
Descubrimiento de Datos
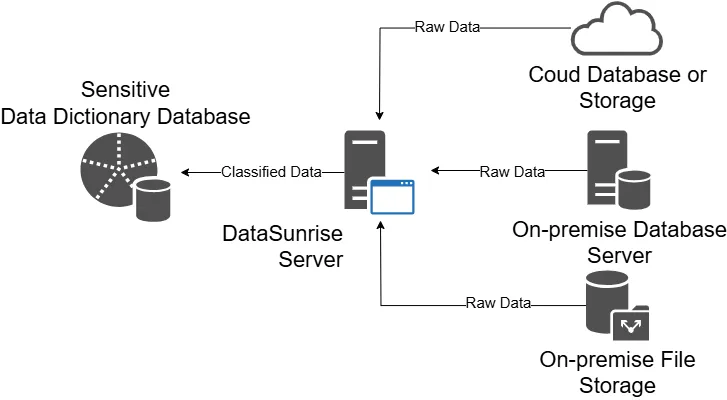
¿Alguna vez te has preguntado, qué métricas están disponibles en tus datos? ¿Hay métricas disponibles para la Tasa de Abandono y la Tasa de Retención? O tal vez estás luchando con los procedimientos de cumplimiento, preguntándote, ‘¿Estoy en peligro de fuga de datos sensibles?’ El descubrimiento de datos es un proceso crucial que ayuda a las empresas y organizaciones a entender sus vastos activos de datos. Incluye la búsqueda de datos desde diferentes lugares para encontrar tendencias, patrones y tipos de datos.
Las empresas pueden descubrir información importante y mejorar la inteligencia empresarial al entender mejor sus datos. Esto también ayuda con la seguridad de datos, la gobernanza y la privacidad. Cuando falla el proceso de datos, el descubrimiento de datos ayuda a encontrar qué está mal con los datos.
El Poder del Descubrimiento de Datos
Las organizaciones hoy en día pueden tener una cantidad abrumadora de datos para manejar. Esto puede resultar en “datos oscuros” que permanecen sin usar. Los datos oscuros pueden potencialmente crear riesgos legales y de seguridad. Hay varias razones para implementar el descubrimiento de datos.

Los analistas pueden usar catálogos de datos y diccionarios para encontrar y organizar datos dispersos. Luego pueden limpiar y combinar los datos para descubrir información importante.
Mejorando el Descubrimiento de Datos con IA y Aprendizaje Automático
DataSunrise hace gran uso de herramientas de ML para la seguridad de datos. La Inteligencia Artificial (IA) está transformando los procesos de descubrimiento de datos en gobernanza de datos. Al aprovechar la IA y el aprendizaje automático, las organizaciones pueden optimizar sus esfuerzos de exploración de datos. Esto conduce a información más rápida y toma de decisiones más eficiente.
La IA mejora el descubrimiento de datos de varias maneras clave:
- Automatizando la clasificación de datos
- Identificando patrones y anomalías
- Sugiriendo fuentes de datos relevantes
Los algoritmos de aprendizaje automático sobresalen en categorizar grandes cantidades de información. Esta clasificación automática de datos ahorra tiempo y reduce el error humano. Es particularmente útil al manejar grandes conjuntos de datos.
El Descubrimiento de Datos en la Ciencia de Datos
El descubrimiento de datos forma la base de proyectos exitosos de ciencia de datos. Es el proceso de encontrar y entender las fuentes de datos disponibles. A través de esta exploración, los científicos de datos descubren información y patrones valiosos. Un descubrimiento de datos efectivo involucra varios pasos clave:
- Identificación de fuentes de datos relevantes
- Evaluación de la calidad y completitud de los datos
- Realización de análisis de datos iniciales
La clasificación de datos juega un papel vital en este proceso. Al categorizar la información, los científicos pueden organizar y priorizar mejor su trabajo. Esta clasificación ayuda a manejar adecuadamente los datos sensibles.
DataSunrise ofrece un excelente soporte para el almacenamiento de datos y almacenes comúnmente utilizados en la ciencia de datos, incluyendo Snowflake, Amazon Redshift y Athena, por mencionar algunos.
