
Reordenamiento de Nombres
Introducción
Las empresas enfrentan el desafío de mantener la privacidad de los datos mientras todavía utilizan datos realistas en los entornos de prueba y desarrollo. Aquí es donde el reordenamiento de nombres y el enmascaramiento de datos entran en juego.
Dato interesante: La SSA (Administración del Seguro Social) publica datos sobre los nombres de bebés que se asignan cada año. En un año típico, hay entre 30,000 y 35,000 nombres únicos utilizados para recién nacidos.
Este artículo explorará el concepto de reordenamiento, su implementación y sus beneficios en la creación de datos de prueba seguros.
DataSunrise ofrece soluciones de enmascaramiento de datos de vanguardia, con potentes técnicas de reordenamiento. Nuestra plataforma avanzada garantiza una protección robusta de datos manteniendo la utilidad de los datos. Con DataSunrise, las organizaciones pueden cumplir con las regulaciones de privacidad y salvaguardar la información sensible con confianza. Experimenta el equilibrio perfecto entre seguridad y utilidad en tus procesos de gestión de datos.
DataSunrise permite la selección aleatoria de valores de léxicos definidos por el usuario. Estos léxicos pueden ser creados manualmente o poblados con valores de la base de datos. Este enfoque implementa no solo el reordenamiento, sino también la selección aleatoria de valores.
¿Qué es el Enmascaramiento de Datos?
Antes de profundizar en el reordenamiento de nombres, hablemos brevemente sobre el enmascaramiento de datos. El enmascaramiento de datos es un método utilizado para crear una versión estructuralmente similar pero inauténtica de los datos de una organización. Reemplaza la información sensible con datos realistas pero falsos. Esto permite que las empresas usen datos enmascarados para pruebas, desarrollo y análisis sin arriesgar la exposición de información confidencial.
Entendiendo el Reordenamiento de Nombres
¿Qué es el Reordenamiento de Nombres?
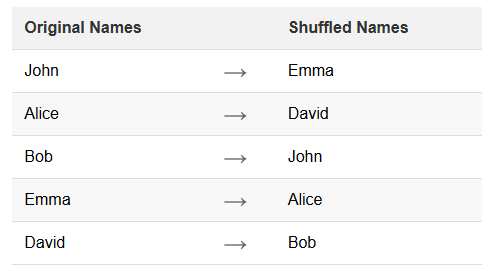
El reordenamiento de nombres es una técnica específica de enmascaramiento de datos. Implica reorganizar los datos existentes dentro de un conjunto de datos. Este método mantiene la integridad y el realismo de los datos mientras oculta las identidades individuales. El reordenamiento es particularmente útil para proteger la información personal en bases de datos.
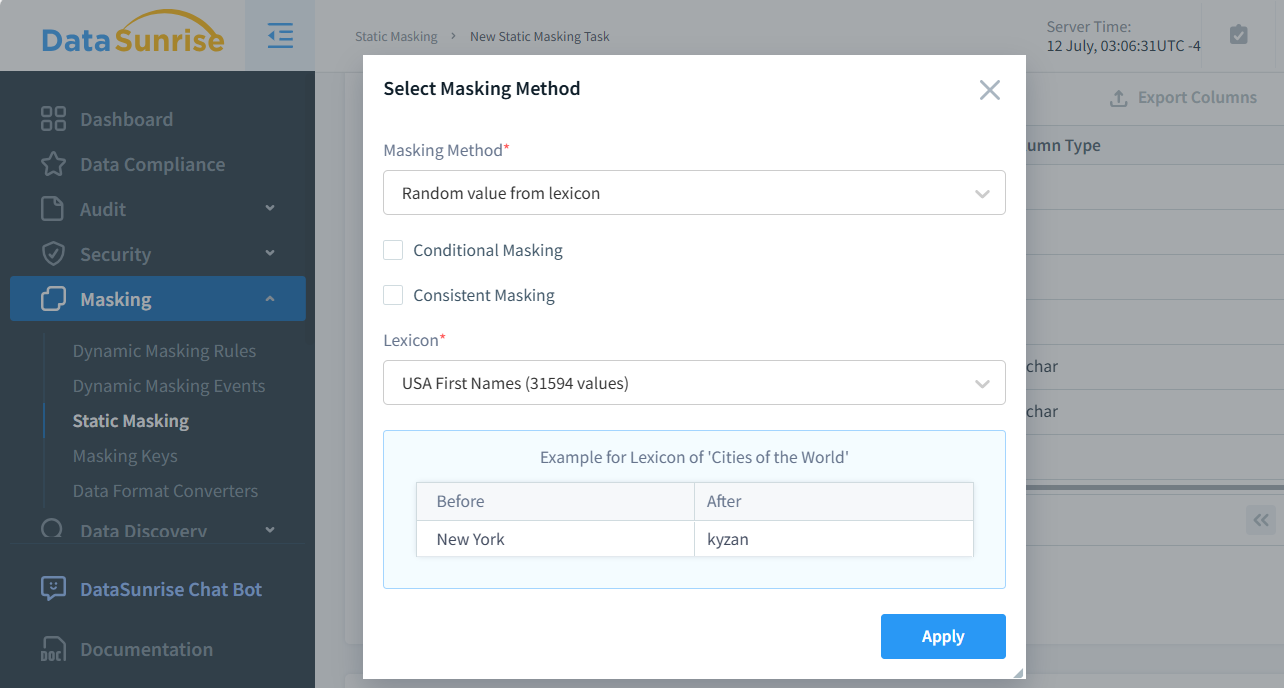
Como se mencionó en la Introducción, DataSunrise permite la selección de valores aleatorios basada en léxicos para el enmascaramiento. La figura a continuación muestra la selección de este método de enmascaramiento en la interfaz de usuario de DataSunrise. Como puedes ver, hay 31,594 valores disponibles, lo cual es mucho más confiable que simplemente reordenar un conjunto dado. Esta mayor confiabilidad se debe a que cuando hay n valores únicos en una columna, la probabilidad de que cualquier valor sea asignado a sí mismo es de 1/n.
