
Enmascaramiento Estático de Datos para Amazon Aurora

Introducción
A medida que las empresas dependen cada vez más de bases de datos en la nube como Amazon Aurora, la necesidad de medidas robustas de seguridad de datos crece. Una técnica crucial en este ámbito es el enmascaramiento estático de datos. Este proceso ayuda a las organizaciones a proteger los datos confidenciales mientras permite entornos de prueba realistas. ¿Sabía que según un estudio reciente de Verizon, el 64% de todos los datos comprometidos son información personal? Esta impactante estadística subraya la importancia de implementar medidas fuertes de protección de datos, incluido el enmascaramiento estático de datos.
¿Qué es el Enmascaramiento Estático de Datos?
El enmascaramiento estático de datos es una técnica de seguridad de datos que crea una réplica de una base de datos de producción con información sensible reemplazada por datos realistas pero ficticios. Este enfoque permite a las organizaciones usar datos enmascarados para pruebas, desarrollo y análisis sin exponer información confidencial real.
Los beneficios clave del enmascaramiento estático de datos incluyen:
- Mayor seguridad de los datos
- Cumplimiento con las regulaciones de protección de datos
- Reducción del riesgo de violaciones de datos
- Mejora en la precisión de las pruebas
Capacidades de Amazon Aurora para el Enmascaramiento de Datos
Datos de Prueba
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50), phone VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email, phone) values (1, 'Alica', 'Collyer', '[email protected]', '676-612-4979'); … insert into MOCK_DATA (id, first_name, last_name, email, phone) values (10, 'Nevsa', 'Justun', '[email protected]', '997-928-5900');
Amazon Aurora en sí no tiene reglas de transformación o enmascaramiento integradas. En su lugar, deberá implementar lógica de enmascaramiento utilizando consultas SQL o funciones. Aquí hay algunos enfoques prácticos (tanto enmascaramiento dinámico como estático):
Consultas SQL
Utilice SQL para crear versiones enmascaradas de sus datos. Por ejemplo:
SELECT
id,
CONCAT(LEFT(first_name, 1), REPEAT('*', LENGTH(first_name) - 1)) AS masked_name,
CONCAT('****-****-****-', RIGHT(phone, 4)) AS masked_phone
FROM mock_data;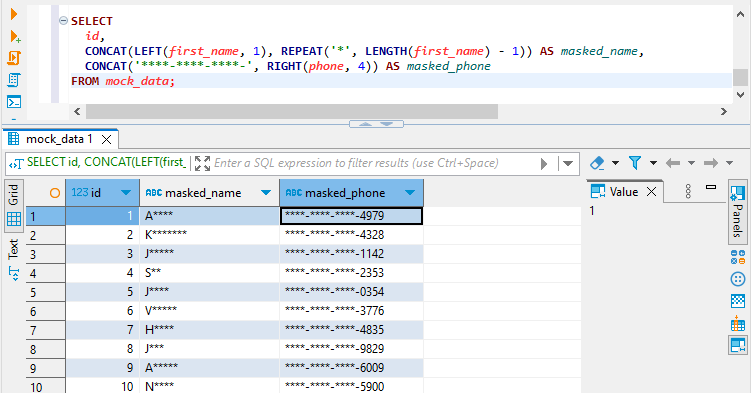
Funciones Definidas por el Usuario
Crear funciones personalizadas para enmascaramiento más complejo o insertarlas en la tabla estática:
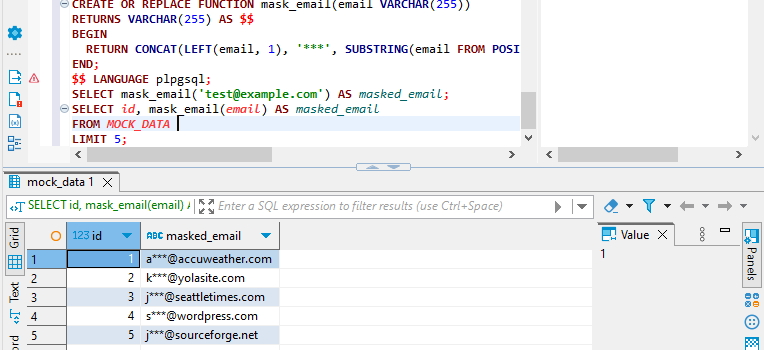
CREATE OR REPLACE FUNCTION mask_email(email VARCHAR(255))
RETURNS VARCHAR(255) AS $$
BEGIN
RETURN CONCAT(LEFT(email, 1), '***', SUBSTRING(email FROM POSITION('@' IN email)));
END;
$$ LANGUAGE plpgsql;
SELECT mask_email('[email protected]') AS masked_email;
SELECT id, mask_email(email) AS masked_email
FROM MOCK_DATA
LIMIT 5;Estos métodos le permiten implementar enmascaramiento dinámico de datos directamente dentro de Aurora sin depender de reglas de transformación externas. Son más sencillos y directamente aplicables a bases de datos Aurora.
