
Was ist eine CSV-Datei?
Einführung: Die bescheidene CSV-Datei
Wussten Sie, dass CSV-Dateien seit den frühen Tagen der Computertechnik existieren? In den 1970er und frühen 1980er Jahren führte IBMs Fortran 77-Sprache den Zeichendatentyp ein, der die Unterstützung von komma-getrennten Eingaben und Ausgaben ermöglichte. Diese einfachen, aber leistungsstarken Dateien haben den Test der Zeit bestanden und sind nach wie vor eine beliebte Wahl für den Datenaustausch, selbst in unserer modernen, technologiegetriebenen Welt. Tauchen wir ein in die Welt der komma-getrennten Dateien und erkunden wir, warum sie weiterhin ein bevorzugtes Format für viele Datenprofis und gelegentliche Benutzer gleichermaßen sind.
Wir haben zuvor die Fähigkeiten von DataSunrise zur Handhabung semistrukturierter Daten in JSON-Dateien beschrieben. Schauen Sie sich diese Informationen an, um mehr über die Datensicherheitsfunktionen von DataSunrise zu erfahren.
Mit DataSunrise können Sie die sensiblen Daten in CSV-Dateien maskieren und entdecken, die lokal oder in S3-Speichern gespeichert sind. Hier ist ein Maskierungsbeispiel.
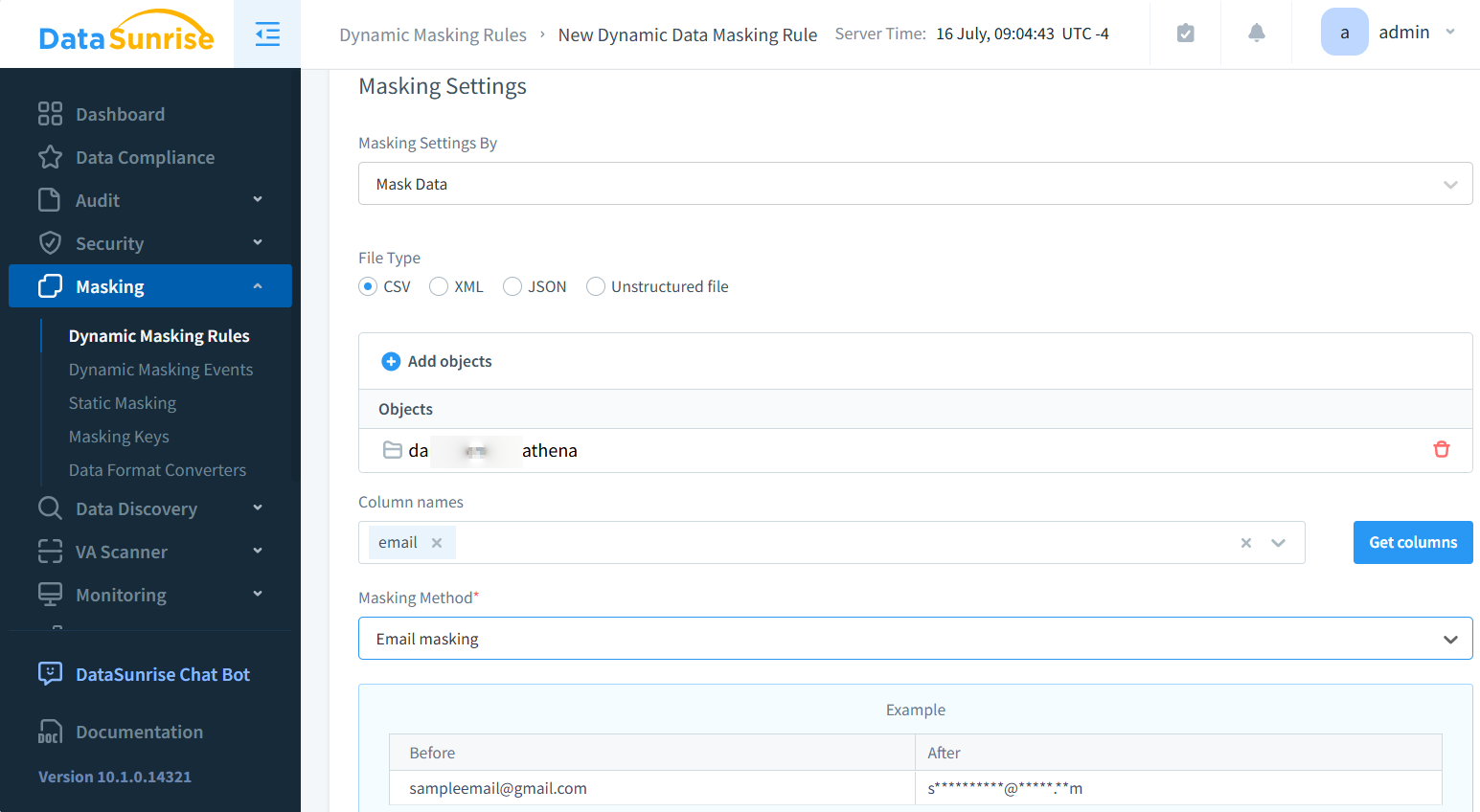
Nach einer einfachen Einrichtung können Sie die maskierten CSV-Dateien über den S3-Proxy von DataSunrise mit spezieller Software wie S3Browser abrufen (herunterladen). Eine ordnungsgemäße Konfiguration der Proxy-Einstellungen ist in der Client-Software erforderlich. Das Ergebnis ist wie folgt:

Im breitgefächerten Ökosystem der Dateiformate sticht die CSV-Datei aufgrund ihrer Klarheit und Vielseitigkeit weiterhin hervor. Eine CSV-Datei (Comma-Separated Values) ist ein einfaches Textdokument, das zur Speicherung tabellarischer Daten entwickelt wurde. Jede Zeile stellt eine Zeile der Tabelle dar, wobei die Werte durch Kommata getrennt sind. Diese einfache Struktur macht das CSV-Dateiformat extrem leicht lesbar, generierbar und verarbeitbar über Betriebssysteme und Anwendungen hinweg.
