
Explorando los Beneficios de la Generación de Datos Sintéticos para los Flujos de Trabajo Modernos

Una encuesta reciente de Gartner a más de 2,500 líderes ejecutivos reveló que el 45% ha incrementado sus inversiones en IA en respuesta al revuelo causado por ChatGPT. En DataSunrise, estamos en sintonía con esta tendencia. Probablemente ya ha leído nuestro artículo anterior sobre las herramientas basadas en IA para la generación de datos sintéticos (aleatorios o falsos). Este artículo se centra más en el tema de la generación de datos sintéticos con DataSunrise y algunas otras herramientas gratuitas disponibles.
Ya sea para pruebas, capacitación o desarrollo, obtener datos del mundo real plantea desafíos. Las preocupaciones de privacidad, problemas de disponibilidad de datos y restricciones regulatorias a menudo dificultan el acceso a datos reales. Aquí es donde la generación de datos aleatorios entra en juego. Ofrece una solución al crear datos artificiales que imitan las características de los datos reales sin comprometer la privacidad o la seguridad.
¿Qué son los Datos Sintéticos?
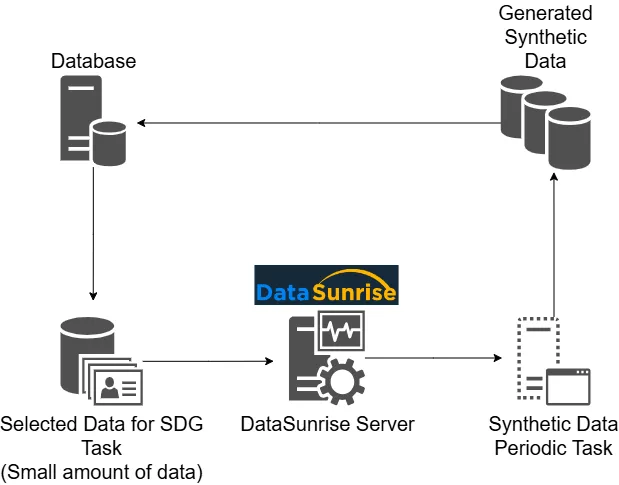
Los datos sintéticos son datos generados artificialmente que se asemejan a los datos del mundo real en términos de propiedades estadísticas, patrones y estructuras. No contienen ninguna información real sobre individuos o entidades. En su lugar, crea estos datos utilizando algoritmos y modelos matemáticos para mantener la autenticidad mientras evita los riesgos asociados con el manejo de datos sensibles.
Capacidades de DataSunrise en la Generación de Datos Sintéticos
DataSunrise ofrece una función robusta de generación de datos aleatorios que imita con precisión los datos de la vida real. Las personas utilizan esta función para diversos fines empresariales, desde el desarrollo y las pruebas hasta la mejora de los algoritmos de aprendizaje automático. Profundicemos en las capacidades de DataSunrise en el campo de la generación de datos sintéticos.
Pruebas de Privacidad y Seguridad de Datos
Una de las aplicaciones principales de los datos está en las pruebas de privacidad y seguridad de datos. Las organizaciones, especialmente en sectores como las finanzas, la salud y el derecho, pueden usar datos sintéticos para evaluar sus sistemas de seguridad sin exponer información sensible real. Por ejemplo, una institución financiera puede generar datos de transacciones sintéticas para probar sus sistemas de detección de fraude.
Entrenamiento de Modelos de Aprendizaje Automático
Las industrias utilizan cada vez más datos falsos para entrenar modelos de aprendizaje automático. Este enfoque asegura que la privacidad de los datos reales no se vea comprometida. Por ejemplo, una empresa de salud puede generar registros sintéticos de pacientes para entrenar un modelo predictivo para el diagnóstico de enfermedades sin violar la confidencialidad del paciente.
Desarrollo y Pruebas de Software
Los datos sintéticos son invaluables en el desarrollo de software. Proporcionan conjuntos de datos realistas para crear y evaluar aplicaciones, particularmente en industrias como las telecomunicaciones. Por ejemplo, una empresa de telecomunicaciones puede generar registros de llamadas sintéticas para probar su software de facturación.
Analítica de Salud
En el sector sanitario, dichos datos permiten a los investigadores y científicos de datos realizar estudios y experimentos sin violar la confidencialidad del paciente. Por ejemplo, un equipo de investigación puede generar datos sintéticos de pacientes para estudiar los efectos de un nuevo medicamento.
Cómo Generar Datos Sintéticos con DataSunrise
DataSunrise simplifica el proceso de generación de datos aleatorios, facilitando la integración de los datos en varios flujos de trabajo. Aquí hay una guía paso a paso sobre cómo generar datos usando DataSunrise.
