
Enmascaramiento de Datos Estáticos en PostgreSQL

La protección de datos es crucial para las empresas que manejan información sensible. PostgreSQL, un poderoso sistema de bases de datos de código abierto, ofrece varias características de seguridad. Una de estas características es el enmascaramiento de datos estático. Este artículo explora el enmascaramiento de datos estático en PostgreSQL, sus beneficios y cómo implementarlo eficazmente.
¿Qué es el Enmascaramiento de Datos Estático?
El enmascaramiento de datos estático es una técnica que reemplaza los datos sensibles con información realista pero falsa. Este proceso ocurre antes de que los datos se transfieran a entornos de no producción. Ayuda a proteger la información confidencial mientras permite a los desarrolladores y probadores trabajar con representaciones precisas de los datos.
El enmascaramiento de datos estático en PostgreSQL implica varios pasos. Primero, identificas los datos sensibles.
Luego, eliges técnicas de enmascaramiento adecuadas. A continuación, creas copias enmascaradas de los datos originales. Finalmente, reemplazas los datos originales con los datos enmascarados en entornos de no producción.
Técnicas Comunes de Enmascaramiento de Datos Estático
PostgreSQL ofrece varias técnicas de enmascaramiento. La sustitución reemplaza los datos sensibles con valores falsos pero realistas. Por ejemplo, reemplazar nombres reales con nombres generados aleatoriamente.
El reordenamiento reorganiza los datos dentro de una columna. Mantiene la distribución de datos pero rompe la conexión entre los registros. La alteración numérica modifica los valores numéricos preservando sus propiedades estadísticas. El cambio de fechas mueve las fechas hacia adelante o hacia atrás por un período fijo.
Implementación del Enmascaramiento de Datos Estático en PostgreSQL
Para implementar el enmascaramiento de datos estático en PostgreSQL, comienza identificando los datos sensibles. Revisa el esquema de tu base de datos e identifica las columnas que contienen información sensible.
A continuación, crea reglas de enmascaramiento. Desarrolla reglas para cada tipo de datos sensibles. Asegúrate de que los datos enmascarados sigan siendo útiles para pruebas y desarrollo.
Escribe consultas de enmascaramiento para aplicar tus reglas. Aquí hay un ejemplo que crea una nueva tabla con datos enmascarados:
-- Crear una nueva tabla para los datos enmascarados
CREATE TABLE masked_customers AS
SELECT
id,
MD5(RANDOM()::TEXT) AS masked_name,
CONCAT(
SUBSTRING(MD5(RANDOM()::TEXT) FOR 8),
'@example.com'
) AS masked_email,
CASE
WHEN age < 18 THEN 'minor'
WHEN age BETWEEN 18 AND 65 THEN 'adult'
ELSE 'senior'
END AS masked_age_group,
ROUND(credit_score / 100) * 100 AS masked_credit_score
FROM customers;
-- Agrega los índices necesarios
CREATE INDEX ON masked_customers (id);
Este ejemplo crea una nueva tabla llamada `masked_customers` basada en la tabla original `customers`. Aplica diferentes técnicas de enmascaramiento:
- Los nombres son reemplazados por hashes MD5 aleatorios.
- El sistema enmascara los correos electrónicos con cadenas aleatorias y un dominio genérico.
- Las edades se categorizan en grupos.
- Las puntuaciones de crédito se redondean al centenar más cercano.
Prueba tus consultas de enmascaramiento en un conjunto de datos pequeño para asegurarte de que funcionan correctamente. Luego, crea una copia enmascarada de tu base de datos de producción y aplica las consultas de enmascaramiento a esta copia. Verifica que los datos enmascarados oculten adecuadamente la información sensible. Finalmente, usa esta tabla enmascarada para entornos de no producción.
Implementación a través de DataSunrise
Usando solo herramientas nativas, es posible realizar el enmascaramiento estático. Sin embargo, podría ser un desafío con una base de datos sustancial. Para simplificar el proceso, sugerimos usar soluciones de terceros como DataSunrise. El orden de implementación es el siguiente:
Primero, se debe crear una instancia de la base de datos PostgreSQL.