Was ist eine CSV-Datei?
Eine CSV-Datei (Comma-Separated Values-Datei) ist ein einfaches Textdokument, das tabellarische Daten in einem strukturierten Format speichert. Jede Zeile in der Datei repräsentiert eine Datenzeile, und die Werte innerhalb jeder Zeile sind durch Kommata getrennt. Dieses einfache Format macht CSV-Dateien ideal für den Austausch von Daten zwischen verschiedenen Anwendungen und Plattformen.
Die Dateierweiterung für dieses Format ist typischerweise “.csv” – beispielsweise “data.csv” oder “report.csv”. Wenn sie in einem Texteditor geöffnet werden, erscheinen die Inhalte als Textzeilen, wobei die Werte durch Kommata getrennt sind. Beim Import in Tabellenkalkulationssoftware wie Microsoft Excel oder Google Sheets wird die Tabelle automatisch in Zeilen und Spalten organisiert.
CSV-Dateien können verschiedene Datentypen enthalten, einschließlich Text, Zahlen und Datumsangaben. Während Kommata die traditionellen Trennzeichen sind (daher der Name), können in einigen Implementierungen auch andere Zeichen wie Semikolons, Tabs oder Pipes als Trennzeichen verwendet werden. Die erste Zeile enthält oft Spaltenüberschriften, die die Daten in jeder Spalte beschreiben, dies ist jedoch nicht durch das Format vorgeschrieben.
Im Gegensatz zu fortgeschrittenen Tabellenkalkulationsformaten unterstützt eine CSV-Datei keine eingebetteten Objekte, mehrere Registerkarten oder Formatierungsfunktionen. Ihre minimalistische Struktur ist sowohl eine Einschränkung als auch ein Vorteil—ideal für leichten CSV-Datenaustausch, aber nicht gedacht für komplexe visuelle Berichte oder analytische Modelle.
Warum CSV-Dateien nutzen?
CSV-Dateien bieten mehrere Vorteile, die zu ihrer weiten Verbreitung beitragen:
- Einfachheit: Das Format ist leicht zu verstehen und zu bearbeiten, selbst für nicht-technische Benutzer. Sie können es in einem Texteditor wie Notepad oder Notepad++ öffnen.
