
Datos Basura

En el mundo impulsado por datos de hoy en día, la calidad de la información juega un papel crucial en los procesos de toma de decisiones. Sin embargo, las organizaciones suelen enfrentar el desafío de los datos basura porque no todos los datos son lo suficientemente buenos. Este artículo examina dicho procesamiento de datos, cómo impacta los conjuntos de datos y también ofrecemos soluciones para mantener la precisión de los datos.
¿Qué son los Datos Basura?
Los datos basura se refieren a información que es inexacta, incompleta, irrelevante o corrupta dentro de un conjunto de datos. También puede contener errores humanos. Estos datos toman varias formas, tales como:
- Entradas duplicadas
- Información desactualizada
- Errores de formato
- Registros incompletos
- Puntos de datos irrelevantes
Estos datos pueden hacer que el análisis de datos sea menos efectivo y resultar en conclusiones incorrectas si no se corrige.
El Impacto de los Datos Basura en el Análisis de Datos
Los datos basura pueden tener consecuencias de gran alcance en el proceso de análisis de datos. Aquí hay algunas formas clave en las que afectan la integridad y utilidad de tus datos:
1. Resultados Sesgados
Cuando hay datos engañosos en un conjunto de datos, puede conducir a cálculos estadísticos inexactos y tendencias mal representadas. Este sesgo de resultados puede causar que las organizaciones tomen malas decisiones basadas en información errónea.
2. Reducción de la Eficiencia
Procesar y analizar datos consume tiempo y recursos valiosos. Los analistas de datos pueden pasar horas limpiando y clasificando información irrelevante, reduciendo la productividad general.
3. Aumento de Costos
La presencia de datos duplicados a menudo requiere espacio de almacenamiento adicional y potencia de procesamiento. Esto puede llevar a un aumento en los costos de infraestructura para las organizaciones que manejan grandes volúmenes de datos.
4. Pérdida de Credibilidad
Los conocimientos derivados de datos incorrectos pueden erosionar la confianza en los procesos de toma de decisiones de una organización. Esta pérdida de credibilidad puede tener efectos duraderos en las operaciones internas y las relaciones externas.
Enfoques de Clasificación de Datos Usando Herramientas de Código Abierto
Para gestionar efectivamente los datos basura, las organizaciones pueden implementar varios enfoques de clasificación de datos. Aquí hay algunas herramientas de código abierto que pueden ayudar en este proceso:
1. Apache NiFi
Apache NiFi es una potente herramienta de integración y procesamiento de datos que puede ayudar a clasificar y enrutar datos basados en reglas predefinidas. Ofrece una interfaz fácil de usar para crear flujos de datos y aplicar filtros para identificar y segregar datos basura.
Ejemplo:
Flujo de Clasificación de Datos en Apache NiFi
- Crear un nuevo grupo de procesos
- Añadir un procesador GetFile para ingerir datos
- Conectarlo a un procesador RouteOnAttribute
- Definir reglas para clasificar datos (por ejemplo, ${filename:contains(‘junk’)})
- Enrutar los datos clasificados a los destinos apropiados
Resultado: Esta configuración clasificará automáticamente los archivos entrantes basados en sus atributos y los enrutará en consecuencia. Ayuda a aislar datos potencialmente malos para un procesamiento o eliminación posterior.
2. OpenRefine
OpenRefine (anteriormente Google Refine) es una herramienta versátil para limpiar y transformar datos desordenados. Proporciona características para detectar y eliminar entradas duplicadas, estandarizar formatos y agrupar puntos de datos similares.
Ejemplo:
Detección de Duplicados en OpenRefine
- Cargar tu conjunto de datos en OpenRefine
- Seleccionar la columna que contiene posibles duplicados
- Elegir “Facet” > “Customized facets” > “Duplicates facet”
- Revisar y fusionar o eliminar entradas duplicadas
Resultado: Este proceso identificará registros duplicados en tu conjunto de datos, permitiéndote limpiar la información redundante.
