
Cómo Implementar Enmascaramiento de Datos Estáticos en Amazon DynamoDB
Introducción
En 2022, las soluciones basadas en la nube representaron el 53% del mercado global de software DLP (Prevención de Pérdida de Datos), con un crecimiento general del mercado mostrando una expansión no lineal. Amazon DynamoDB, un popular servicio de base de datos NoSQL, almacena grandes cantidades de datos, incluida información potencialmente sensible. El enmascaramiento de datos estáticos ofrece una solución poderosa para proteger estos datos. Exploremos cómo se puede implementar el enmascaramiento de datos estáticos para Amazon DynamoDB, enfocándonos en técnicas y herramientas prácticas.
Los principales proveedores de DLP están priorizando el desarrollo de soluciones nativas en la nube y compatibles con la nube para abordar la creciente demanda. En DataSunrise, estamos sintonizados con estas tendencias de la industria y ofrecemos soluciones de vanguardia diseñadas para proteger las infraestructuras de datos basadas en la nube de manera efectiva.
Entendiendo el Enmascaramiento de Datos Estáticos
El enmascaramiento de datos estáticos es una técnica de seguridad que reemplaza datos sensibles con información realista pero ficticia. A diferencia del enmascaramiento dinámico, que ocurre en tiempo real, el enmascaramiento estático altera permanentemente los datos en reposo. Este enfoque es ideal para crear entornos seguros y no de producción para pruebas y desarrollo.
Beneficios del Enmascaramiento de Datos Estáticos
- Mejora de la seguridad de los datos
- Cumplimiento con las normativas de protección de datos
- Reducción del riesgo de violaciones de datos
- Entorno seguro para desarrollo y pruebas
Capacidades Nativas de Enmascaramiento en Amazon DynamoDB