- Kompatibilität: Dateien können von einer Vielzahl von Software geöffnet und bearbeitet werden, von Tabellenkalkulationsprogrammen bis hin zu Texteditoren.
- Datenaustausch: Sie dienen als universelles Format zum Übertragen von Daten zwischen verschiedenen Systemen und Anwendungen.
- Größeneffizienz: Dateien sind typischerweise kleiner als ihre binären Gegenstücke, was sie ideal für die Speicherung und Übertragung großer Datensätze macht.
Hier ist eine Vergleichstabelle von Datenformaten, die in Big Data und Machine Learning verwendet werden, und die Rolle von komma-getrennten Dateien bei der Datenverarbeitung hervorhebt.
| Format | Big Data | Machine Learning | Vorteile | Nachteile |
|---|---|---|---|---|
| CSV | Häufig für Datenaustausch, weniger häufig für Speicherung | Oft verwendet für kleine bis mittlere Datensätze | Einfach, menschenlesbar, weit unterstützt | Nicht effizient für große Datensätze, keine Schema-Durchsetzung |
| Parquet | Sehr häufig für Speicherung und Verarbeitung | Gut für große Datensätze und Merkmalsspeicher | Spaltenorientierte Speicherung, effiziente Komprimierung | Nicht menschenlesbar, erfordert spezielle Werkzeuge zur Ansicht |
| Avro | Häufig für Datenserialisierung | Weniger häufig, aber in einigen Pipelines genutzt | Schema-Evolution, kompaktes binäres Format | Komplexer als CSV, nicht so effizient wie Parquet für Analysen |
| JSON | Häufig für APIs und Dokumentenspeicher | Verwendet zur Speicherung von Metadaten und kleinen Datensätzen | Flexibel, menschenlesbar, weit unterstützt | Weniger effiziente Speicherung als binäre Formate |
| TFRecord | Nicht häufig genutzt | Speziell für TensorFlow, häufig in ML-Pipelines | Effizient für große Datensätze, gut mit TensorFlow | Außerhalb des TensorFlow-Ökosystems nicht weit unterstützt |
CSV-Beispiel
Sehen wir uns ein einfaches CSV-Beispiel an, um seine Struktur zu verdeutlichen:
Name, Alter, Stadt John Doe, 30, New York Jane Smith, 25, London Bob Johnson, 35, Paris
Dieses Beispiel zeigt, wie Daten in einer CSV-Datei organisiert sind, wobei jede Zeile einen Datensatz darstellt und die Werte durch Kommata getrennt sind.
Arbeiten mit CSV-Dateien in Python
Python bietet eingebaute Module und Bibliotheken zur Verarbeitung von CSV-Dateien, was es zu einer der beliebtesten Sprachen für die Arbeit mit tabellarischen Daten im CSV-Format macht.
Pythons csv-Modul bietet einfache Methoden zum Lesen und Schreiben von CSV-Dateien. Hier ist ein einfaches Beispiel:
import csv
# Datei lesen
with open('data.csv', 'r') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
# In eine Datei schreiben
with open('output.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['Name', 'Alter', 'Stadt'])
csv_writer.writerow(['Alice', '28', 'Berlin'])Dieser Code demonstriert, wie man mit Python’s eingebautem csv-Modul CSV-Dateien lesen und schreiben kann.
Verwendung von Pandas
Für fortgeschrittenere Datenmanipulation ist die Pandas-Bibliothek eine ausgezeichnete Wahl. Sie bietet leistungsstarke Werkzeuge zum Arbeiten mit semistrukturierten Daten, einschließlich CSV-Dateien:
import pandas as pd
# Datei lesen
df = pd.read_csv('data.csv')
# Anzeige der ersten paar Zeilen
print(df.head())
# In eine Datei schreiben
df.to_csv('output.csv', index=False)Pandas erleichtert es, komplexe Operationen mit CSV-Daten durchzuführen, wie Filtern, Sortieren und Aggregieren. Sie können die Daten problemlos später wieder im CSV-Format speichern.