3. Talend Open Studio
Talend Open Studio (retirado) es una plataforma de integración de datos de código abierto que incluye herramientas potentes para la calidad y el perfilado de datos. Puede ayudar a identificar patrones y anomalías en tus datos.
Ejemplo:
Análisis de la Calidad de Datos en Talend
- Crear un nuevo trabajo en Talend Open Studio
- Arrastrar un componente tFileInputDelimited para leer tus datos
- Conectarlo a un componente tDataProfiler
- Configurar el perfilador para analizar columnas específicas
- Ejecutar el trabajo y revisar el informe de calidad de los datos
Resultado: Este trabajo generará un informe completo sobre la calidad de tus datos, resaltando posibles problemas de datos basura como valores faltantes, valores atípicos e inconsistencias de formato.
Evitar la Eliminación o el Uso Indebido de Datos Sensibles
Al procesar datos malos, es crucial asegurar que la información sensible no se elimine o se utilice indebidamente de manera accidental. Aquí hay algunas mejores prácticas a seguir:
1. Implementar Enmascaramiento de Datos
Utiliza técnicas de enmascaramiento de datos para oscurecer la información sensible mientras se preserva la estructura general de los datos. Esto permite el análisis sin exponer detalles confidenciales.
2. Establecer Controles de Acceso
Implementar controles de acceso estrictos para asegurar que solo el personal autorizado pueda ver y manipular datos sensibles durante la fase de procesamiento de datos basura.
3. Mantener Registros de Auditoría
Guardar registros detallados de todas las actividades de procesamiento de datos, incluyendo quién accedió a los datos, qué cambios se realizaron y cuándo. Esto ayuda a rastrear cualquier posible uso indebido o eliminación accidental de información importante.
4. Utilizar Etiquetas de Clasificación de Datos
Aplicar etiquetas de clasificación a tus datos, marcando claramente la información sensible. Esto ayuda a identificar qué datos requieren un manejo especial durante el proceso de eliminación de datos basura.
Requisitos Legales para el Procesamiento de Datos Basura
Varias regulaciones y estándares gobiernan el manejo de datos, incluyendo el procesamiento de datos basura. Algunos de los requisitos clave se muestran en el siguiente diagrama:
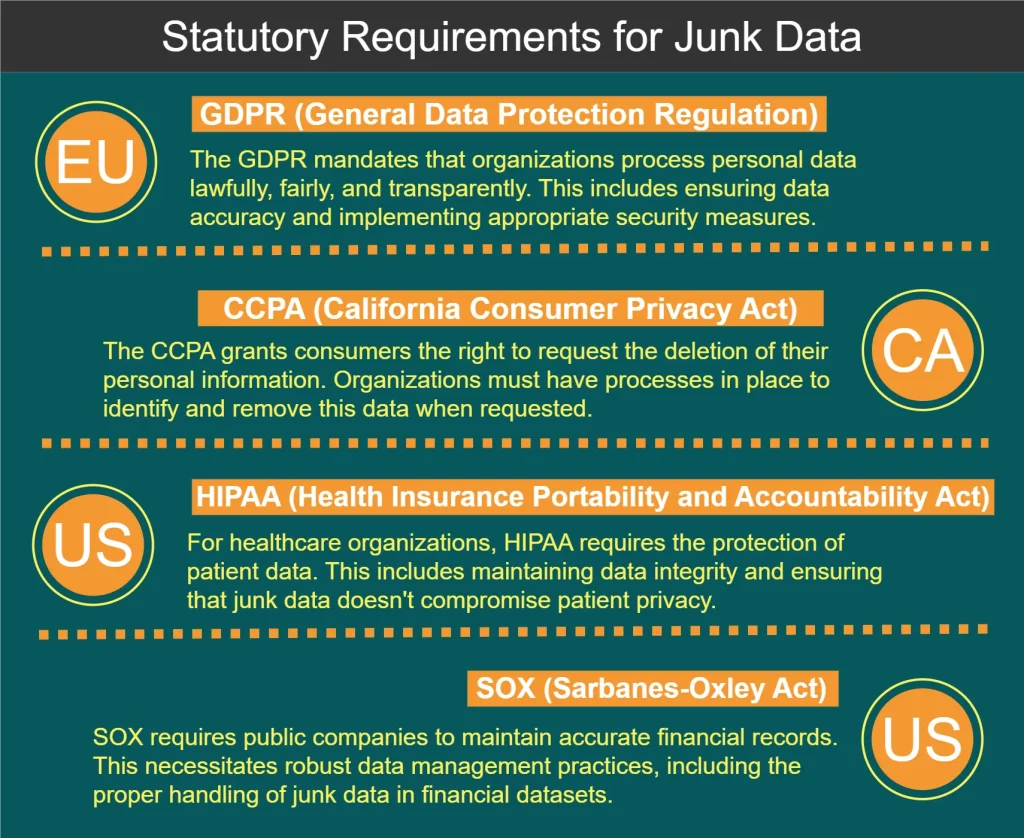
Mejores Prácticas para el Procesamiento de Datos Basura
Para gestionar efectivamente los datos y mantener la integridad de los datos, considera las siguientes mejores prácticas:
- Implementar la validación de datos en el punto de entrada para evitar que los datos basura ingresen a tus sistemas.
- Auditar regularmente tus conjuntos de datos para identificar y abordar problemas de calidad de los datos.