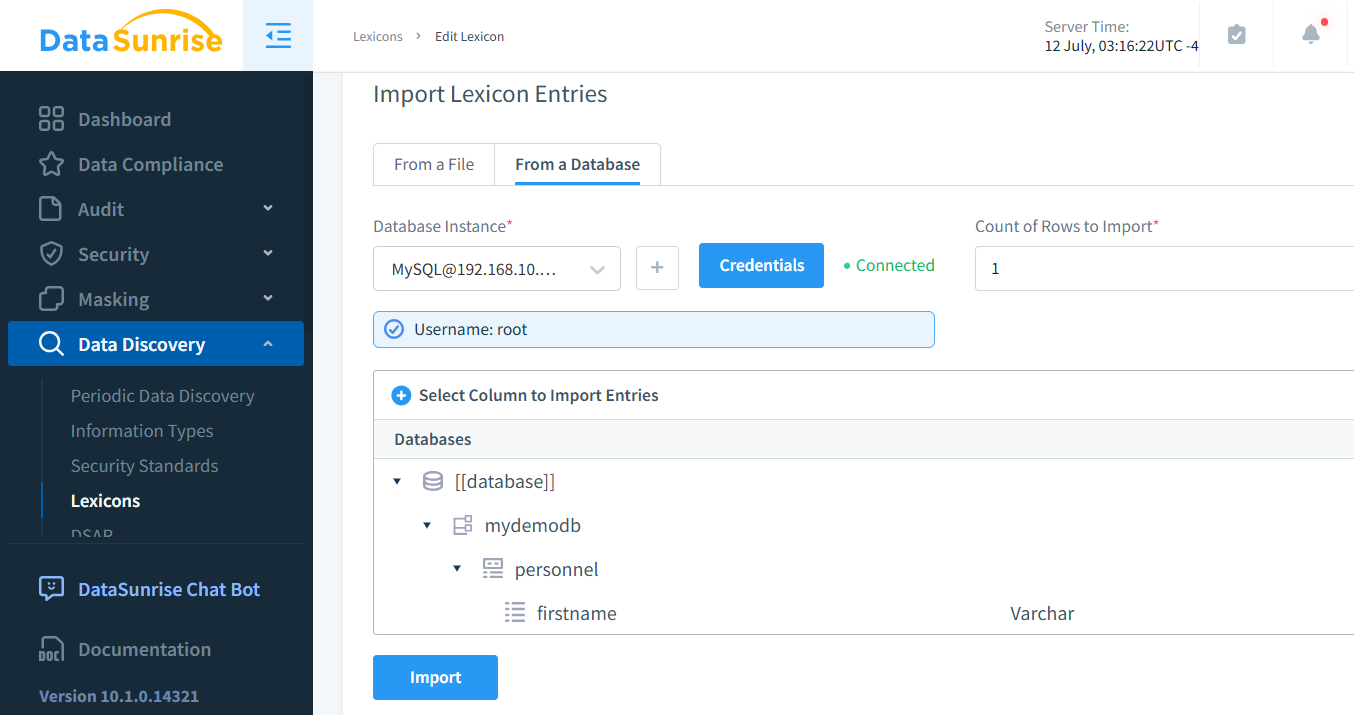
Si prefieres mapear con valores existentes, puedes lograrlo fácilmente creando un léxico personalizado. Este enfoque es particularmente beneficioso en situaciones donde los valores reordenados no son nombres de pila estadounidenses, ya que permite un enmascaramiento de datos más apropiado contextualmente.
¿Cómo Funciona el Reordenamiento de Nombres?
El proceso es sencillo:
- Seleccionar una columna que contenga nombres (nombres de pila, apellidos o ambos).
- Reordenar aleatoriamente los valores dentro de esa columna.
- Reemplazar los valores originales con los reordenados.
Esta técnica preserva la distribución y las características de los datos originales. Sin embargo, rompe la conexión entre los individuos y su información.
Implementando el Reordenamiento de Nombres en R y Python
Exploremos cómo implementar el reordenamiento de nombres más simple en dos lenguajes de programación populares: Python y R.
