
Was ist dynamische Daten?

In der heutigen schnelllebigen digitalen Welt, die täglich 5 Exabytes an Daten produziert, sind Daten der Lebensnerv von Unternehmen und Organisationen. Aber nicht alle Daten sind gleich geschaffen.
Dynamische Daten sind unerlässlich für Echtzeit-Entscheidungen in Branchen wie Finanzen und IoT, aber das Management dieser Daten bringt Herausforderungen wie die Gewährleistung von Genauigkeit und Sicherheit mit sich. In diesem Artikel werden wir untersuchen, wie man diese sich ständig ändernden Daten effektiv handhabt.Einige Daten bleiben konstant, während andere Daten sich schnell ändern. Diese sich ständig ändernden Informationen nennen wir dynamische Daten. In diesem Artikel werden wir tief in die Welt der sich ständig ändernden Daten eintauchen, ihre Natur, Typen und die Herausforderungen, die sie im Datenmanagement darstellen.
Die Natur der dynamischen Daten
Diese Art von Daten ist eine Information, die sich häufig ändert, oft in Echtzeit. Im Gegensatz zu statischen Daten, die über die Zeit konstant bleiben, sind sie flüssig und reaktionsfähig auf äußere Faktoren. Diese Eigenschaft macht sie sowohl wertvoll als auch herausfordernd zu verwalten.
Warum diese Daten wichtig sind
In einer Ära, in der Informationen Macht sind, bieten just-in-time empfangene Daten Erkenntnisse auf dem neuesten Stand der Technik. Sie ermöglichen es Unternehmen, zu profitieren, aber sie stellen auch Herausforderungen dar. Einige davon können Sie im Bild unten sehen.
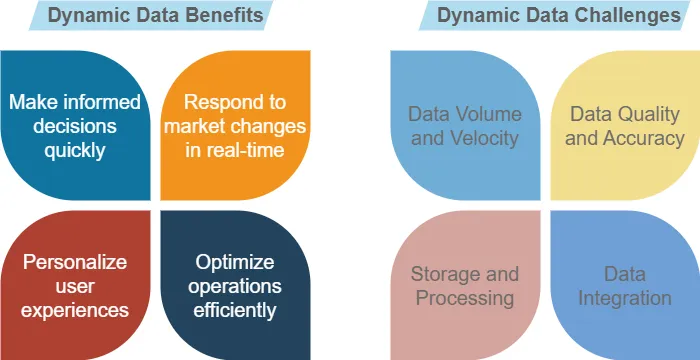
Zum Beispiel verlässt sich eine Wetter-App auf dynamische Daten, um genaue Vorhersagen zu liefern. Da sich die Bedingungen ändern, ändern sich auch die Daten, um sicherzustellen, dass die Benutzer immer die aktuellsten Informationen haben.
Arten von dynamischen Daten
Sie kommen in verschiedenen Formen, jede mit ihren eigenen Merkmalen und Anwendungen. Lassen Sie uns einige gängige Typen erkunden:
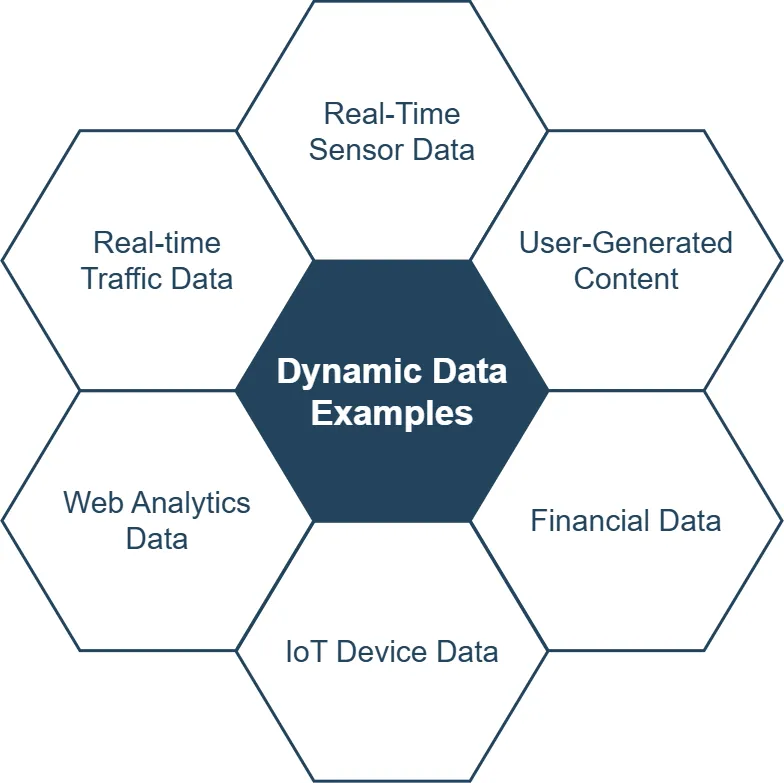
1. Echtzeit-Sensordaten
Sensordaten werden kontinuierlich aus der physischen Welt gesammelt. Dazu gehören:
- Temperaturmessungen
- Feuchtigkeitsniveaus
- Bewegungserkennung
- GPS-Koordinaten
Zum Beispiel verwenden Smart-Home-Geräte Sensordaten, um Heiz- und Kühlsysteme automatisch anzupassen.