Die Vor- und Nachteile von Kommagetrennten Dateien
Während CSV-Dateien weit verbreitet sind, ist es wichtig, ihre Stärken und Einschränkungen zu verstehen:
Vorteile
- Menschenlesbar: Kommagetrennte Dateien können leicht in Texteditoren angesehen und bearbeitet werden.
- Leichtgewichtig: Sie haben eine kleine Dateigröße im Vergleich zu vielen anderen Formaten.
- Weit unterstützt: Die meisten Datenverarbeitungstools und Programmiersprachen können mit CSV-Dateien arbeiten.
Nachteile
- Eingeschränkte Datentypen: Textdateien unterstützen von Haus aus keine komplexen Datentypen oder -strukturen.
- Keine Standardisierung: Es gibt keinen offiziellen Standard für CSV-Dateien, was zu möglichen Kompatibilitätsproblemen führen kann. Es gibt keine erforderlichen Spalten oder obligatorischen Trennzeichen.
- Datenintegrität: Kommagetrennte Dateien verfügen nicht über eingebaute Fehlerüberprüfungs- oder Datenvalidierungsmechanismen. Big Data-Formate (wie Parquet) enthalten eingebaute Prüfsummen für Datenblöcke.
Binäre Formate: Wann und warum sie besser sind
Obwohl CSV-Dateien in vielen Szenarien brillieren, können binäre Formate in bestimmten Situationen von Vorteil sein:
- Leistung: Binäre Formate sind oft schneller zu lesen und zu schreiben, insbesondere bei großen Datensätzen.
- Datentypen: Sie können komplexe Datentypen und -strukturen genauer bewahren.
- Komprimierung: Binärformate bieten in der Regel bessere Komprimierungsraten und sparen so Speicherplatz.
- Sicherheit: Einige binäre Formate bieten Optionen für Verschlüsselung und Zugriffskontrolle.
Beispiele für binäre Formate sind HDF5, Parquet und Avro. Diese Formate sind besonders in Big Data-Umgebungen nützlich, in denen Leistung und Datenintegrität entscheidend sind.
CSV-Dateien im Datenaustausch
CSV-Dateien spielen eine wichtige Rolle im Datenaustausch in verschiedenen Branchen und Anwendungen:
- Business Intelligence: Unternehmen verwenden häufig Textdateien, um Daten zwischen verschiedenen BI-Tools und Datenbanken zu übertragen.
- Wissenschaftliche Forschung: Forscher teilen häufig Datensätze in diesem Format für eine einfache Analyse und Zusammenarbeit.
- Webanwendungen: Viele Webdienste ermöglichen es Benutzern, Daten im kommagetrennten Format für Offline-Analysen oder Sicherungszwecke zu exportieren.
- IoT und Sensordaten: Kommagetrennte Textdateien werden häufig verwendet, um Daten von IoT-Geräten und Sensoren zu protokollieren und zu übertragen.
Die Einfachheit und universelle Natur von Textdateien machen sie zu einer idealen Wahl für diese Datenaustausch-Szenarien.
CSV-Dateien in Unternehmensumgebungen
CSV-Dateien bleiben entscheidend in Unternehmensdatenabläufen. Viele Altsysteme verlassen sich auf CSV für Datenimporte. Finanzinstitutionen verwenden CSV für tägliche Transaktionsberichte. Gesundheitssysteme tauschen Patientendaten durch sichere CSV-Übertragungen aus. Datenmigrationsprojekte beginnen oft mit CSV-Exporten. ETL-Pipelines konsumieren häufig CSV als Quelldaten. Cloud-Speicheranbieter optimieren für CSV-Speicherung und -Abruf. Für die Einhaltung gesetzlicher Vorschriften sind oft CSV-Archive kritischer Daten erforderlich. Prüfer fordern häufig Daten im CSV-Format zur Überprüfung an. CSV-Dateien dienen als universelle Übersetzer zwischen inkompatiblen Systemen. Ihre Einfachheit macht sie ideal für geplante automatisierte Datenaustausche.
