
Enmascaramiento Dinámico de Datos en PostgreSQL

PostgreSQL, un poderoso sistema de base de datos de código abierto, ofrece varias características de seguridad para proteger datos sensibles. Una de estas características es el enmascaramiento dinámico de datos. Esta técnica ayuda a las organizaciones a salvaguardar la información confidencial sin modificar los datos originales. Vamos a explorar cómo funciona el enmascaramiento dinámico de datos en PostgreSQL y por qué es crucial para la protección de datos.
¿Qué es el Enmascaramiento Dinámico de Datos?
El enmascaramiento dinámico de datos es un método de seguridad que oculta datos sensibles en tiempo real. Transforma los datos a medida que se recuperan de la base de datos. La información original permanece intacta, pero los usuarios solo ven versiones enmascaradas o alteradas. Este enfoque asegura la protección de datos sensibles al tiempo que permite a los usuarios autorizados acceder a la información necesaria.
Implementación del Enmascaramiento Dinámico de Datos en PostgreSQL
PostgreSQL implementa el enmascaramiento dinámico de datos a través de vistas y políticas de seguridad a nivel de fila. Estas características permiten a los administradores de bases de datos controlar qué datos pueden ver los usuarios según sus roles y permisos.
Para implementar el enmascaramiento dinámico de datos nativamente en PostgreSQL, puedes crear vistas que alteren las columnas sensibles. Aquí hay un ejemplo:
CREATE VIEW masked_customers AS SELECT id, CASE WHEN current_user = 'admin' THEN full_name ELSE 'REDACTED' END AS full_name, CASE WHEN current_user = 'admin' THEN email ELSE LEFT(email, 2) || '****' || RIGHT(email, 4) END AS email, city, state FROM customers;
Esta vista enmascara las columnas full_name y email para los usuarios que no son administradores. Los administradores tienen la capacidad de ver los datos originales, mientras que otros usuarios ven información redactada o parcialmente enmascarada.
Sin embargo, esto puede ser complicado de llevar a cabo en un almacenamiento a gran escala. Para simplificar el proceso, sugerimos usar soluciones de terceros. Para operar en DataSunrise, primero debes crear una instancia de la base de datos requerida.
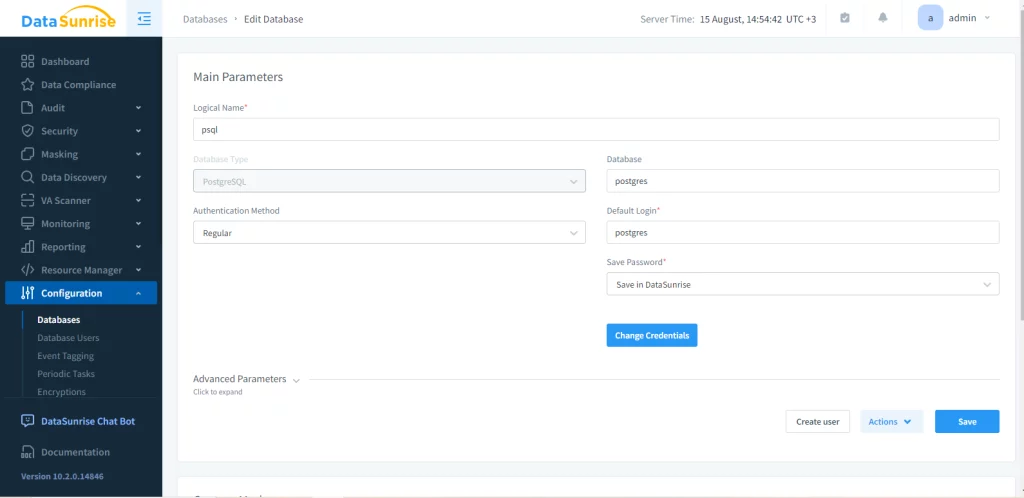
Ahora, puedes crear varios tipos de reglas para el proxy de la instancia de la base de datos. Para el enmascaramiento dinámico de datos necesitamos proceder al menú correspondiente y agregar una nueva regla. En este ejemplo, enmascararemos la columna ‘first_name’ de la tabla ‘gauss_types1’ en la base de datos ‘Test’.