Dado que la ciencia de datos utiliza en gran medida datos semi-estructurados, DataSunrise apoya el descubrimiento de datos en formatos brutos (CSV, JSON) ubicados en almacenamientos como S3 o en tu sistema de archivos.
Empoderando la Inteligencia Empresarial con el Descubrimiento de Datos
El descubrimiento de datos juega un papel vital en empoderar iniciativas de inteligencia empresarial.
Dar a los analistas las herramientas y técnicas adecuadas ayuda a las organizaciones a tomar mejores decisiones, mejorar procesos y encontrar oportunidades de crecimiento.
Los tableros pueden ser modificados para adaptarse a diferentes grupos de personas, como ejecutivos y empleados de primera línea. De esta manera, todos pueden encontrar fácilmente la información que necesitan para tomar decisiones.
Seguridad de Datos y Cumplimiento con Descubrimiento de Datos basado en Python
Bien, podrías decir, hay decenas de herramientas de Python de código abierto disponibles en el mercado. Todo lo que necesito hacer es tomar un par y crear mi propia cadena de herramientas de descubrimiento de datos.
Y esta es una idea totalmente válida por varias razones. Conocerás todo sobre tus herramientas, y podrás implementar cualquier descubrimiento de datos que desees en el futuro. Además, el costo total de propiedad de esta simple cadena de herramientas es solo tu tiempo para escribir algo de código.
El posible inconveniente es el siguiente: puede tomar un tiempo implementar todas las variaciones que desees. Podrías tener dificultades con la escalabilidad y el soporte de tu sistema a medida que salgan nuevas bases de datos y cambien su comportamiento del controlador.
A continuación se muestra el código para descubrir correos electrónicos en una base de datos PostgreSQL. Debería funcionar con tus parámetros de conexión de base de datos. Puedes notar que si bien no es ciencia espacial, aún requiere algo de conocimiento de infraestructura y Python. Y este código no almacena los resultados de búsqueda.
import psycopg2
import re
# Define los parámetros de conexión
db_params = {
'dbname': 'mydatabase01',
'user': 'postgres',
'password': 'pass',
'host': 'localhost'
}
# Conectar a la base de datos
try:
conn = psycopg2.connect(**db_params)
print("Conectado a la base de datos")
except Exception as e:
print(f"No se pudo conectar a la base de datos: {e}")
exit()
# Función para encontrar direcciones de correo electrónico en un esquema
def find_emails_in_schema(schema):
try:
cursor = conn.cursor()
# Consulta para encontrar todas las tablas en el esquema especificado
cursor.execute(f"""
SELECT table_name
FROM information_schema.tables
WHERE table_schema = '{schema}'
""")
tables = cursor.fetchall()
email_pattern = re.compile(r'[\w\.-]+@[\w\.-]+')
for table in tables:
table_name = table[0]
# Consulta para seleccionar todas las columnas de la tabla
cursor.execute(f"""
SELECT column_name
FROM information_schema.columns
WHERE table_schema = '{schema}'
AND table_name = '{table_name}'
""")
columns = cursor.fetchall()
# Seleccionar todos los datos de la tabla
cursor.execute(f'SELECT * FROM {schema}.{table_name}')
rows = cursor.fetchall()
for row in rows:
for column, value in zip(columns, row):
if value and isinstance(value, str):
if email_pattern.search(value):
print(f'Correo electrónico encontrado: {value} en tabla: {table_name}, columna: {column[0]}')
except Exception as e:
print(f"Error al encontrar correos electrónicos: {e}")
finally:
cursor.close()
# Especificar el esquema para buscar
schema_name = 'public'
find_emails_in_schema(schema_name)
# Cerrar la conexión
conn.close()
El código imprime líneas como la siguiente:
Correo electrónico encontrado: sclutten0@facebook.com en tabla: mock_data, columna: email
Herramientas de DataSunrise
DataSunrise incluye todas las características que necesitas para el descubrimiento de datos sensibles (o cualquier tipo de datos). A continuación, proporcionamos un par de ejemplos de su interfaz de usuario.
