
Esquema de Información de la Base de Datos Redshift

Introducción
Este artículo profundiza en el esquema de la base de datos Redshift, centrándose específicamente en su implementación del esquema de información. Exploraremos cómo se compara con herramientas similares en otros sistemas de bases de datos, como Microsoft SQL Server y PostgreSQL. Al final de esta guía, tendrá un entendimiento sólido de cómo aprovechar las tablas del sistema de Redshift para optimizar sus estrategias de gestión de datos.
¿Qué es un Esquema de Información en MS SQL Server?
Antes de adentrarnos en los detalles específicos de Redshift, comencemos con un punto de referencia familiar: el Esquema de Información de Microsoft SQL Server.
Entendiendo los Conceptos Básicos
En MS SQL Server, el Esquema de Información es un conjunto de vistas que proporcionan metadatos sobre los objetos en una base de datos. Es una forma estandarizada de acceder a información sobre tablas, columnas, vistas y otros objetos de la base de datos.
Por ejemplo, para ver todas las tablas en una base de datos usando el Esquema de Información de MS SQL Server, puede usar una consulta como esta:
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE';
Esta consulta devolvería una lista de todas las tablas base en la base de datos actual.
Esquema de la Base de Datos Redshift: Herramientas de Información
Ahora, centrémonos en Redshift, un almacén de datos a escala de petabytes de Amazon Web Services. Aunque Redshift está basado en PostgreSQL, tiene su propio conjunto de tablas y vistas del sistema que sirven a un propósito similar al Esquema de Información en otros sistemas de bases de datos.
Tablas del Sistema en Redshift
Redshift proporciona un conjunto de tablas del sistema que almacenan metadatos sobre los datos en la nube, sus tablas y otros objetos. Estas tablas del sistema están prefijadas con “PG_”, “STL_”, “STV_” o “SVV_”.
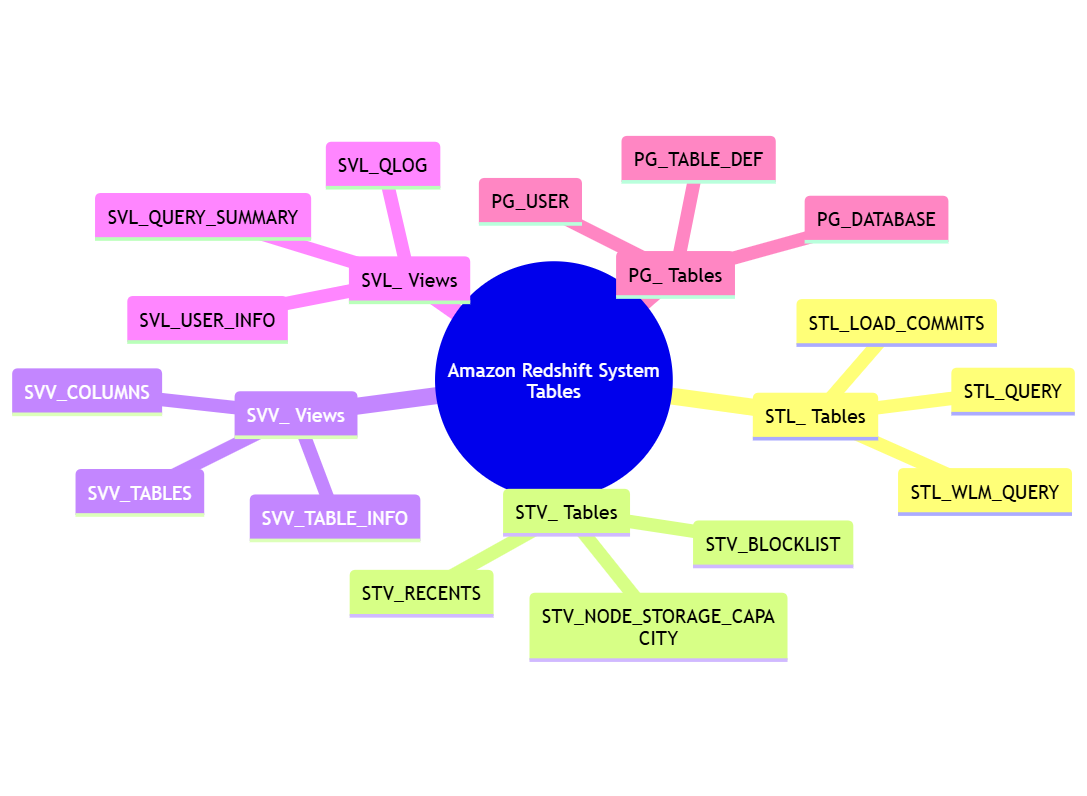
Aquí hay algunas tablas clave del sistema en Redshift:
- PG_TABLE_DEF: Contiene información sobre las definiciones de las tablas.
- SVV_COLUMNS: Proporciona una vista de todas las columnas en la base de datos.
- SVV_TABLES: Ofrece una vista de todas las tablas en la base de datos.
Veamos un ejemplo de cómo usar estas tablas:
SELECT tablename, "column", type, encoding FROM pg_table_def WHERE schemaname = 'public';
Esta consulta devolverá información sobre todas las columnas en las tablas dentro del esquema ‘public’, incluidos sus nombres, tipos de datos y codificación.