Copiar Tabla
Para implementar enmascaramiento estático de datos en Aurora PostgreSQL, puede simplemente copiar los datos:
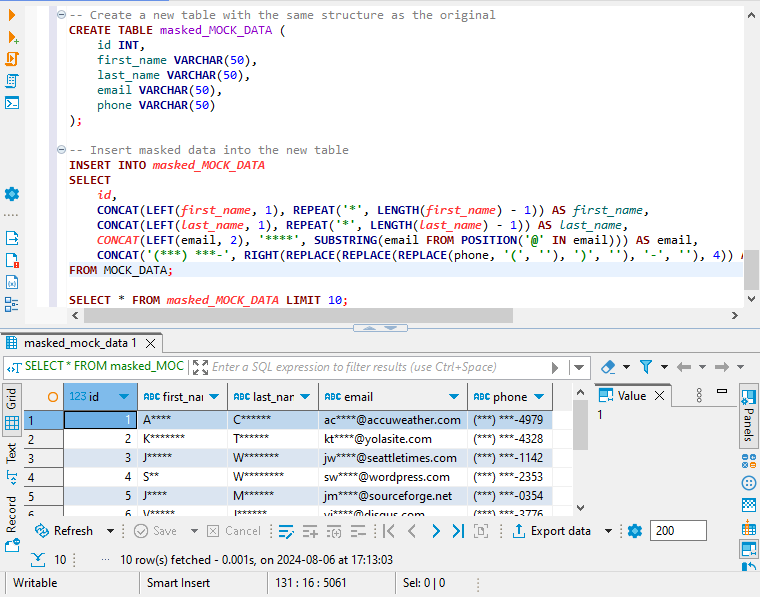
-- Crear una nueva tabla con la misma estructura que la original
CREATE TABLE masked_MOCK_DATA (
id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50),
phone VARCHAR(50)
);
-- Insertar datos enmascarados en la nueva tabla
INSERT INTO masked_MOCK_DATA
SELECT
id,
CONCAT(LEFT(first_name, 1), REPEAT('*', LENGTH(first_name) - 1)) AS first_name,
CONCAT(LEFT(last_name, 1), REPEAT('*', LENGTH(last_name) - 1)) AS last_name,
CONCAT(LEFT(email, 2), '****', SUBSTRING(email FROM POSITION('@' IN email))) AS email,
CONCAT('(***) ***-', RIGHT(REPLACE(REPLACE(REPLACE(phone, '(', ''), ')', ''), '-', ''), 4)) AS phone
FROM MOCK_DATA;Para ver una muestra de los datos recién enmascarados, ejecute la siguiente consulta:
SELECT * FROM masked_MOCK_DATA LIMIT 10;
Para un enmascaramiento más avanzado o automatizado, puede considerar el uso de herramientas de terceros como DataSunrise que se integran con Aurora y proporcionan capacidades adicionales de enmascaramiento.