Paso 1: Configuración General
Vaya a la Configuración – Tareas Periódicas. Haga clic en +Nueva tarea. En la subsección Configuración General, establezca el nombre de su Tarea Periódica. Seleccione el tipo de tarea: Generación de Datos Sintéticos y en qué servidor iniciarla (opcional).
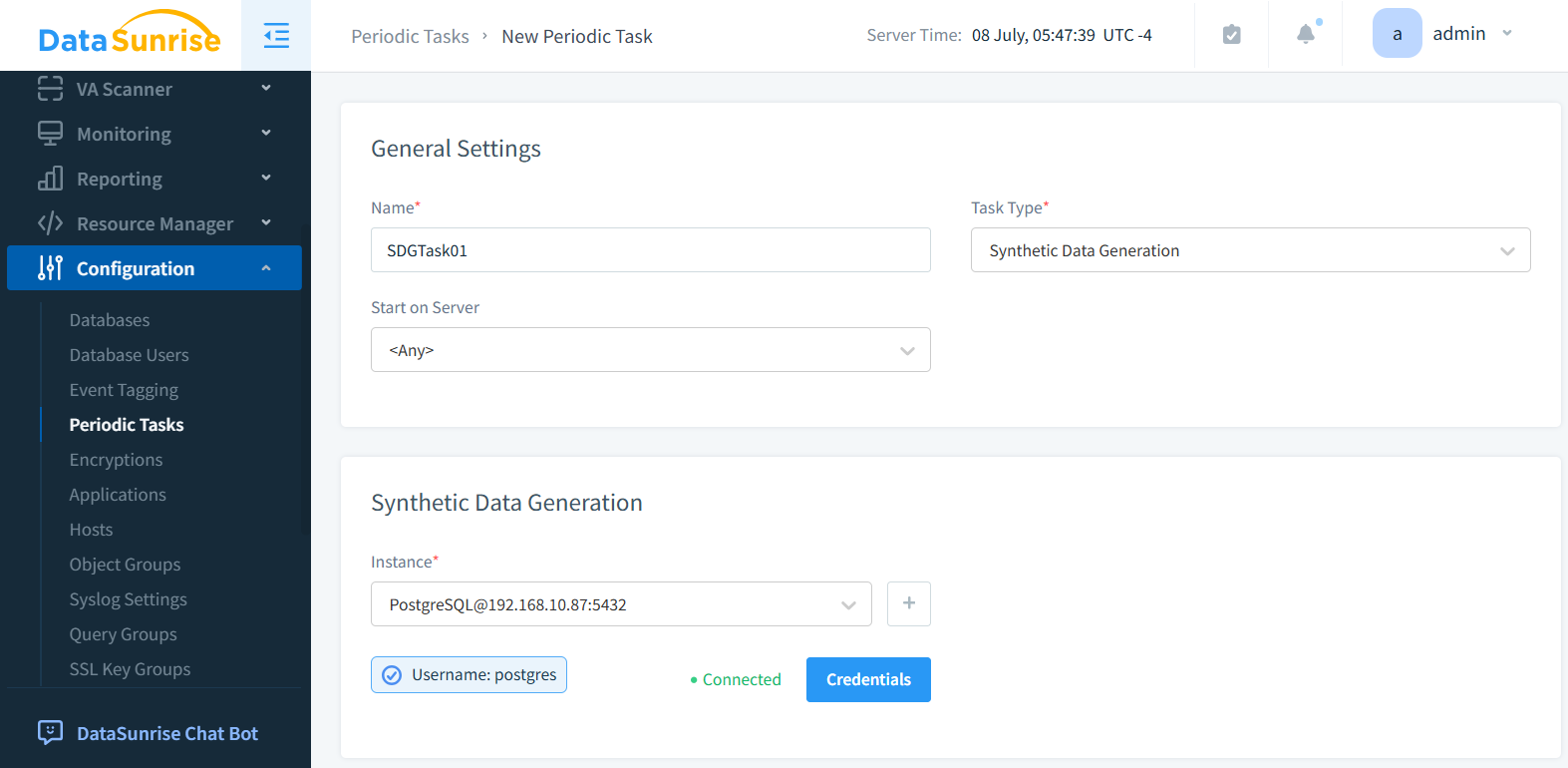
Paso 2: Seleccionar Instancia de Base de Datos
En la subsección Generación de Datos Sintéticos, seleccione la instancia de base de datos. En la figura de abajo se selecciona una instancia de PostgreSQL.
