
Datos de Clúster: Cómo Funcionan y Cómo Usarlos

Los datos de clúster son una técnica poderosa que ayuda a descubrir patrones y tendencias ocultas en grandes conjuntos de datos. Agrupa objetos similares, lo que facilita el análisis y la comprensión de información compleja. Los científicos de datos usan la agrupación para identificar rápidamente temas, detectar anomalías y obtener valiosos conocimientos a partir de grandes cantidades de datos.
¿Qué es la Agrupación de Datos?
En esencia, la agrupación de datos es un método no supervisado de aprendizaje automático. No requiere datos etiquetados ni categorías predefinidas. En cambio, el algoritmo encuentra agrupaciones naturales dentro del conjunto de datos basándose en la similitud. Agrupamos los objetos similares en el mismo grupo y separamos los diferentes objetos.
El proceso es flexible y puede funcionar con diversos tipos de datos:
- Documentos
- Puntos en un gráfico
- Respuestas a encuestas
- Secuencias genéticas
Siempre que haya una forma de medir la similitud entre dos objetos, se puede aplicar la agrupación. Esta variedad lo convierte en una herramienta clave para la analítica exploratoria de datos en distintas industrias.
Análisis de Datos de Clúster en Acción
Imagina que gestionas un sitio de comercio electrónico con miles de productos. Quieres entender mejor el comportamiento del cliente y personalizar las recomendaciones. Al agrupar tus datos de productos, podrías descubrir grupos interesantes:
- Los más vendidos que se compran frecuentemente juntos
- Artículos nicho que atraen a demografías específicas
- Tendencias estacionales en torno a vacaciones o eventos
Estos conocimientos pueden informar estrategias de marketing, gestión de inventarios y diseño de sitios web. Puedes resaltar paquetes de productos populares, adaptar campañas de correo electrónico a segmentos de clientes y optimizar la navegación basándote en patrones de navegación.
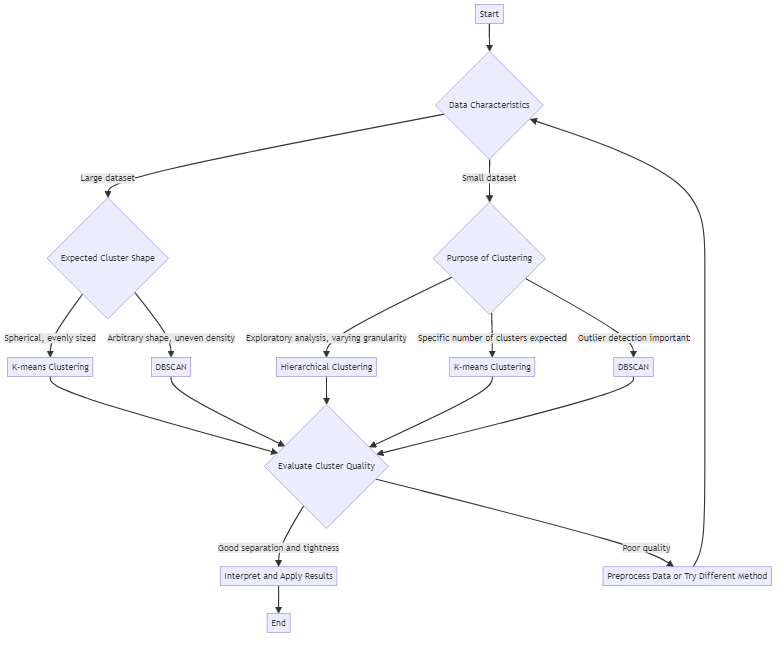
Elegir el Algoritmo de Agrupación Correcto
Diferentes algoritmos de agrupación se adaptan a diferentes propósitos. Algunos comunes incluyen:
- K-means: Divide los datos en un número predefinido (k) de clústeres de datos. Funciona bien cuando tienes una idea de cuántos grupos esperar.
- Agrupación jerárquica: Construye clústeres de datos anidados en una estructura de árbol. Útil para visualizar datos a diferentes niveles de granularidad.
- DBSCAN: Identifica clústeres de formas arbitrarias y marca valores atípicos. Maneja conjuntos de datos con ruido y densidad desigual.
La elección correcta depende de factores como el tamaño de los datos, la forma esperada del clúster y la tolerancia a valores atípicos. A menudo vale la pena probar múltiples enfoques para ver cuál arroja resultados más significativos.
Evaluación de la Calidad del Clúster de Datos
No todos los clústeres se crean de la misma manera. Un buen resultado de agrupación tiene grupos compactos y bien separados. Los objetos dentro de un clúster deben ser muy similares, mientras que los objetos en diferentes clústeres deben ser distintos. Las puntuaciones de silueta y las técnicas de visualización pueden ayudar a evaluar la calidad del clúster de datos.
Validar los clústeres contra el conocimiento del dominio es crucial para garantizar la precisión y relevancia de los resultados de la agrupación. Podemos ver si los clústeres se alinean con las opiniones de los expertos o los objetivos comerciales. Esto nos ayudará a determinar si son adecuados para el dominio o la industria específicos. Este proceso de validación ayuda a confirmar que los clústeres son significativos y útiles para la toma de decisiones.
La agrupación ayuda a encontrar patrones en los datos, pero solo es el comienzo. Los humanos deben interpretar los resultados de la agrupación para extraer conocimientos accionables y tomar decisiones informadas. Usando tanto números como opiniones de expertos, podemos entender mejor los datos y cómo afectan al negocio.
En resumen, validar los clústeres contra el conocimiento del dominio e interpretar los resultados son pasos esenciales en el proceso de agrupación. Aseguramos que los grupos sean útiles y prácticos utilizando conocimiento y juicio en un campo específico. Esto contribuirá en última instancia al éxito del negocio.
Aplicaciones de los Datos de Clúster
Los casos de uso de los datos de clúster abarcan diversos dominios:
- Segmentación de clientes para marketing dirigido
- Detección de anomalías en la prevención de fraudes
- Compresión de imágenes y reconocimiento de patrones
- Bioinformática y análisis de expresión génica
- Análisis de redes sociales y detección de comunidades
Dondequiera que haya datos complejos para desentrañar, la agrupación proporciona un punto de partida valioso. Simplifica el panorama de los datos y revela estructuras clave para una investigación más profunda.
Mejores Prácticas en Datos de Clúster
Para aprovechar al máximo los datos de clúster, ten en cuenta estos consejos:
- Preprocesar y normalizar los datos para asegurar comparaciones justas
- Experimentar con diferentes métricas de distancia y algoritmos
- Validar los resultados utilizando medidas estadísticas y experiencia del dominio
- Visualizar los clústeres de datos para comunicar los conocimientos de manera efectiva
- Iterar y refinar el proceso a medida que nuevos datos estén disponibles
Con una implementación adecuada, los datos de clúster pueden marcar la diferencia. Transforman conjuntos de datos abrumadores en inteligencia accionable, permitiendo a las organizaciones tomar decisiones más inteligentes.
Poner en Práctica los Datos de Clúster
Desbloquea el poder de tus datos con la agrupación. El análisis de clústeres es una herramienta crucial para los profesionales de marketing, investigadores y científicos de datos. Ayuda a obtener conocimientos de los clientes, explorar redes genéticas y resolver problemas complejos. Comienza a explorar el mundo de la agrupación de datos y descubre patrones ocultos hoy mismo.
