
Was ist NoSQL? Verständnis von nicht-relationalen Datenbanken und ihren Vorteilen

Im Kontext der Datenverwaltung haben sich NoSQL-Datenbanken als eine leistungsstarke Alternative zu traditionellen relationalen Datenbanken herausgestellt. Organisationen stehen vor Herausforderungen bei der Verwaltung großer Mengen an unstrukturierten Daten. NoSQL-Datenbanken bieten eine skalierbare, flexible und leistungsstarke Lösung für die Verarbeitung dieser Daten. Dieser Leitfaden erklärt NoSQL-Datenbanken, ihre Hauptmerkmale und gibt Beispiele, um zu zeigen, wie sie funktionieren.
Verständnis von NoSQL-Datenbanken
NoSQL, kurz für “Not Only SQL”, umfasst verschiedene Datenbanktechnologien, die sich von traditionellen relationalen Datenbanken mit Tabellen unterscheiden. NoSQL-Datenbanken können viele verschiedene Datentypen verarbeiten und leicht skalieren. Sie brechen die starren Schemaeinschränkungen relationaler Datenbanken auf, was agileren und anpassungsfähigeren Datenmodellen zugutekommt.
Wichtige Merkmale von NoSQL-Datenbanken
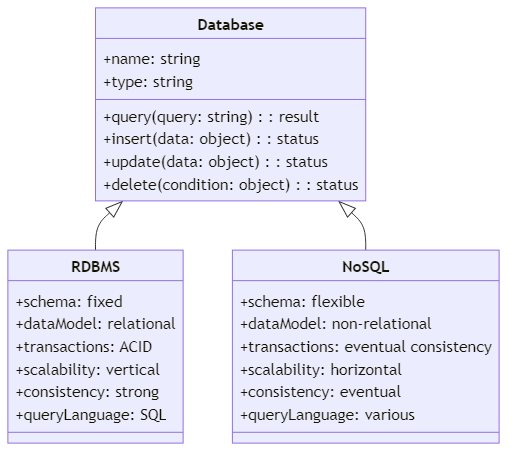
Wichtige Unterschiede zwischen SQL und NoSQL
Schema-Flexibilität
Eines der bestimmenden Merkmale von NoSQL-Datenbanken ist ihre Schema-Flexibilität. Im Gegensatz zu relationalen Datenbanken, die ein vordefiniertes Schema erzwingen, erlauben NoSQL-Datenbanken eine dynamischere und flexiblere Datenstruktur. Dadurch können Sie Informationen ohne eine feste Struktur speichern, was es einfach macht, sich an sich ändernde Datenanforderungen anzupassen.
Betrachten Sie zum Beispiel eine Social-Media-Anwendung, die Benutzerprofile speichert. In einer Datenbank gibt es ein spezifisches Layout mit Spalten für Name, Alter, Standort und Interessen. Eine NoSQL-Datenbank speichert jedes Benutzerprofil als eigenes Dokument mit unterschiedlichen Attributen und Strukturen.
Ein Profil kann beispielsweise soziale Medienlinks oder Blog-URLs haben, während ein anderes Profil bestimmte Felder überhaupt nicht enthält. Diese Flexibilität ermöglicht es, vielfältigen und sich ändernden Datenanforderungen gerecht zu werden, ohne komplexe Schema-Migrationen durchführen zu müssen.
Horizontale Skalierbarkeit
NoSQL-Datenbanken ermöglichen horizontale Skalierung, wodurch sie Daten nahtlos über mehrere Server verteilen können. Die Fähigkeit zur Skalierung nach außen ermöglicht es NoSQL-Datenbanken, massive Datenmengen und hohe Traffic-Lasten mühelos zu bewältigen. Wenn Ihre Daten wachsen, können Sie einfach mehr Server zu Ihrem NoSQL-Datenbank-Cluster hinzufügen, um die erhöhte Nachfrage zu bewältigen.