Consultas del Esquema de la Base de Datos Redshift
Para obtener una vista completa del esquema de su base de datos Redshift, puede usar consultas que combinen información de múltiples tablas del sistema. Aquí hay un ejemplo:
SELECT
n.nspname AS schema_name,
c.relname AS table_name,
a.attname AS column_name,
t.typname AS data_type
FROM
pg_catalog.pg_class c
JOIN
pg_catalog.pg_namespace n ON n.oid = c.relnamespace
JOIN
pg_catalog.pg_attribute a ON a.attrelid = c.oid
JOIN
pg_catalog.pg_type t ON t.oid = a.atttypid
WHERE
c.relkind = 'r' -- Solo tablas regulares
AND n.nspname NOT IN ('pg_catalog', 'information_schema')
AND a.attnum > 0 -- Excluir columnas del sistema
ORDER BY
schema_name, table_name, a.attnum;Esta consulta proporciona una vista detallada del esquema de su base de datos Redshift, incluidos nombres de esquemas, nombres de tablas, nombres de columnas y tipos de datos.
Comparación de Herramientas de Información entre Redshift y PostgreSQL
Dado que Redshift está basado en PostgreSQL, es natural preguntarse sobre las similitudes y diferencias en sus herramientas del esquema de información.
Esquema de Información de PostgreSQL
PostgreSQL, al igual que MS SQL Server, tiene un INFORMATION_SCHEMA que cumple con el estándar SQL. Proporciona vistas que ofrecen información sobre todos los objetos de la base de datos.
Por ejemplo, para listar todas las tablas en PostgreSQL, puede usar:
SELECT table_name FROM information_schema.tables WHERE table_schema = 'public';
Redshift vs PostgreSQL
Aunque Redshift está basado en PostgreSQL, no incluye el INFORMATION_SCHEMA estándar. En su lugar, proporciona sus propias tablas y vistas del sistema. Esto se debe a la naturaleza especializada de Redshift como un almacén de datos columnar, que requiere diferentes herramientas de optimización y gestión.
Sin embargo, muchos de los conceptos son similares. Por ejemplo, donde PostgreSQL tiene information_schema.tables, Redshift tiene SVV_TABLES. Ambos proporcionan metadatos sobre las tablas en la base de datos, pero los detalles sobre qué información está disponible y cómo se accede pueden diferir.
Aprovechamiento de las Tablas del Sistema de Redshift para la Optimización del Rendimiento
Entender las tablas del sistema de Redshift puede ayudarle a optimizar el rendimiento de su base de datos. Exploremos algunas aplicaciones prácticas.
Identificación de Desbalanceo de Tablas
El desbalanceo de tablas ocurre cuando los datos se distribuyen de manera desigual entre los segmentos en Redshift. Esto puede llevar a problemas de rendimiento. Puede usar las tablas del sistema para identificar el desbalanceo:
SELECT
trim(name) AS table,
slice,
count(*) AS num_values,
cast(100 * ratio_to_report(count(*)) over () AS decimal(5,2)) AS pct_of_total
FROM svv_diskusage
WHERE name IN ('your_table_name')
GROUP BY name, slice
ORDER BY name, slice;Esta consulta muestra la distribución de datos entre los segmentos para una tabla específica, ayudándole a identificar posibles problemas de desbalanceo.
Monitoreo del Rendimiento de Consultas
Las tablas STL_QUERY y SVL_QUERY_SUMMARY de Redshift pueden ayudarle a monitorear el rendimiento de las consultas:
SELECT q.query, q.starttime, q.endtime, q.elapsed/1000000 AS elapsed_seconds, s.segment, s.step, s.maxtime/1000000 AS step_seconds, s.rows, s.bytes FROM stl_query q JOIN svl_query_summary s ON q.query = s.query WHERE q.starttime >= DATEADD(hour, -1, GETDATE()) ORDER BY q.query, s.segment, s.step;
Esta consulta proporciona información detallada sobre las consultas ejecutadas en la última hora, incluidos su tiempo de ejecución y uso de recursos.
Mejores Prácticas para Usar el Esquema de Información de Redshift
Para aprovechar al máximo las tablas y vistas del sistema de Redshift, considere las siguientes mejores prácticas:
- Monitoree regularmente las estadísticas de las tablas usando SVV_TABLE_INFO para asegurarse de que sus tablas estén optimizadas.
- Use STL_ALERT_EVENT_LOG para identificar y abordar problemas de rendimiento de manera proactiva.
- Aproveche SVV_VACUUM_PROGRESS para monitorear y gestionar las operaciones de VACUUM.
- Utilice SVV_DATASHARE_OBJECTS para gestionar el intercambio de datos entre clústeres de Redshift.
Recuerde, aunque estas tablas del sistema proporcionan información valiosa, consultarlas frecuentemente puede afectar el rendimiento. Úselas con criterio y considere almacenar en caché los resultados cuando sea apropiado.
Conclusión
Entender y usar efectivamente las herramientas del esquema de información de Redshift es crucial para gestionar y optimizar su almacén de datos. Aunque difiere del INFORMATION_SCHEMA estándar encontrado en SQL Server y PostgreSQL, las tablas y vistas del sistema de Redshift ofrecen capacidades poderosas para monitorear, solucionar problemas y optimizar su base de datos.
Al aprovechar estas herramientas, puede obtener información profunda sobre el esquema de su base de datos Redshift, monitorear el rendimiento y tomar decisiones informadas sobre la gestión de datos y la optimización de consultas. Como con cualquier herramienta poderosa, use estas capacidades sabiamente para equilibrar la obtención de información con el rendimiento general del sistema.
Para aquellos que buscan herramientas avanzadas de seguridad y cumplimiento de bases de datos, considere explorar DataSunrise. Nuestras soluciones fáciles de usar y flexibles ofrecen una protección completa para bases de datos. Visite nuestro sitio web para una demostración en línea y descubra cómo puede mejorar su seguridad de la base de datos hoy mismo.
