
Mascaramiento Estático de Datos en Greenplum: Mejorando la Seguridad y Cumplimiento de los Datos

Greenplum, un potente almacén de datos de código abierto, ofrece robustas características para gestionar y analizar grandes conjuntos de datos. A medida que las organizaciones manejan cantidades crecientes de información sensible, la necesidad de métodos efectivos de protección de datos se ha vuelto primordial. El mascaramiento estático de datos protege la información sensible en Greenplum, permitiendo a los usuarios utilizarla para diferentes necesidades. Este artículo explora el concepto de mascaramiento estático de datos en Greenplum, sus beneficios, desafíos y mejores prácticas para su implementación.
Mascaramiento Estático de Datos: Definición y Beneficios
El mascaramiento estático de datos es un proceso que sustituye los datos sensibles con información realista pero ficticia. Este método ayuda a las organizaciones a mantener sus datos importantes seguros, permitiéndoles usar los datos enmascarados para pruebas, desarrollo o análisis.
En Greenplum, el mascaramiento estático de datos agrega una capa adicional de seguridad, manteniendo la información sensible privada, incluso cuando se comparte con usuarios no autorizados o se traslada a entornos no productivos.
El objetivo principal del mascaramiento estático de datos es crear una versión de los datos que se vea y actúe como los datos originales, pero sin incluir ninguna información sensible.
Este método permite a las organizaciones utilizar datos ocultos para diferentes propósitos, manteniendo los datos originales seguros y privados.
Implementar el mascaramiento estático de datos en Greenplum ofrece varias ventajas significativas:
Mejora de la Seguridad de los Datos: Al reemplazar la información sensible con datos ficticios, las organizaciones pueden reducir significativamente el riesgo de brechas de datos. Incluso si los usuarios no autorizados acceden a los datos enmascarados, no podrán extraer información valiosa o sensible.
Cumplimiento Normativo: Muchas industrias están sujetas a estrictas regulaciones de protección de datos como el GDPR, HIPAA o PCI DSS. El mascaramiento estático de datos ayuda a las organizaciones a cumplir con estas regulaciones, asegurando que los datos sensibles no aparezcan en entornos no productivos.
Mejora de Pruebas y Desarrollo: El mascaramiento estático de datos permite a las organizaciones utilizar datos similares a los de producción en entornos de prueba y desarrollo. Este enfoque proporciona resultados de prueba más precisos y confiables, permitiendo a desarrolladores y evaluadores utilizar datos que reflejen situaciones del mundo real sin arriesgar información sensible.
Reducción de Costos: Usar datos enmascarados en lugar de conjuntos de datos sintéticos ayuda a las organizaciones, especialmente al preparar datos para propósitos no productivos. Esta eficiencia puede generar ahorros significativos a largo plazo.
Compartir Datos: El mascaramiento estático de datos permite a las organizaciones compartir datos con proveedores externos, socios o equipos de desarrollo offshore sin exponer información sensible. Esta capacidad facilita la colaboración mientras se mantiene la seguridad de los datos.
Desafíos y Técnicas
Aunque el mascaramiento estático de datos ofrece numerosos beneficios, también presenta algunos desafíos que las organizaciones deben abordar:
Mantener la Consistencia de los Datos: Uno de los mayores desafíos es asegurar que los datos enmascarados se mantengan consistentes en tablas relacionadas. Para mantener la integridad referencial de la base de datos, debemos preservar las relaciones entre diferentes elementos de datos.
Preservar la Utilidad de los Datos: Los datos enmascarados deben mantener los mismos patrones y características que los datos originales, lo cual es importante para análisis y pruebas. Lograr el equilibrio correcto entre la protección de datos y la utilidad de los datos puede ser desafiante.
Impacto en el Rendimiento: El proceso de enmascaramiento puede consumir mucho tiempo y recursos, dependiendo de las técnicas empleadas y la cantidad de datos. Las organizaciones deben considerar el impacto en el rendimiento en su entorno Greenplum.
Identificación de Datos Sensibles: Identificar exhaustivamente todos los elementos de datos sensibles dentro de una estructura compleja de base de datos puede ser una tarea ardua. Omitir incluso un solo campo sensible puede comprometer todo el esfuerzo de enmascaramiento.