Amazon DynamoDB ofrece capacidades nativas de enmascaramiento, las cuales hemos cubierto en nuestros artículos anteriores sobre enmascaramiento y enmascaramiento dinámico para DynamoDB. Estas funciones permiten el post-procesamiento de los resultados de consultas después de recuperar los datos usando la API de Python o CLI.
Implementando Enmascaramiento de Datos Estáticos con Python y Boto3
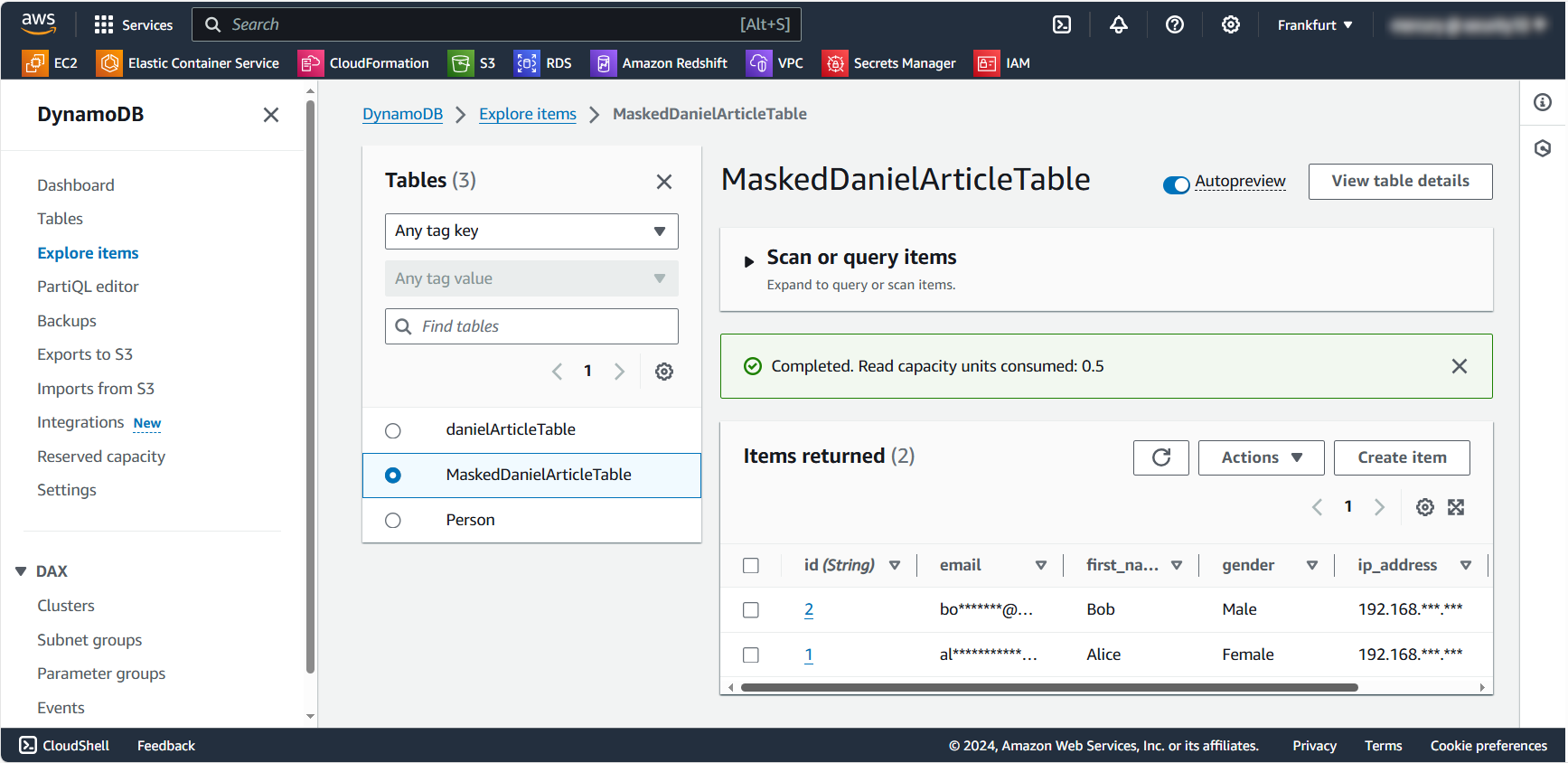
Exploremos un ejemplo práctico de enmascaramiento de datos estáticos utilizando Python y la biblioteca Boto3. Nos conectaremos a la base de datos, crearemos una copia de los datos (tabla MaskedDanielArticleTable) y enmascararemos información sensible como direcciones de correo electrónico y IP.
import boto3
from boto3.dynamodb.conditions import Key
import time
# Conectar a DynamoDB
dynamodb = boto3.resource('dynamodb')
source_table = dynamodb.Table('danielArticleTable')
# Crear la tabla enmascarada
try:
masked_table = dynamodb.create_table(
TableName='MaskedDanielArticleTable',
KeySchema=[
{'AttributeName': 'id', 'KeyType': 'HASH'},
],
AttributeDefinitions=[
{'AttributeName': 'id', 'AttributeType': 'S'},
],
ProvisionedThroughput={
'ReadCapacityUnits': 5,
'WriteCapacityUnits': 5
}
)
print("Creando tabla enmascarada...")
masked_table.meta.client.get_waiter('table_exists').wait(TableName='MaskedDanielArticleTable')
print("Tabla enmascarada creada exitosamente")
except dynamodb.meta.client.exceptions.ResourceInUseException:
print("La tabla enmascarada ya existe")
masked_table = dynamodb.Table('MaskedDanielArticleTable')
# Función para enmascarar correo electrónico
def mask_email(email):
username, domain = email.split('@')
masked_username = username[:2] + '*' * (len(username) - 2)
return f"{masked_username}@{domain}"
# Función para enmascarar dirección IP
def mask_ip(ip):
octets = ip.split('.')