2. Von Benutzern erstellte Inhalte
Sozialen Medien Plattformen sind ein gutes Beispiel für dynamische Daten in Aktion. Benutzer erstellen ständig neue Beiträge, Kommentare und Reaktionen, was einen stetigen Strom dynamischer Inhalte erzeugt.
3. Finanzdaten
Aktienkurse, Wechselkurse und Kryptowährungswerte schwanken ständig. Finanzinstitute verlassen sich auf diese dynamischen Daten für Handels- und Investitionsentscheidungen.
4. IoT-Gerätedaten
Das Internet der Dinge (IoT) generiert kontinuierlich riesige Mengen an Daten. Verbundene Geräte übertragen kontinuierlich Informationen über ihren Status, ihre Nutzung und ihre Umgebung.
5. Web-Analysedaten
Websites und Apps sammeln Echtzeitdaten über Benutzerverhalten, einschließlich:
- Seitenaufrufe
- Klickraten
- Sitzungsdauer
- Konversionsraten
Diese Art von Daten hilft Unternehmen, ihre Online-Präsenz und Marketingstrategien zu optimieren.
Herausforderungen beim Management instabiler Daten
Obwohl diese Art von Daten zahlreiche Vorteile bietet, stellt sie auch einzigartige Herausforderungen für Datenmanagementprozesse dar.
1. Datenvolumen und -geschwindigkeit
Die schiere Menge der erzeugten Daten kann überwältigend sein. Die Datensammlung ist in diesem Fall ebenfalls komplex. Organisationen müssen robuste Systeme haben, um Datenströme mit hoher Geschwindigkeit zu bewältigen.
2. Datenqualität und -genauigkeit
Bei schnell wechselnden Daten wird die Gewährleistung der Genauigkeit schwieriger. Veraltete oder falsche Informationen können zu schlechten Entscheidungen führen. Versuchen Sie immer, die Datenqualität zu verbessern, bevor Sie Erkenntnisse sammeln.
3. Speicherung und Verarbeitung
In diesem Fall erfordern Daten flexible Speicherlösungen und effiziente Verarbeitungskapazitäten, um Echtzeitaktualisierungen und -abfragen zu bewältigen.
4. Datenintegration
Das Kombinieren dynamischer Daten aus mehreren Quellen kann komplex sein. Die Gewährleistung der Konsistenz und Kohärenz über verschiedene Datenströme hinweg ist entscheidend.
5. Sicherheit und Datenschutz
Der Schutz dynamischer Daten stellt einzigartige Sicherheitsherausforderungen dar. Da sich Daten schnell ändern, wird es komplizierter, geeignete Zugriffskontrollen und Verschlüsselungen aufrechtzuerhalten.
Optimale Datenverarbeitung für sich ändernde Daten
Um die Kraft sich ständig ändernder Daten zu nutzen, müssen Organisationen optimale Datenverarbeitungsstrategien implementieren.
Traditionelle Batch-Verarbeitungsmethoden reichen oft nicht aus, wenn es darum geht, eine sich ändernde Datenstruktur zu bewältigen. Echtzeitverarbeitungstechniken wie Stream-Processing ermöglichen eine sofortige Datenanalyse und -aktion.
Beispiel:
from pyspark.streaming import StreamingContext
# Erstellen Sie einen StreamingContext mit einem 1-Sekunden-Batch-Intervall
ssc = StreamingContext(sc, 1)
# Erstellen Sie einen DStream, der eine Verbindung zu einer Datenquelle herstellt
lines = ssc.socketTextStream("localhost", 9999)
# Verarbeiten Sie den Stream
word_counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
# Drucken Sie die Ergebnisse
word_counts.pprint()
# Starten Sie die Berechnung
ssc.start()
ssc.awaitTermination()Dieser PySpark-Code demonstriert die Echtzeitverarbeitung eines Text-Streams, wobei eingehende Wörter gezählt werden.
Code-Erklärung
Der bereitgestellte PySpark-Streaming-Code führt Folgendes aus:
- Zuerst importiert er den StreamingContext aus dem Streaming-Modul von PySpark.
- Er erstellt einen StreamingContext (ssc) mit einem 1-Sekunden-Batch-Intervall. Das bedeutet, dass die Streaming-Berechnung in 1-Sekunden-Batches unterteilt wird.
- Er richtet einen DStream (Discretized Stream) ein, der eine Verbindung zu einer Datenquelle herstellt. In diesem Fall wird ein Socket auf localhost an Port 9999 gelesen. Dies könnte jede beliebige Streaming-Datenquelle sein.
- Der Code verarbeitet dann den Stream:
- Er zerlegt jede Zeile in Wörter
- Mappt jedes Wort auf ein Schlüssel-Wert-Paar (Wort, 1)
- Reduziert nach Schlüssel, was effektiv die Vorkommen jedes Wortes zählt
- Er druckt die Ergebnisse der Wortzählung.
