist eine Open-Source-Python-Bibliothek zur Generierung von mehrtabelligen relationalen Daten. Es verwendet maschinelles Lernen, um künstliche Daten zu erstellen, die die statistischen Eigenschaften des ursprünglichen Datensatzes beibehalten. Um SDV mit pip zu installieren, verwenden Sie den folgenden Befehl:
pip install sdv
Beispielanwendung:
from sdv.datasets.demo import download_demo
from sdv.single_table import GaussianCopulaSynthesizer
# Laden Sie den Demodatensatz herunter
real_data, metadata = download_demo(
modality='single_table',
dataset_name='fake_hotel_guests'
)
# Erstellen und anpassen des Synthesizers
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(real_data)
# Generierung gefälschter Daten
synthetic_data = synthesizer.sample(num_rows=500)
# Anzeige der ersten paar Zeilen der generierten Daten
print(synthetic_data.head())Dieses Skript verwendet den GaussianCopula-Synthesizer von SDV zur Generierung synthetischer Daten basierend auf den statistischen Eigenschaften eines realen Datensatzes.
Das Ergebnis kann folgendermaßen aussehen:
CTGAN (Conditional Tabular GAN)
CTGAN ist ein GAN-basiertes Modell zur speziellen Generierung synthetischer Tabellendaten. Es ist besonders nützlich für komplexe Datensätze mit gemischten Datentypen.
Sehen Sie sich bitte unseren vorherigen Artikel über KI-bezogene Tools zur Generierung synthetischer Daten für ein CTGAN-Codebeispiel an.
Mockaroo
Mockaroo ist ein in Ruby geschriebenes, webbasiertes Tool, das es Ihnen ermöglicht, realistische zufällige Daten in verschiedenen Formaten (CSV, JSON, SQL, usw.) ohne Programmierung zu generieren. Es bietet eine benutzerfreundliche Oberfläche und unterstützt benutzerdefinierte Datenschemata. Der kostenlose Zugang ist auf 1000 Datenzeilen begrenzt.
Best Practices für die Generierung gefälschter Daten
Um hochwertige Mock-Daten sicherzustellen:
- Verstehen Sie Ihre Datenanforderungen und den Anwendungsfall
- Wählen Sie die geeignete Generierungsmethode basierend auf Ihren Bedürfnissen
- Validieren Sie die generierten Daten gegenüber Ihrem Originaldatensatz oder Anforderungen
- Stellen Sie die Datenprivatsphäre sicher, indem Sie die Einbeziehung sensibler Informationen vermeiden
- Verfeinern Sie Ihren Generierungsprozess kontinuierlich basierend auf Feedback und Ergebnissen
Fazit
Synthetische Datengenerierung bietet eine wertvolle Lösung für Organisationen, die mit realistischen Daten arbeiten möchten, während sie gleichzeitig Datenschutz- und Sicherheitsbedenken berücksichtigen. DataSunrise vereinfacht diesen Prozess und macht es einfach, künstliche Daten in verschiedene Workflows zu integrieren. Es ist jedoch unerlässlich, die Wirksamkeit und Zuverlässigkeit von synthetischen Daten zu validieren. Organisationen sollten sicherstellen, dass die generierten Daten die reale Datenverteilung genau darstellen und die erforderlichen Beziehungen und Abhängigkeiten beibehalten.
Zusammenfassend bietet die Datengenerierung zahlreiche Vorteile, von der Verbesserung des Datenschutzes und der Sicherheit über die Verbesserung von maschinellen Lernmodellen bis hin zur Softwareprüfung. Mit der DataSunrise-Funktion zur synthetischen Datengenerierung können Organisationen sicher durch die Datenlandschaft navigieren und die Kraft der generierten Daten für ihre geschäftlichen Bedürfnisse nutzen.
Für weitere Informationen besuchen Sie unsere Website oder fordern Sie eine Online-Demo an.
Nächste