masked_octets = octets[:2] + ['***', '***']
return '.'.join(masked_octets)
# Escanear la tabla fuente
response = source_table.scan()
items = response['Items']
# Enmascarar y copiar datos
for item in items:
masked_item = item.copy()
if 'email' in masked_item:
masked_item['email'] = mask_email(masked_item['email'])
if 'ip_address' in masked_item:
masked_item['ip_address'] = mask_ip(masked_item['ip_address'])
# Colocar el ítem enmascarado en la nueva tabla
masked_table.put_item(Item=masked_item)
print("Enmascaramiento de datos estáticos completado.")El resultado (ejecutado en Jupyter Notebook) es el siguiente:
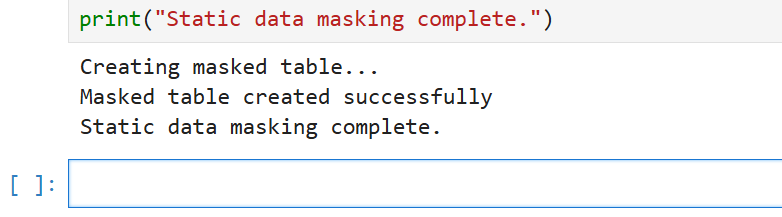
Este script demuestra un enfoque básico para el enmascaramiento de datos estáticos. Crea una nueva tabla con datos enmascarados, asegurando que la información sensible original permanezca protegida.
Antes de continuar, es importante abordar algunos puntos clave con respecto al código proporcionado. La naturaleza de esquema flexible de DynamoDB presenta desafíos únicos para el enmascaramiento de datos estáticos automatizado. Examinemos estas complejidades:
- Diferentes ítems en la misma tabla pueden tener diferentes atributos.
- Se pueden agregar nuevos atributos a los ítems en cualquier momento sin necesidad de modificar la estructura de la tabla.
Para abordar estos desafíos:
- Implemente reglas de enmascaramiento flexibles que puedan adaptarse a estructuras de datos variables.
- Utilice técnicas de coincidencia de patrones o aprendizaje automático para identificar datos potencialmente sensibles.
- Mantenga un catálogo completo de patrones y ubicaciones de datos sensibles.
- Emplee técnicas de muestreo para manejar grandes conjuntos de datos de manera eficiente.
Enmascaramiento de Datos Estáticos con DataSunrise
La versión actual de DataSunrise (10.0) ofrece enmascaramiento dinámico con todas las funciones para DynamoDB, pero no es compatible con el enmascaramiento estático para esta base de datos. Para obtener una visión general completa de las bases de datos compatibles y las características, consulte el capítulo 1.2, ‘Bases de Datos y Funcionalidades Soportadas,’ en nuestra documentación. Como resultado, las instancias de DynamoDB no están disponibles para selección en las listas de bases de datos de origen y de destino al configurar una tarea de enmascaramiento estático.
Mejores Prácticas para el Enmascaramiento de Datos Estáticos en DynamoDB
Para maximizar la efectividad de sus esfuerzos de enmascaramiento de datos estáticos:
- Identifique todos los datos sensibles y sus atributos
- Utilice técnicas de enmascaramiento realistas para mantener la usabilidad de los datos
- Actualice regularmente las reglas de enmascaramiento para abordar nuevos tipos de datos
- Implemente controles de acceso para los datos enmascarados
- Audite los procesos de enmascaramiento para asegurar su efectividad
Desafíos y Consideraciones
Si bien el enmascaramiento de datos estáticos ofrece beneficios significativos, es importante considerar los posibles desafíos:
- Impacto en el rendimiento durante el proceso de enmascaramiento
- Mantener la integridad referencial en los conjuntos de datos enmascarados
- Asegurarse de que los datos enmascarados sean útiles para pruebas y desarrollo
- Actualizar las reglas y tareas de enmascaramiento con estructuras de datos cambiantes
Conclusión
El enmascaramiento de datos estáticos para Amazon DynamoDB proporciona una herramienta poderosa para proteger la información sensible. Al implementar técnicas de enmascaramiento robustas, las organizaciones pueden reducir significativamente el riesgo de violaciones de datos y asegurar el cumplimiento con las normativas de protección de datos.
Ya sea utilizando las funciones nativas de DynamoDB, scripts personalizados en Python, o herramientas especializadas, el enmascaramiento de datos estáticos ofrece un enfoque flexible y efectivo para proteger sus valiosos activos de datos.
DataSunrise ofrece una suite completa de herramientas de seguridad de bases de datos, incluidas características avanzadas de auditoría y cumplimiento. Nuestras soluciones de vanguardia proporcionan opciones flexibles y poderosas para proteger sus datos sensibles en varias plataformas de bases de datos. Visite nuestro sitio web para programar una demostración en línea y explorar cómo DataSunrise puede mejorar su estrategia de seguridad de datos.
Siguiente