- Schließlich startet er die Berechnung und wartet auf deren Beendigung.
Dieser Code richtet im Wesentlichen ein Echtzeit-Wortzählungssystem ein. Es würde kontinuierlich Textdaten vom angegebenen Socket lesen, Wörter in Echtzeit zählen (jede Sekunde aktualisieren) und die Ergebnisse ausdrucken.
Es ist ein einfaches, aber leistungsstarkes Beispiel dafür, wie PySpark Streaming für die Echtzeit-Datenverarbeitung verwendet werden kann. In einem realen Szenario könnten Sie die Socket-Quelle durch einen robusteren Datenstrom (wie Kafka) ersetzen und komplexere Verarbeitungen durchführen oder die Ergebnisse in einer Datenbank anstatt nur im Druck speichern.
Skalierbare Infrastruktur
Um das Volumen und die Geschwindigkeit dynamischer Daten zu bewältigen, ist eine skalierbare Infrastruktur wesentlich. Cloud-basierte Lösungen und verteilte Systeme bieten die Flexibilität, die benötigt wird, um sich an wechselnde Datenlasten anzupassen.
Datenqualitätsüberwachung
Die Implementierung automatisierter Datenqualitätsprüfungen hilft, die Genauigkeit und Zuverlässigkeit dynamischer Daten zu gewährleisten. Dies beinhaltet:
- Validierung von Datentypen
- Prüfung auf Ausreißer
- Sicherstellung der Datenvollständigkeit
Sicherheit dynamischer Daten: Schutz flüssiger Informationen
Die Sicherung dieser Daten erfordert einen proaktiven und adaptiven Ansatz. Hier sind einige Schlüsselstrategien:
1. Verschlüsselung während des Transports und im Ruhezustand
Stellen Sie sicher, dass dynamische Daten verschlüsselt werden, sowohl wenn sie zwischen Systemen bewegt werden als auch wenn sie gespeichert werden.
2. Echtzeit-Zugriffskontrolle
Implementieren Sie dynamische Zugriffskontrollmechanismen, die sich an wechselnde Daten- und Benutzerkontexte anpassen können.
3. Kontinuierliche Überwachung
Verwenden Sie Echtzeit-Überwachungstools, um Sicherheitsbedrohungen zu erkennen und darauf zu reagieren, sobald sie auftreten.
4. Datenanonymisierung
Wenn Sie mit sensiblen dynamischen Daten arbeiten, sollten Sie Anonymisierungstechniken in Betracht ziehen, um die individuelle Privatsphäre zu schützen, während die Nützlichkeit der Daten erhalten bleibt.
Beispiel:
import pandas as pd
from faker import Faker
# Laden Sie dynamische Daten
df = pd.read_csv('user_data.csv')
# Initialisieren Sie Faker
fake = Faker()
# Anonymisieren Sie sensible Spalten
df['name'] = df['name'].apply(lambda x: fake.name())
df['email'] = df['email'].apply(lambda x: fake.email())
# Speichern Sie anonymisierte Daten
df.to_csv('anonymized_user_data.csv', index=False)Dieses Python-Skript demonstriert einen einfachen Prozess zur Datenanonymisierung für dynamische Benutzerdaten.
Die Zukunft der Datenwissenschaft
Mit der fortschreitenden Entwicklung der Technologie wird die Bedeutung und Häufigkeit dynamischer Daten nur noch zunehmen. Zu den aufkommenden Trends gehören:
- Edge-Computing: Verarbeitung dieser Daten näher an der Quelle für schnellere Erkenntnisse
- AI-gestützte Analysen: Einsatz von maschinellem Lernen, um tiefere Einblicke aus dynamischen Datenströmen zu gewinnen
- Blockchain zur Datensicherheit: Sicherstellung der Authentizität und Rückverfolgbarkeit dynamischer Daten
Fazit: Die Dynamik der Datenrevolution annehmen
Dynamische Daten verändern die Art und Weise, wie wir die Welt um uns herum verstehen und mit ihr interagieren. Von Echtzeiteinblicken in Geschäftsdaten bis hin zu personalisierten Benutzererfahrungen ist ihr Einfluss weitreichend. Obwohl das Management dynamischer Daten Herausforderungen mit sich bringt, überwiegen die Vorteile die Schwierigkeiten.
Durch die Implementierung robuster Datenmanagementprozesse, optimaler Verarbeitungsstrategien und starker Sicherheitsmaßnahmen können Organisationen das volle Potenzial dynamischer Daten nutzen. Die effektive Nutzung dynamischer Daten wird in unserer datengesteuerten Welt einen großen Vorteil bieten.
Für Unternehmen, die ihre Daten effektiv sichern und verwalten möchten, bietet DataSunrise benutzerfreundliche und flexible Tools für Datenbanksicherheit und Compliance vor Ort und in der Cloud. Besuchen Sie unsere Website bei DataSunrise für eine Online-Demonstration und erfahren Sie, wie wir Ihnen helfen können, Ihre wertvollen Datenressourcen zu schützen.