Um dies zu veranschaulichen, betrachten wir eine E-Commerce-Plattform, die während der Spitzen-Shopping-Saisons einen Anstieg des Verkehrsaufkommens erlebt. In einer relationalen Datenbank bedeutet die Verarbeitung größerer Datenmengen normalerweise ein Upgrade auf einen stärkeren Server.
Mit einer NoSQL-Datenbank können Sie jedoch die Daten problemlos auf mehrere Server verteilen und so eine horizontale Skalierung ermöglichen. Jeder Server kann einige Daten und Traffic verwalten. Wenn der Bedarf steigt, können Sie weitere Server hinzufügen, um die Leistung und Verfügbarkeit im Cluster hoch zu halten.
Hohe Leistung
NoSQL-Datenbanken sind für schnelle Lese- und Schreibvorgänge bestens geeignet, was sie ideal für Webanwendungen, Content-Delivery-Netzwerke und Echtzeit-Datenverarbeitung macht. Sie erreichen dies durch verschiedene Techniken wie Sharding von Daten, In-Memory-Caching und Eventual Consistency Modelle.
Betrachten Sie zum Beispiel ein Echtzeit-Analytik-Dashboard, das aktuelle Daten für eine große Informationsmenge anzeigt. Apache Cassandra verteilt Daten über Knoten hinweg, um schnelles Abfragen und parallele Verarbeitung in einem Cluster zu ermöglichen. Cassandra kann viele Schreibvorgänge und schnelle Datenaktualisierungen handhaben. Dies ist dank seines spaltenbasierten Datenmodells und des Eventual Consistency Modells möglich.
Arten von NoSQL-Datenbanken
NoSQL-Datenbanken gibt es in verschiedenen Varianten, die jeweils auf spezifische Anwendungsfälle und Datenmodelle zugeschnitten sind. Lassen Sie uns die vier Haupttypen von NoSQL-Datenbanken genauer betrachten:
Dokument-Datenbanken
Dokument-Datenbanken wie MongoDB und Couchbase speichern Daten in einem dokumentorientierten Format, typischerweise JSON oder BSON. Jedes Dokument ist eigenständig und kann eine eigene Struktur haben, was flexible und hierarchische Datenspeicherung ermöglicht.
Beispiel-MongoDB-Abfrage:
db.users.find({ age: { $gt: 25 }, interests: "travel" })
Diese Suche durchsucht alle Dokumente in der Sammlung “users”, in denen die Person älter als 25 Jahre ist und gerne reist. Die Flexibilität des Dokumentmodells erlaubt komplexe Abfragen und einfache Wiederauffindbarkeit von verschachtelten Daten.
Key-Value-Stores
Key-Value-Stores wie Redis und Amazon DynamoDB sind die einfachste Art von NoSQL-Datenbanken. Sie speichern Daten als eine Sammlung von Schlüssel-Wert-Paaren, wobei jeder Schlüssel einzigartig ist und auf einen spezifischen Wert verweist. Key-Value-Stores eignen sich hervorragend für schnelles und effizientes Speichern von Daten. Sie sind ideal für Aufgaben wie Caching, Session-Management und Echtzeit-Datenverarbeitung.
Beispiel-Redis-Abfrage:
HSET user:1 name "John Doe" age 30
Diese Abfrage setzt die Felder “name” und “age” für den Hash, der unter dem Schlüssel “user:1” gespeichert ist. Die einfache Key-Value-Struktur von Redis ermöglicht eine effiziente Speicherung und Wiederauffindung von Daten.
Spaltenorientierte Datenbanken
Spaltenorientierte Datenbanken, auch bekannt als Wide-Column-Stores, organisieren Daten in Spalten statt in Reihen. Sie ermöglichen schnelle Abfragen und Aggregationen großer Datenmengen, was sie perfekt für Data Warehousing und Analytics macht. Apache Cassandra und Apache HBase sind beliebte Beispiele für spaltenorientierte Datenbanken.