- Desarrollar una política integral de gobernanza de datos que incluya pautas para el manejo de datos basura.
- Invertir en capacitación de empleados para asegurar que todos los miembros del equipo entiendan la importancia de la calidad de los datos.
- Utilizar herramientas automatizadas para agilizar el proceso de identificación y eliminación de datos basura.
- Implementar un sistema de puntuación de calidad de datos para rastrear mejoras a lo largo del tiempo.
- Establecer un ciclo de retroalimentación con los usuarios de datos para identificar y abordar rápidamente los problemas de calidad de los datos.
Al final de este artículo, también mencionamos cómo implementar métodos simples de detección de datos basura en Python.
Análisis de Datos e Identificación de Datos Basura Usando Python
Python se ha convertido en un lenguaje de referencia para el análisis de datos debido a su simplicidad, versatilidad y robusto ecosistema de librerías centradas en datos. Aquí hay algunas formas de analizar datos e identificar datos basura usando Python:
1. Pandas para la Manipulación y Análisis de Datos
Pandas es una poderosa librería para la manipulación y análisis de datos en Python. Proporciona estructuras de datos como DataFrames que facilitan trabajar con datos estructurados.
Ejemplo: Identificación de valores faltantes y duplicados
import pandas as pd
# Cargar datos en un DataFrame
df = pd.read_csv('your_data.csv')
# Verificar valores faltantes
missing_values = df.isnull().sum()
# Identificar filas duplicadas
duplicates = df.duplicated().sum()
print("Valores faltantes:\n", missing_values)
print("Número de filas duplicadas:", duplicates)Resultado: Este script mostrará el conteo de valores faltantes para cada columna y el número total de filas duplicadas en tu conjunto de datos, ayudándote a identificar posibles datos basura.
2. Matplotlib y Seaborn para la Visualización de Datos
Visualizar tus datos puede ayudar a identificar valores atípicos y patrones inusuales que podrían indicar datos basura.
Ejemplo: Creación de un diagrama de caja para detectar valores atípicos
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Cargar datos
df = pd.read_csv('your_data.csv')
# Crear un diagrama de caja
plt.figure(figsize=(10, 6))
sns.boxplot(x='category', y='value', data=df)
plt.title('Distribución de Valores por Categoría')
plt.show()Resultado: Esto generará un diagrama de caja que representa visualmente la distribución de valores en diferentes categorías, haciendo que sea fácil detectar valores atípicos que podrían ser datos basura.
3. Scikit-learn para la Detección de Anomalías
Scikit-learn ofrece algoritmos de aprendizaje automático que pueden usarse para la detección de anomalías, ayudando a identificar puntos de datos inusuales que podrían ser basura.