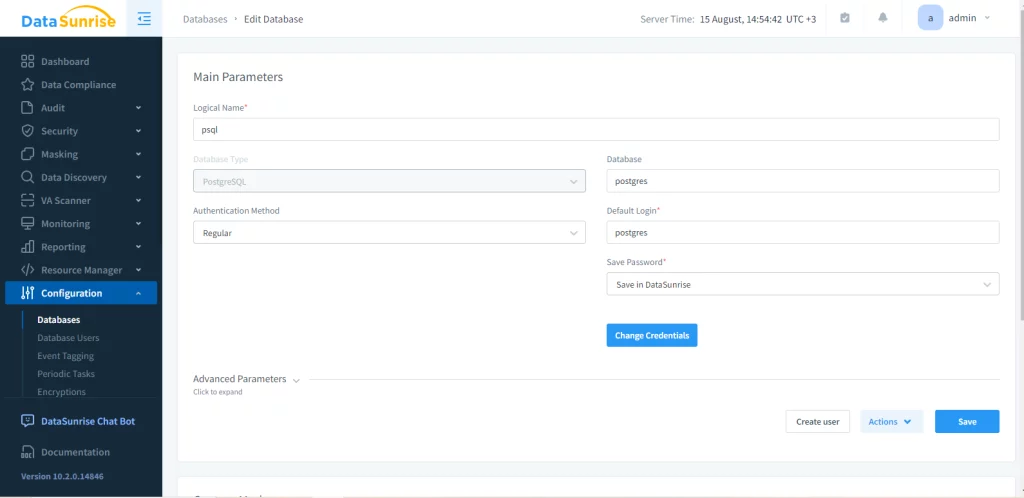
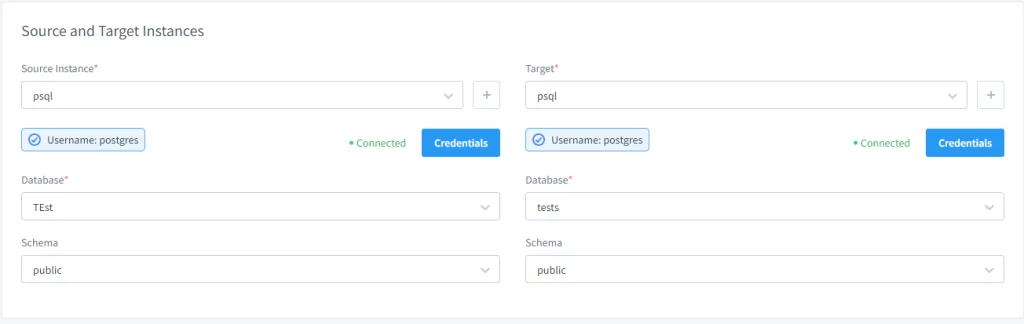
Luego, configura la tarea de enmascaramiento estático. Para hacer esto, debes seleccionar las bases de datos y esquemas de origen y destino. Por razones de integridad, recomendamos truncar el esquema de destino antes de transferir los datos, aunque es opcional.
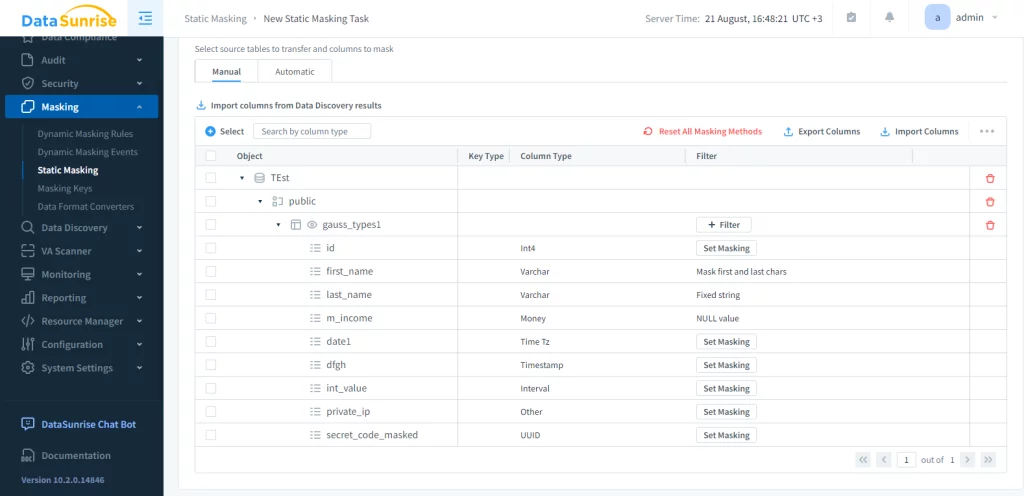
La siguiente parte de la configuración de la tarea es seleccionar métodos de enmascaramiento.
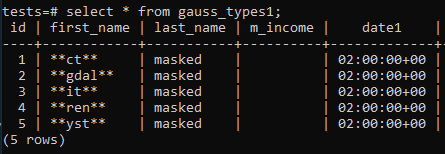
Simplemente inicia la tarea. Puedes programar o iniciar este proceso manualmente en cualquier momento. El resultado es el siguiente:
Mejores Prácticas y Desafíos
Sigue las mejores prácticas para maximizar la efectividad del enmascaramiento de datos estático. Asegura la consistencia entre tablas y preserva la integridad referencial. Actualiza tus datos enmascarados periódicamente y documenta tus reglas de enmascaramiento. Usa controles de acceso fuertes para limitar el acceso tanto a los datos originales como a los enmascarados.
El enmascaramiento de datos estático conlleva desafíos. Enmascarar grandes conjuntos de datos puede consumir mucho tiempo y recursos. Balancear la protección de datos con el mantenimiento de datos útiles para pruebas puede ser complicado. Enmascarar datos en bases de datos con relaciones complejas requiere una planificación cuidadosa.
Conclusión
Varios herramientas pueden ayudar con el enmascaramiento de datos estático en PostgreSQL. pgMemento es una extensión de PostgreSQL de código abierto para auditoría y enmascaramiento de datos. Dataedo es una herramienta de documentación de bases de datos y enmascaramiento de datos que soporta PostgreSQL. PostgreSQL Anonymizer es una extensión que proporciona capacidades de enmascaramiento de datos dinámico.
El enmascaramiento de datos estático en PostgreSQL es una técnica poderosa para proteger información sensible. Las organizaciones pueden proteger la privacidad de los datos, seguir las normativas y mantener la precisión de los datos para propósitos de no producción haciéndolo correctamente. A medida que la protección de datos se vuelve cada vez más importante, dominar el enmascaramiento de datos estático en PostgreSQL es una habilidad valiosa tanto para administradores de bases de datos como para desarrolladores.