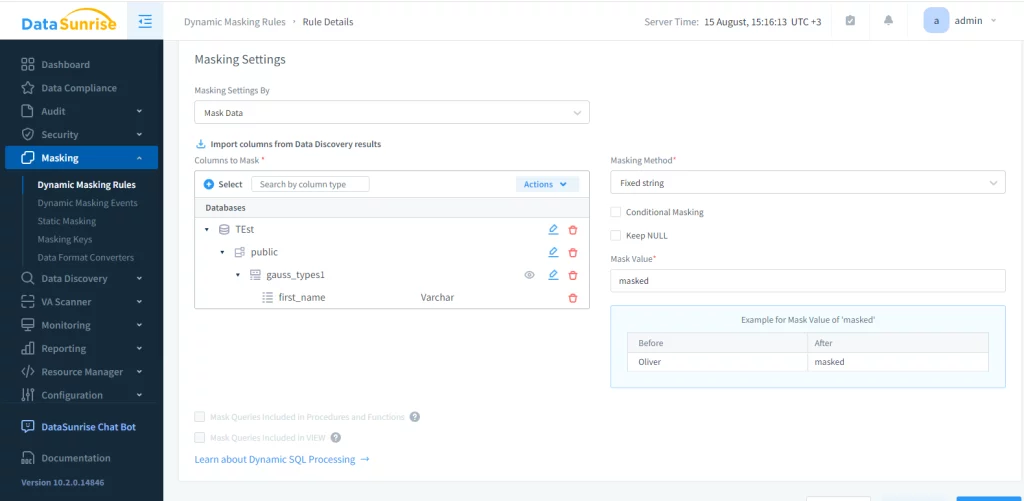
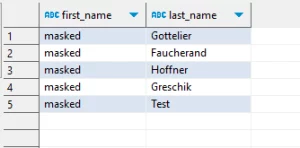
Después de aplicar la regla y ejecutar la consulta, este es el resultado que obtenemos:
Beneficios y Desafíos
El enmascaramiento dinámico de datos en PostgreSQL proporciona varios beneficios. Mejora la protección de datos al prevenir el acceso no autorizado a información sensible. Esto ayuda a reducir el riesgo de violaciones de datos y amenazas internas. También ayuda en el cumplimiento de estrictas regulaciones de protección de datos al limitar el acceso a datos sensibles.
Para el desarrollo y las pruebas, el enmascaramiento dinámico de datos permite a los equipos trabajar con conjuntos de datos realistas sin exponer información sensible. Los usuarios pueden crear reglas de enmascaramiento de datos personalizadas basadas en los roles de usuario, tipos de datos y necesidades específicas. Esto brinda a los administradores flexibilidad en la protección de datos.
Sin embargo, implementar el enmascaramiento dinámico de datos presenta desafíos. Puede impactar el rendimiento de las consultas, especialmente para reglas de enmascaramiento complejas o conjuntos de datos grandes. Mantener la integridad de los datos es crucial, requiriendo una planificación y prueba cuidadosas de las reglas de enmascaramiento. La educación del usuario también es importante, ya que los usuarios deben entender cómo funciona el enmascaramiento dinámico de datos y por qué es necesario.
Mejores Prácticas
Para implementar efectivamente el enmascaramiento dinámico de datos en PostgreSQL, considera estas mejores prácticas:
- Identificar los elementos de datos sensibles que requieren protección.
- Utilizar el control de acceso basado en roles (RBAC) para gestionar los permisos de los usuarios de manera efectiva.
- Revisar y actualizar regularmente las reglas de enmascaramiento para garantizar que sigan siendo efectivas y relevantes.
- Implementar mecanismos de registro y auditoría para rastrear quién accede a los datos enmascarados y cuándo.
- Probar a fondo las reglas y políticas de enmascaramiento antes de implementarlas en producción.
- Considerar usar cifrado para información extremadamente sensible además del enmascaramiento dinámico de datos.
Siguiendo estas prácticas, las organizaciones pueden crear una estrategia robusta de protección de datos que equilibre la seguridad con la usabilidad.
Conclusión
El enmascaramiento dinámico de datos en PostgreSQL es una herramienta poderosa para proteger la información sensible. Permite a las organizaciones equilibrar la seguridad de los datos con la usabilidad, asegurando que los usuarios tengan acceso a la información que necesitan mientras se salvaguardan los datos confidenciales. Los usuarios de PostgreSQL pueden crear un plan de protección de datos fuerte combinando el enmascaramiento dinámico de datos con otras medidas de seguridad. Este plan sigue las reglas y reduce el riesgo de fugas de datos.
A medida que la protección de datos se vuelve cada vez más importante, el enmascaramiento dinámico de datos seguirá desempeñando un papel crucial para los usuarios de PostgreSQL. Las organizaciones que utilizan PostgreSQL deben incluir esta característica en su plan de seguridad. Esto ayudará a proteger los datos sensibles y a garantizar el cumplimiento de las leyes de protección de datos.