Greenplum proporciona varios métodos para implementar el mascaramiento estático de datos, incluyendo funciones integradas, herramientas de terceros y scripts personalizados. Algunas de las técnicas comunes utilizadas en el mascaramiento estático de datos en Greenplum incluyen:
Sustitución: Esta técnica implica reemplazar los datos sensibles con valores realistas pero falsos.
Desorden: Este método implica aleatorizar los valores dentro de una columna, manteniendo las propiedades estadísticas generales de los datos mientras se oscurecen los registros individuales.
Encriptación: Se pueden transformar los datos sensibles usando algoritmos de encriptación. Aunque este método proporciona una fuerte protección, puede limitar la usabilidad de los datos para ciertos propósitos.
Mejores Prácticas e Implementación
Para maximizar la efectividad del mascaramiento estático de datos en Greenplum, considere las siguientes mejores prácticas:
Identificar Datos Sensibles: Analice exhaustivamente su base de datos Greenplum para identificar todos los elementos de datos sensibles. Este paso asegura que el proceso de enmascaramiento no pase por alto ninguna información confidencial.
Elegir Técnicas Adecuadas de Mascaramiento: Seleccione técnicas de enmascaramiento que se adapten mejor a sus tipos de datos y requisitos de seguridad. Diferentes elementos de datos pueden requerir diferentes enfoques de enmascaramiento para mantener la integridad de los datos y la usabilidad.
Mantener las Relaciones de los Datos: Cuando enmascare datos en varias tablas, asegúrese de preservar las relaciones entre las tablas. Este paso es crucial para mantener la consistencia de los datos y evitar problemas en las aplicaciones que dependen de estas relaciones.
Documentar Reglas de Mascaramiento: Mantenga una documentación clara de todas las reglas y procedimientos de enmascaramiento. Esta documentación debe incluir los campos enmascarados, las técnicas utilizadas y cualquier excepción o caso especial.
Crear una Tabla Separada con Datos Enmascarados
A continuación, se muestra un ejemplo de cómo crear una tabla separada llena de datos enmascarados en Greenplum:
-- Tabla original
CREATE TABLE customer_data (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
credit_card VARCHAR(16),
date_of_birth DATE
);
-- Insertar datos de muestra
INSERT INTO customer_data (name, email, credit_card, date_of_birth)
VALUES ('John Doe', 'john@example.com', '1234567890123456', '1980-05-15');
-- Crear tabla enmascarada
CREATE TABLE masked_customer_data AS
SELECT
id,
'Customer_' || id AS masked_name,
'user_' || id || '@masked.com' AS masked_email,
SUBSTRING(credit_card, 1, 4) || 'XXXXXXXXXXXX' AS masked_credit_card,
date_of_birth + (RANDOM() * 365 * INTERVAL '1 day') AS masked_date_of_birth
FROM customer_data;
-- Ver datos enmascarados
SELECT * FROM masked_customer_data;
Este ejemplo crea una nueva tabla llamada `masked_customer_data` con versiones enmascaradas de campos sensibles. Cambiamos el `name` a “Customer_” seguido por la ID.
El sistema oculta el `email` en un formato enmascarado. La `credit_card` muestra solo los primeros cuatro dígitos, reemplazando el resto con caracteres ‘X’.
La `date_of_birth` se desplaza un número aleatorio de días que puede ser de hasta un año. Esto mantiene la distribución general por edad mientras oculta las fechas de nacimiento exactas.
Implementación a través de DataSunrise
Greenplum permite a los usuarios enmascarar datos estáticos. Sin embargo, esto puede ser complicado y lento para grandes bases de datos. En tales circunstancias, sugerimos usar soluciones de terceros. Para comenzar esto en DataSunrise, debe crear una instancia de una base de datos Greenplum.