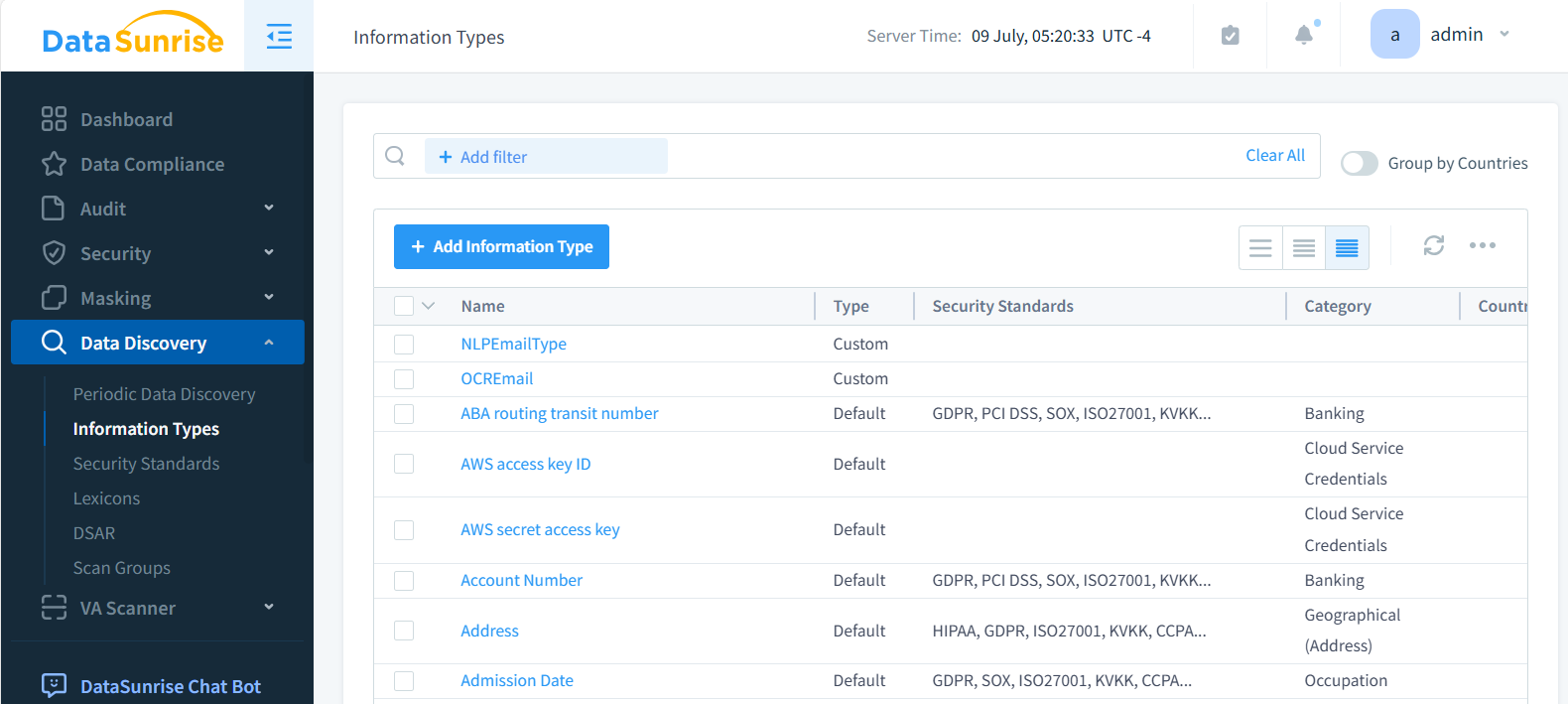
Lo siguiente es una lista de Tipos de Información. Puedes crear tantos tipos de información personalizados como desees, cada uno con uno o varios atributos para el descubrimiento. También puedes usar docenas de tipos incorporados si lo prefieres.