Es importante destacar que el nivel de usabilidad ofrecido por DataSunrise es incomparable en este contexto. Crear una solución flexible y todo en uno con solo unas pocas líneas de código no es factible usando lenguajes de programación estándar. Nuestro objetivo aquí es resaltar las capacidades de herramientas especializadas como DataSunrise en comparación con los lenguajes de programación de propósito general.
Reordenamiento de Nombres en Python
Python ofrece formas simples y eficientes de reordenar datos. Aquí hay un ejemplo usando pandas, una poderosa biblioteca de manipulación de datos:
import pandas as pd
import numpy as np
# Crear un conjunto de datos de muestra
data = pd.DataFrame({
'FirstName': ['John', 'Alice', 'Bob', 'Emma', 'David'],
'LastName': ['Smith', 'Johnson', 'Williams', 'Brown', 'Jones'],
'Age': [32, 28, 45, 36, 51],
'Salary': [50000, 60000, 75000, 65000, 80000]
})
# Reordenar la columna FirstName
data['FirstName'] = np.random.permutation(data['FirstName'])
# Reordenar la columna LastName
data['LastName'] = np.random.permutation(data['LastName'])
print(data)Este script crea un conjunto de datos de muestra y reordena las columnas FirstName y LastName. El resultado mantiene los nombres originales pero aleatoriza su orden, enmascarando efectivamente las identidades individuales.
Reordenamiento de Nombres en R
R también proporciona métodos sencillos para reordenar datos. Aquí hay un ejemplo:
# Crear un conjunto de datos de muestra
data <- data.frame(
FirstName = c("John", "Alice", "Bob", "Emma", "David"),
LastName = c("Smith", "Johnson", "Williams", "Brown", "Jones"),
Age = c(32, 28, 45, 36, 51),
Salary = c(50000, 60000, 75000, 65000, 80000)
)
# Reordenar la columna FirstName
data$FirstName <- sample(data$FirstName)
# Reordenar la columna LastName
data$LastName <- sample(data$LastName)
print(data)Este script de R logra el mismo resultado que el ejemplo de Python. Reordena las columnas FirstName y LastName, manteniendo la integridad de los datos mientras enmascara las identidades individuales.
Beneficios del Reordenamiento de Nombres
El reordenamiento de nombres ofrece varias ventajas:
- Mantiene el Realismo de los Datos: Los datos reordenados retienen las características del conjunto de datos original.
- Preserva la Distribución de los Datos: La frecuencia de los nombres permanece igual, siendo útil para análisis estadísticos.
- Implementación Sencilla: Es fácil de aplicar y entender.
- Reversible: Si es necesario, el proceso puede ser revertido con la clave adecuada.
Desafíos y Consideraciones
Aunque el reordenamiento de nombres es efectivo, es importante considerar:
- Unicidad: Los nombres raros aún pueden ser identificables.
- Consistencia: Asegura que el reordenamiento sea consistente en tablas relacionadas.
- Información Contextual: Otros campos de datos pueden aún revelar identidades.
Mejores Prácticas para el Reordenamiento de Nombres
Para maximizar la efectividad del reordenamiento de nombres:
- Usar Conjuntos de Datos Grandes: Cuanto más grande sea el conjunto de datos, más efectivo será el reordenamiento.
- Combinar Técnicas: Usa el reordenamiento de nombres junto con otros métodos de enmascaramiento para una mejor protección.
- Aplicación Consistente: Aplica el reordenamiento consistentemente en todos los datos relacionados.
- Actualizaciones Regulares: Reordena los datos periódicamente para prevenir la ingeniería inversa.
El Reordenamiento de Nombres en la Creación de Datos de Prueba
El reordenamiento de nombres es particularmente valioso en la creación de datos de prueba. Permite a los desarrolladores y evaluadores trabajar con datos realistas sin comprometer la privacidad. Aquí está la razón de por qué es crucial:
- Pruebas Realistas: Los nombres reordenados mantienen las características de los datos reales.
- Cumplimiento de Privacidad: Ayuda a cumplir con regulaciones de protección de datos.
- Desarrollo Sin Problemas: Los desarrolladores pueden usar datos que imitan de cerca los entornos de producción.
Conclusión
El reordenamiento de nombres es una potente técnica de enmascaramiento de datos. Ofrece un equilibrio entre la utilidad de los datos y la protección de la privacidad. Al implementar el reordenamiento de nombres, las organizaciones pueden crear datos de prueba realistas mientras salvaguardan la información sensible. A medida que aumentan las preocupaciones sobre la privacidad de los datos, métodos como el reordenamiento se volverán más importantes en la gestión de datos.
Para aquellos que buscan soluciones avanzadas de enmascaramiento de datos, DataSunrise ofrece herramientas fáciles de usar y flexibles para la seguridad de bases de datos. Nuestra herramienta integral de enmascaramiento dinámico y enmascaramiento estático incluye capacidades robustas de reordenamiento y cifrado. Visita el sitio web de DataSunrise para una demostración en línea y explora cómo nuestras soluciones pueden mejorar tus estrategias de protección de datos.