Configuración de Tareas de Enmascaramiento Estático en DataSunrise
DataSunrise ofrece una interfaz fácil de usar para configurar tareas de enmascaramiento estático de datos para Amazon Aurora. Aquí está una guía paso a paso:
- Crear una instancia de Aurora en DataSunrise
- Navegar al módulo de Enmascaramiento de Datos
- Crear una nueva Tarea de Enmascaramiento Estático (SMTaskAurora en la figura siguiente)
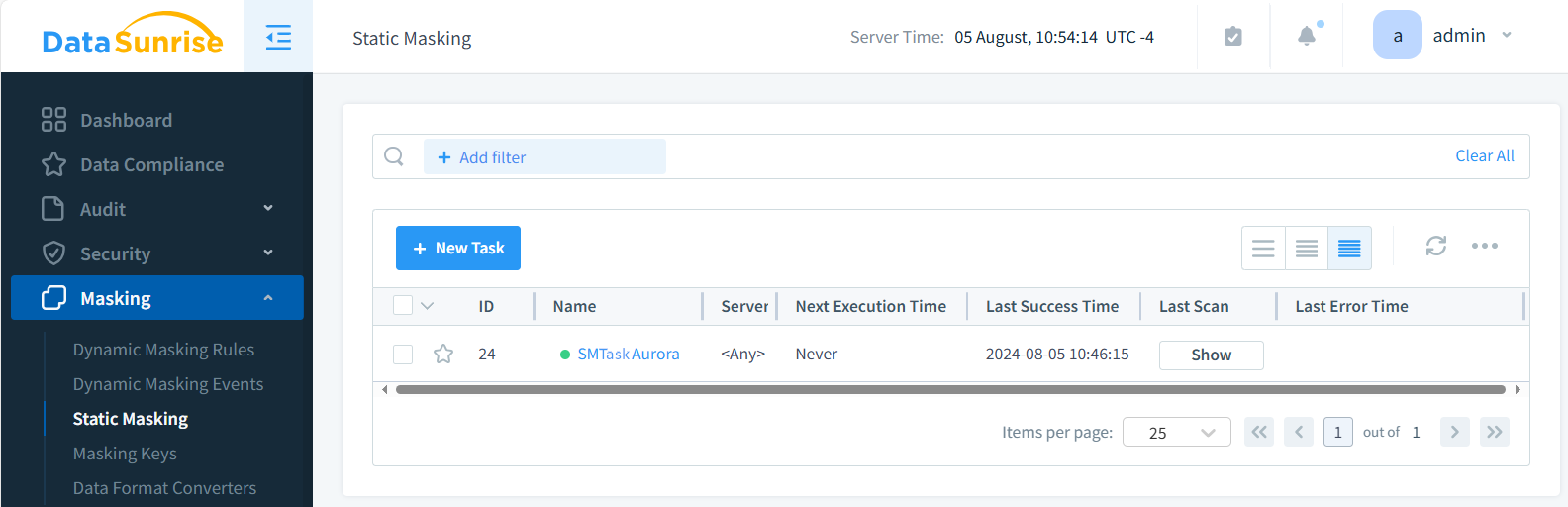
- Seleccionar las bases de datos fuente y destino
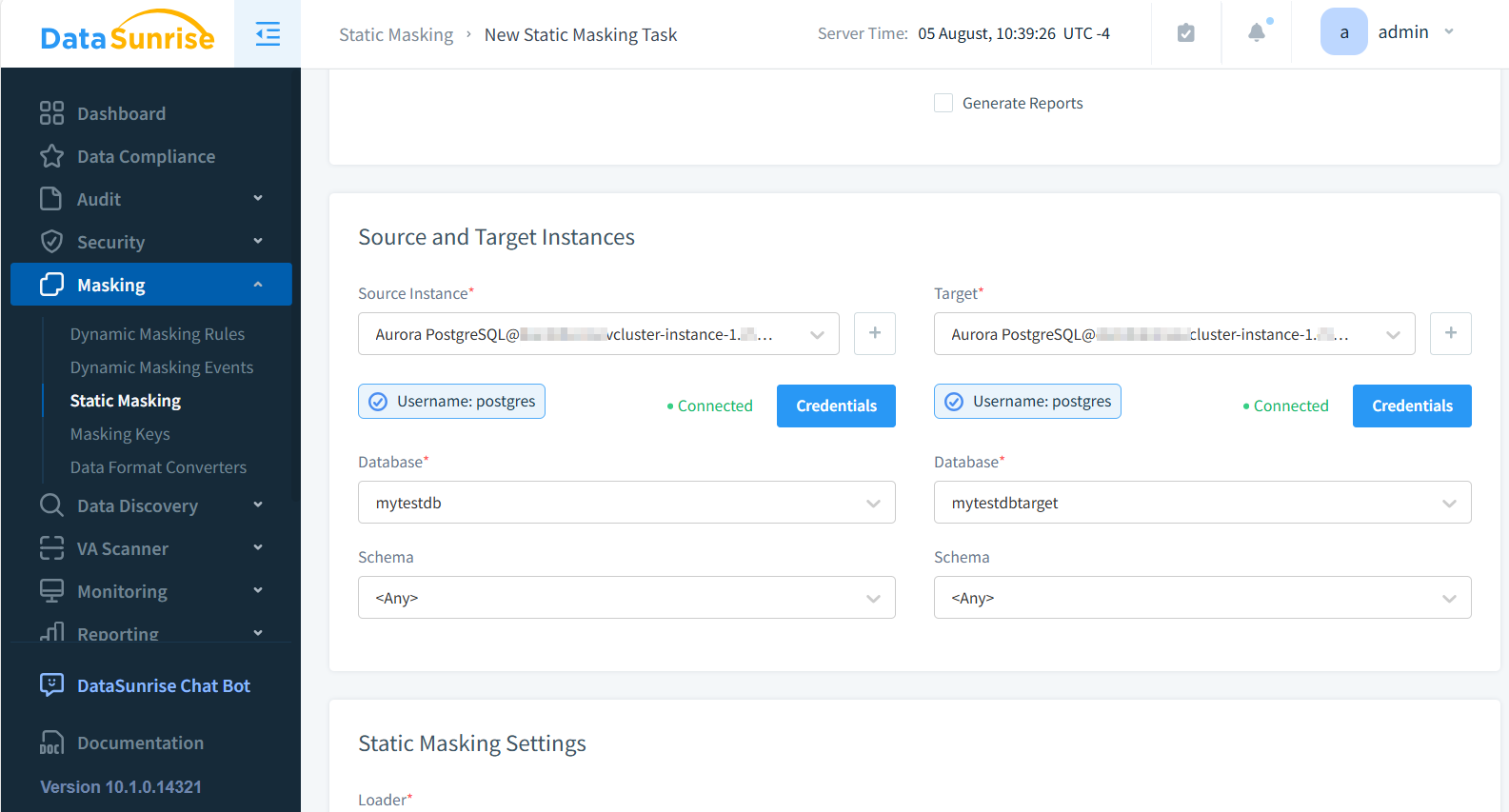
- Elegir las tablas (mock_data en el ejemplo a continuación) y columnas a enmascarar (apellido, correo electrónico, teléfono e ip_address)
- Aplicar el método de enmascaramiento (por ejemplo, sustitución, barajado, encriptado que preserva el formato)
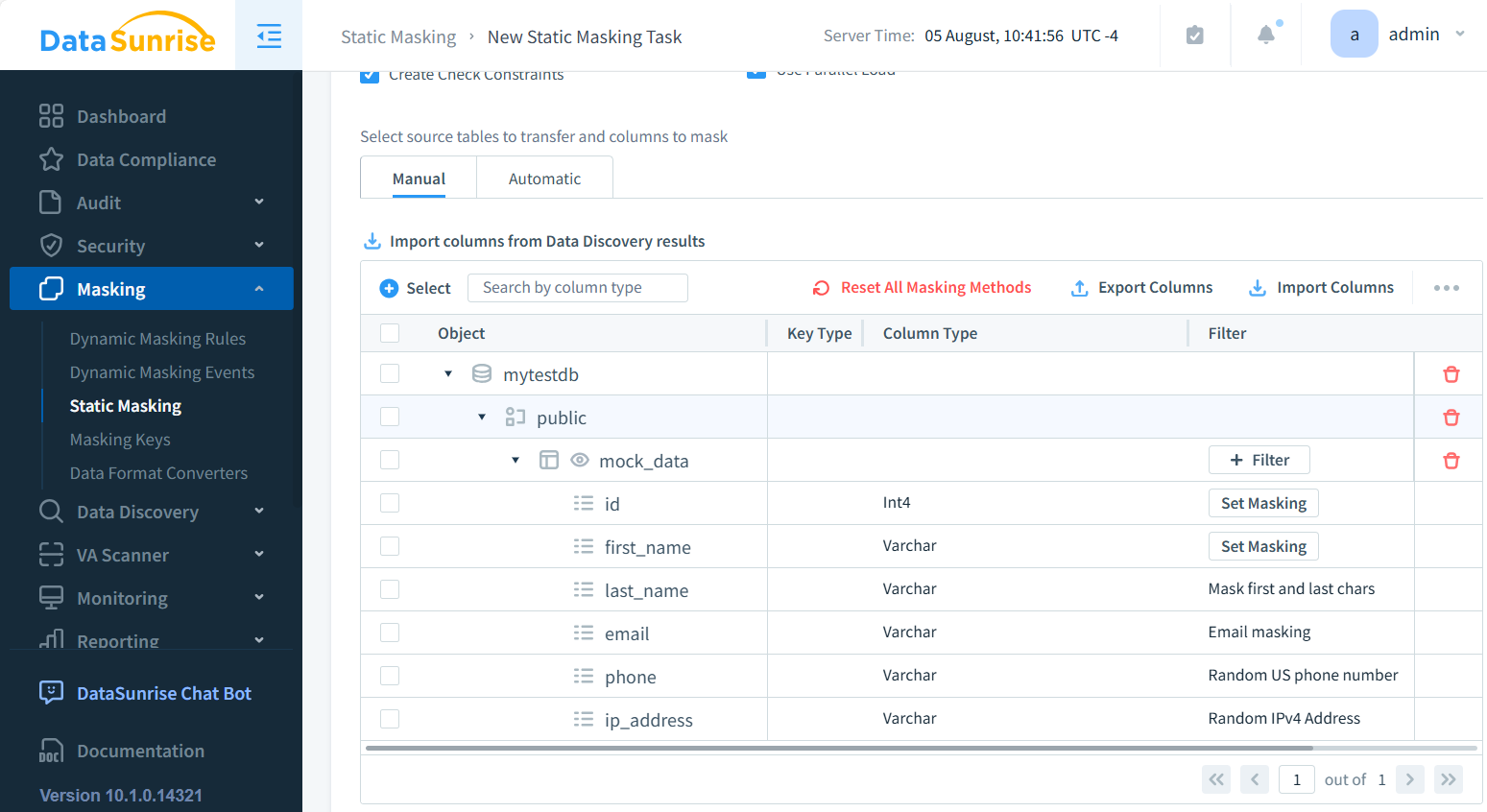
- Programar la ejecución de la tarea (Manual de forma predeterminada)
- Ejecutar la tarea y verificar los resultados
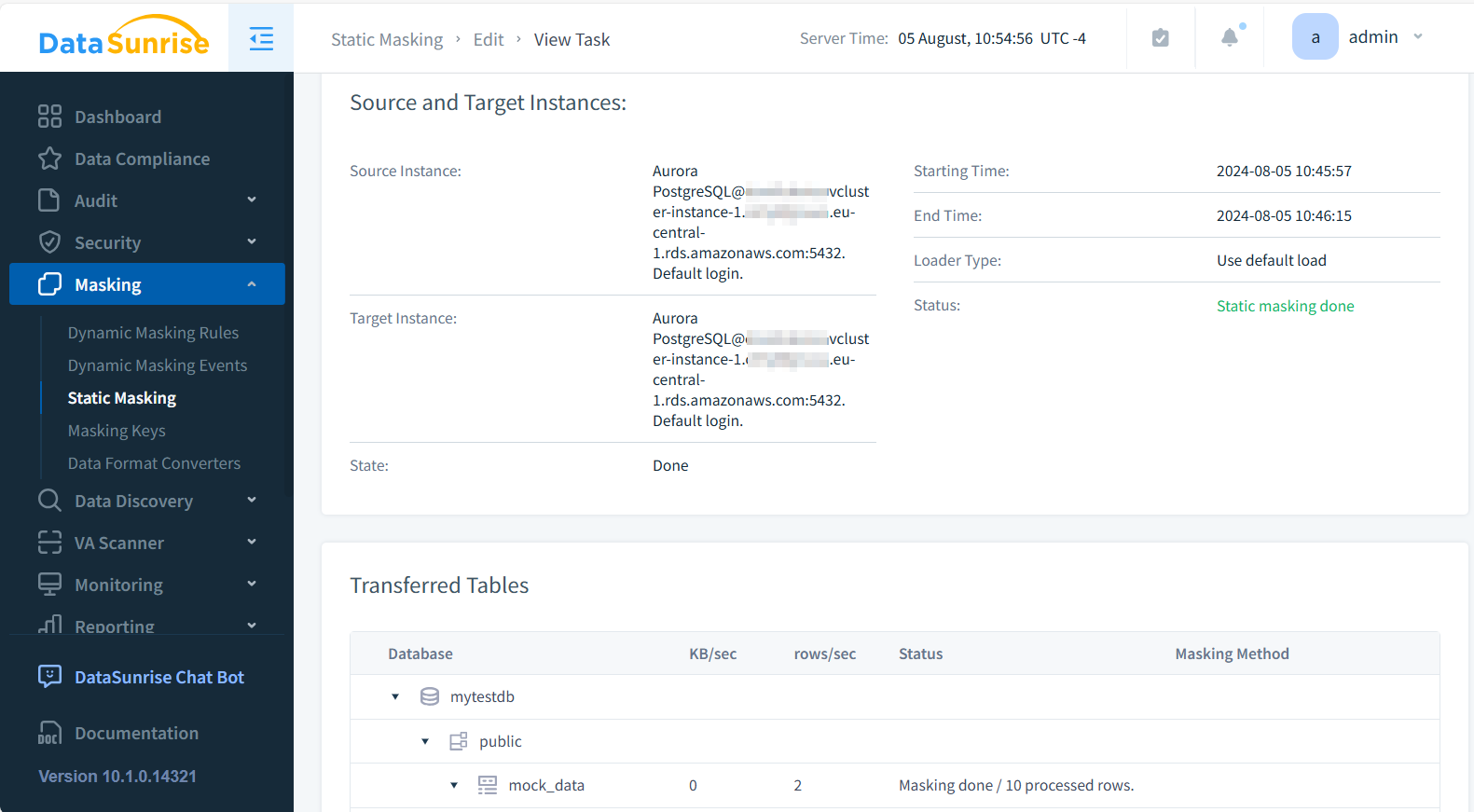
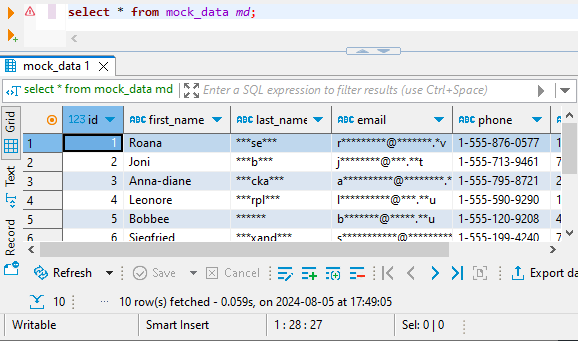
En DBeaver, ahora puede consultar los datos enmascarados de la base de datos de destino:
Seguimiento de Resultados de Ejecución
Después de configurar una tarea de enmascaramiento estático, es crucial monitorear su ejecución y verificar los resultados. DataSunrise proporciona características integrales de registro y generación de informes para este propósito:
- Verificar el estado de ejecución de la tarea en el panel de control de DataSunrise
- Revisar los registros detallados para cualquier error o advertencia
- Comparar muestras de datos de las bases de datos fuente y destino
- Generar informes sobre columnas enmascaradas y distribución de datos
Enfoques de Pruebas de Aplicaciones Basadas en Datos
En cuanto a las pruebas de aplicaciones basadas en datos, hay dos enfoques principales disponibles:
1. Pruebas con Datos Enmascarados
Este enfoque utiliza el enmascaramiento estático de datos para crear un entorno de prueba realista con datos de producción anonimizados. Es ideal para mantener relaciones y distribuciones de datos mientras se protege la información sensible.
2. Pruebas con Datos Sintéticos
Los datos sintéticos son generados artificialmente para imitar las características de los datos reales. Este enfoque ofrece más flexibilidad pero puede no representar completamente todos los casos extremos presentes en los datos de producción.
Ambos métodos tienen sus méritos, y la elección depende de los requisitos específicos de prueba y los niveles de sensibilidad de los datos.
Mejores Prácticas para el Enmascaramiento Estático de Datos en Amazon Aurora
Para maximizar la efectividad del enmascaramiento estático de datos para Amazon Aurora, considere estas mejores prácticas:
- Identificar todos los elementos de datos sensibles en su base de datos
- Elegir técnicas de enmascaramiento apropiadas para cada tipo de dato
- Mantener la consistencia de datos a través de tablas relacionadas
- Actualizar regularmente las reglas de enmascaramiento para abordar nuevos tipos de datos o regulaciones
- Combinar enmascaramiento estático con enmascaramiento dinámico para una protección completa
- Implementar controles de acceso estrictos para bases de datos enmascaradas
Conclusión
El enmascaramiento estático de datos para Amazon Aurora es una técnica crucial para proteger los datos sensibles mientras se habilitan procesos efectivos de prueba y desarrollo. Al aprovechar herramientas como DataSunrise, las organizaciones pueden implementar estrategias robustas de enmascaramiento que equilibren la utilidad de los datos con los requisitos de seguridad y cumplimiento.
A medida que las violaciones de datos continúan representando riesgos significativos, implementar medidas fuertes de protección de datos, incluido el enmascaramiento estático de datos, ya no es opcional: es una necesidad para la gestión responsable de los datos.
DataSunrise ofrece herramientas de vanguardia para la seguridad de bases de datos, incluyendo auditoría, descubrimiento de datos y capacidades avanzadas de enmascaramiento. Nuestra interfaz fácil de usar facilita la implementación de estrategias completas de protección de datos para Amazon Aurora y otras plataformas de bases de datos. Visite nuestro sitio web para una demostración en línea y para explorar cómo podemos ayudar a asegurar sus valiosos activos de datos.