CSV-Dateien im Big Data-Bereich
Kommagetrennte Werte-Dateien haben eine etwas komplexe Beziehung zu Big Data. Lassen Sie mich dies für Sie aufschlüsseln:
- Beliebtheit in bestimmten Kontexten:
- Das kommagetrennte Dateiformat wird immer noch häufig für den Datenaustausch und als Zwischenformat in Big Data-Ökosystemen verwendet.
- Es wird häufig zum Importieren von Daten in Big Data-Systeme oder zum Exportieren von Ergebnissen für weitere Analysen verwendet.
- Beschränkungen für Big Data:
- CSV-Dateien komprimieren sich nicht gut, was bei sehr großen Datensätzen ein Problem sein kann.
- Sie verfügen nicht über integrierte Schemadefinitionen, was zu Dateninkonsistenzen bei groß angelegten Operationen führen kann.
- Das Parsen großer Textdateien kann im Vergleich zu einigen binären Formaten langsamer sein.
- Bevorzugte Alternativen:
- Für Big Data-Operationen werden Formate wie Parquet, Avro oder ORC oft bevorzugt.
- Diese Formate bieten bessere Komprimierung, Schema-Evolution und schnellere Verarbeitungsgeschwindigkeiten.
- Anwendungsfälle, in denen kommagetrennte Dateien weiterhin relevant sind:
- Datenaufnahme: Viele Systeme akzeptieren nach wie vor kommagetrennte Werte als Eingabeformat.
- Altsysteme: Einige ältere Systeme verlassen sich möglicherweise noch auf solche Dateien für den Datenaustausch.
- Einfache Datensätze: Für kleinere oder weniger komplexe Datensätze in einem Big Data-Ökosystem könnte CSV weiterhin verwendet werden.
- Hybride Ansätze:
- Einige Big Data-Arbeitsabläufe könnten CSV für die anfängliche Datenaufnahme oder die endgültige Ausgabe verwenden, während optimiertere Formate für Zwischenschritte der Verarbeitung genutzt werden.
Wann eine CSV-Datei vs. ein binäres Format verwenden
| Anwendungsfall | Bestes Format | Warum |
|---|---|---|
| Datenaustausch zwischen Systemen | CSV | Einfach, universell unterstützt, menschenlesbar |
| Großflächige Analysen oder maschinelles Lernen | Parquet / Avro | Komprimierung, Schema-Unterstützung, effizientes Parsen |
| Kleine Berichte oder Protokolle | CSV | Leicht zu exportieren, zu importieren und ohne spezielle Werkzeuge zu lesen |
Fazit: Der anhaltende Wert von CSV-Dateien
CSV-Dateien bleiben ein wertvolles Werkzeug im Werkzeugkasten des Datenprofis. Ihre Einfachheit, Vielseitigkeit und weitreichende Unterstützung machen sie zu einer ausgezeichneten Wahl für viele Datenaustausch- und Speicher-Szenarien. Während binäre Formate in bestimmten Situationen Vorteile bieten, bleibt die bescheidene Textdatei eine bewährte Lösung für den schnellen und einfachen Datenaustausch plattformübergreifend und in Anwendungen.
Wie wir gesehen haben, ist die Arbeit mit kommagetrennten Dateien in Python einfach, egal ob Sie das Kern-Python nutzen oder fortgeschrittenere Bibliotheken wie Pandas. Diese Zugänglichkeit trägt zur anhaltenden Beliebtheit von CSV-Dateien in Datenanalyse- und Verarbeitungsaufgaben bei.
Für diejenigen, die mit sensiblen Daten in CSV-Dateien oder anderen semistrukturierten Formaten arbeiten, bietet DataSunrise benutzerfreundliche und flexible Tools für die Datenbanksicherheit. Unsere Lösungen umfassen NLP-basierte Datenerkennung, die besonders nützlich sein kann, wenn man mit kommagetrennten Dateien arbeitet, die potenziell sensible Informationen enthalten. Um mehr darüber zu erfahren, wie DataSunrise Ihre Datensicherheitsmaßnahmen verbessern kann, besuchen Sie unsere Website für eine Online-Demo und erkunden Sie unsere umfassenden Datenbanksicherheitslösungen.