Beispiel-Cassandra-Abfrage:
SELECT name, age FROM users WHERE city = 'New York';
Diese Abfrage ruft die Spalten “name” und “age” aus der Tabelle “users” ab, wobei die Spalte “city” gleich “New York” ist. Die spaltenorientierte Struktur von Cassandra erlaubt die effiziente Wiederauffindung spezifischer Spalten, was die Festplatten-E/A reduziert und die Abfrageleistung verbessert.
Graphdatenbanken
Graphdatenbanken wie Neo4j und Amazon Neptune konzentrieren sich darauf, Daten basierend auf den Beziehungen zwischen Entitäten zu speichern und abzufragen. Knoten und Kanten in einem Graphen helfen dabei, Daten zu organisieren, was die Abfrage und Navigation durch verknüpfte Informationen erleichtert.
Beispiel-Neo4j-Abfrage:
MATCH (u:User)-[:FRIENDS_WITH]->(f:User)-[:LIKES]->(p:Product) WHERE u.name = 'Alice' RETURN f.name, p.name
Diese Abfrage findet alle Benutzer, die Freunde von “Alice” sind, und gibt die Namen dieser Freunde sowie die von ihnen gemocht Produkte zurück. Graphdatenbanken sind hervorragend für die Verarbeitung komplexer Beziehungen und tiefen Traversierungen verknüpfter Daten geeignet.
Vorteile und Anwendungsfälle von NoSQL
NoSQL-Datenbanken bieten zahlreiche Vorteile und eignen sich für verschiedene Anwendungsfälle:
- Skalierbarkeit und hoher Traffic: NoSQL-Datenbanken können massive Datenmengen und hohe Traffic-Lasten bewältigen, indem sie Daten über mehrere Server verteilen. Sie sind ideal für soziale Netzwerke, Content-Management-Systeme und Echtzeit-Analytikplattformen, die eine einfache Skalierbarkeit benötigen.
- Flexibilität und Agilität: Die schemafreie Natur von NoSQL-Datenbanken ermöglicht flexibles Datenmodellieren und leichte Anpassung an sich weiterentwickelnde Datenanforderungen. Dies macht sie geeignet für agile Entwicklungsumgebungen und Anwendungen mit sich schnell ändernden Datenstrukturen.
- Echtzeit-Verarbeitung: NoSQL-Datenbanken sind exzellent in der Verarbeitung von Echtzeitdaten und bieten schnelle Lese- und Schreibvorgänge. Anwendungen, die sofortige Updates benötigen, wie Börsenticker, Sensormonitoring und Live-Chat-Systeme, verwenden sie häufig.
- Big Data und Analytik: NoSQL-Datenbanken eignen sich hervorragend für die Speicherung und Verarbeitung großer Mengen unstrukturierter und semistrukturierter Daten. Sie sind ideal für Datenanalysen, Log-Analysen und maschinelles Lernen, da sie komplexe Abfragen und Aggregationen verarbeiten können.
Fazit
NoSQL-Datenbanken haben die Art und Weise, wie wir Daten in der modernen Ära speichern, verwalten und verarbeiten, revolutioniert. NoSQL-Datenbanken bieten große Vorteile durch ihre Flexibilität, Skalierbarkeit und hohe Leistung und sind daher unerlässlich für das Datenmanagement.
Entdecken Sie die verschiedenen Arten von NoSQL-Datenbanken und ihre einzigartigen Merkmale. Dies hilft Ihnen, die am besten geeignete für Ihre Anforderungen auszuwählen. NoSQL-Datenbanken können Ihre Bedürfnisse für Echtzeitanwendungen und Beziehungsmanagement erfüllen. Wählen Sie die richtige für Ihr Projekt.
Die Daten wachsen schnell, und der Bedarf an flexiblen Lösungen steigt. NoSQL-Datenbanken werden eine entscheidende Rolle bei der Verwaltung von Daten in der Zukunft spielen. Durch die Nutzung der NoSQL-Technologie können Organisationen das volle Potenzial ihrer Daten ausschöpfen, Innovation fördern und wettbewerbsfähig in ihrer Branche bleiben.
Nächste