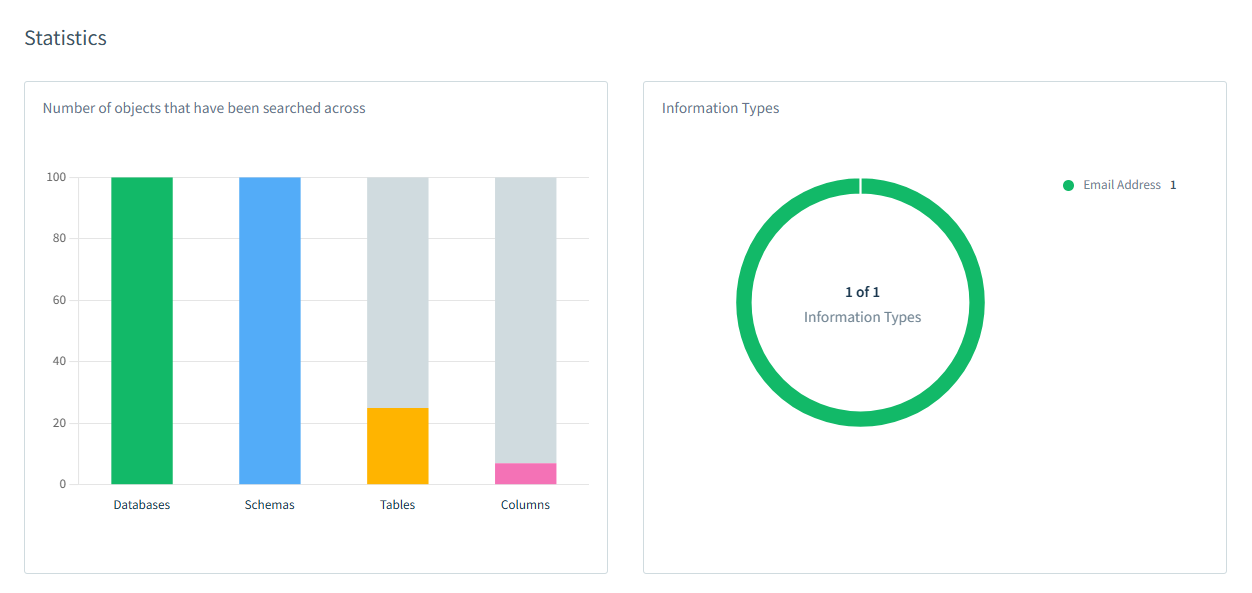
Después de que la tarea de descubrimiento termine, puedes ver información detallada sobre los hallazgos. Además, puedes estimar la cantidad de datos descubiertos en relación con la cantidad total en tus esquemas, tablas o columnas. La imagen a continuación muestra que se encontraron direcciones de correo electrónico en el 100% de las bases de datos objetivo, 100% de esquemas, 22% de tablas y menos del 5% de columnas.
Conclusión
El descubrimiento de datos es un proceso crítico que permite a las organizaciones desbloquear todo el potencial de sus activos de datos.
Las empresas pueden utilizar tecnologías avanzadas como IA, aprendizaje automático y análisis de datos para entender mejor sus datos. Las empresas pueden usar datos para encontrar patrones y tendencias, ayudando a tomar mejores decisiones y promover la innovación.
Estas tecnologías también pueden ayudar a las empresas a generar nuevas ideas al descubrir oportunidades ocultas y predecir tendencias futuras del mercado.
Además, las tecnologías avanzadas pueden ayudar a las empresas a proteger la información sensible mediante la implementación de medidas de seguridad robustas como cifrado, controles de acceso y sistemas de detección de amenazas. Proteger los datos ayuda a las empresas a evitar violaciones de datos y ataques cibernéticos, manteniendo su información segura y protegida.
El uso de tecnologías avanzadas puede ayudar a las empresas a utilizar mejor sus datos, ser más innovadoras y proteger su información sensible. Esto puede conducir a un mejor rendimiento y una ventaja competitiva en el mercado.
A medida que crecen los datos, es importante que las organizaciones inviertan en herramientas para el descubrimiento de datos para mantenerse a la vanguardia.
DataSunrise proporciona una amplia variedad de medios para descubrir datos. Contacta a nuestro equipo para reservar una demostración y aprender cómo hacerlo ahora.