Ejemplo: Uso de Isolation Forest para la detección de anomalías
import pandas as pd
from sklearn.ensemble import IsolationForest
# Cargar y preparar datos
df = pd.read_csv('your_data.csv')
X = df[['feature1', 'feature2']] # Seleccionar características relevantes
# Crear y ajustar el modelo
iso_forest = IsolationForest(contamination=0.1, random_state=42)
outliers = iso_forest.fit_predict(X)
# Agregar resultados al DataFrame
df['is_outlier'] = outliers
# Ver datos potencialmente basura (anomalías)
junk_data = df[df['is_outlier'] == -1]
print(junk_data)Resultado: Este script utilizará el algoritmo Isolation Forest para identificar posibles valores atípicos en tu conjunto de datos, lo que podría indicar datos basura.
4. Funciones Personalizadas para Verificaciones de Calidad de Datos
Puedes crear funciones personalizadas en Python para realizar verificaciones de calidad de datos específicas a tu conjunto de datos.
Ejemplo: Verificación de valores poco realistas en un conjunto de datos de temperatura
import pandas as pd
def check_temperature_range(df, column, min_temp, max_temp):
"""Verificar si los valores de temperatura están dentro de un rango realista."""
outliers = df[(df[column] < min_temp) | (df[column] > max_temp)]
return outliers
# Cargar datos
df = pd.read_csv('temperature_data.csv')
# Verificar temperaturas poco realistas (por ejemplo, por debajo de -100°C o por encima de 60°C)
junk_temps = check_temperature_range(df, 'temperature', -100, 60)
print("Lecturas de temperatura potencialmente basura:")
print(junk_temps)Resultado: Esta función identificará lecturas de temperatura que caen fuera de un rango específico y realista, ayudando a detectar potencialmente datos erróneos o basura.
5. Perfilado de Datos con ydata-profiling
La librería ydata-profiling (anteriormente pandas-profiling) proporciona una forma fácil de generar informes comprensivos sobre tu conjunto de datos, incluyendo posibles problemas de calidad.
Ejemplo: Generación de un informe de perfil de datos
import pandas as pd
from ydata_profiling import ProfileReport
# Cargar datos
df = pd.read_csv('your_data.csv')
# Generar informe
profile = ProfileReport(df, title="Informe de Perfilado de Datos", explorativo=True)
# Guardar informe en archivo
profile.to_file("data_profile_report.html")Resultado: Este script generará un informe HTML con estadísticas detalladas, visualizaciones y posibles problemas de calidad en tu conjunto de datos, proporcionando una visión comprensiva que puede ayudar a identificar datos basura.
Al incorporar estas técnicas basadas en Python en tu flujo de trabajo de análisis de datos, puedes identificar y abordar más efectivamente los problemas de datos basura, mejorando la calidad y confiabilidad general de tus conjuntos de datos.
Conclusión: El Camino hacia una Mejor Integridad de los Datos
El procesamiento de datos basura es un aspecto crítico para mantener la integridad de los datos y asegurar la fiabilidad de tus esfuerzos de análisis de datos. Mediante el uso de fuertes métodos de clasificación, herramientas gratuitas y el seguimiento de normas, las organizaciones pueden mejorar enormemente la calidad de sus datos.
Recuerda que la limpieza de datos es un esfuerzo continuo que requiere una vigilancia constante y adaptación a paisajes de datos en evolución. Al priorizar la calidad de los datos e implementar estrategias efectivas de procesamiento de datos engañosos, las organizaciones pueden desbloquear el verdadero potencial de sus datos y tomar decisiones más informadas.
Para herramientas fáciles de usar y flexibles diseñadas para mejorar la seguridad de los datos y garantizar el cumplimiento, considera explorar las ofertas de DataSunrise. Visita nuestro sitio web en DataSunrise.com para una demostración en línea y descubre cómo podemos ayudarte a mantener la integridad de los datos mientras cumples con los requisitos regulatorios.