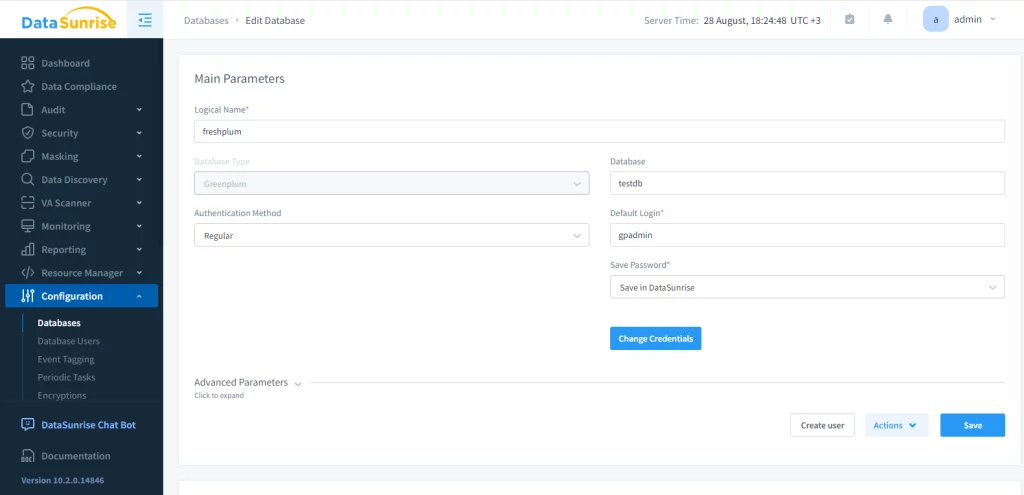
La instancia permite interactuar con la base de datos fuente a través de auditoría, reglas y tareas de mascaramiento y seguridad. A continuación, debemos configurar una tarea de enmascaramiento estático. Este paso tiene tres acciones: elegir el servidor de origen, seleccionar las bases de datos fuente y destino (ambas deben ser Greenplum) y establecer las reglas de enmascaramiento. Por razones de integridad, recomendamos truncar el esquema de destino.
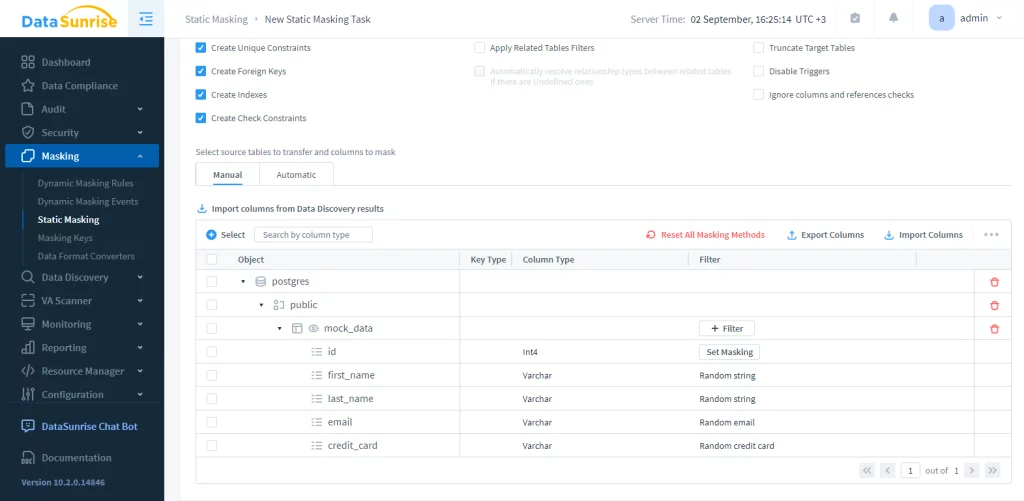
En este ejemplo, la tabla enmascarada es mock_data en la base de datos postgres. Solo necesita iniciar la tarea. El resultado es el siguiente:

Conclusión
El mascaramiento estático de datos en Greenplum es una técnica poderosa para mejorar la seguridad y el cumplimiento de los datos. Las organizaciones pueden proteger la información sensible utilizando métodos efectivos mientras mantienen los datos utilizables para pruebas, desarrollo y análisis.
Las preocupaciones por la privacidad de los datos están aumentando y las regulaciones se están endureciendo. El mascaramiento estático de datos es crucial para las empresas que utilizan Greenplum para mantener su información segura. Las organizaciones pueden utilizar los conocimientos de este artículo para crear estrategias efectivas de mascaramiento estático de datos, ayudando a proteger la información sensible al mismo tiempo que permiten su uso efectivo.
Siguiente