Paso 3: Tablas Generadas
En la subsección Tablas Generadas, seleccione las casillas necesarias (por ejemplo, Tabla de Destino Vacía y Omitir Generación de Tabla en Caso de Error). Haga clic en +Seleccionar para abrir una ventana donde puede elegir los objetos de la base de datos que necesite. Elija una base de datos, esquema, tabla y columna para la que se generarán datos sintéticos. Después de seleccionar, haga clic en Guardar.
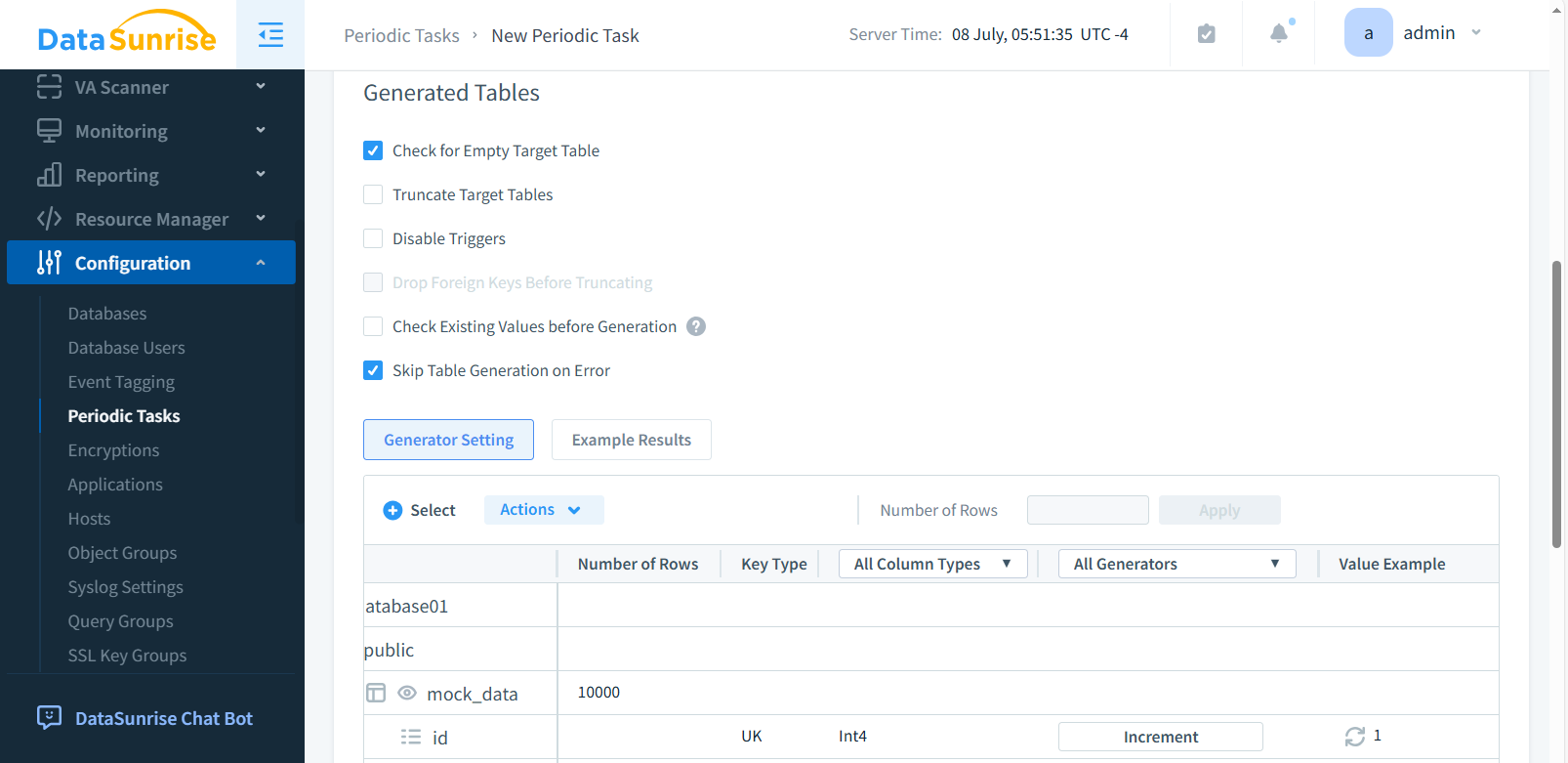
Paso 4: Selección de Generadores de Datos (opcional)
En la columna Todos los Generadores, puede seleccionar o crear el generador. En la sección de Resultados de Ejemplo, verá la lista de datos generados. Después de finalizar todo, haga clic en Aplicar o Guardar. Esto es opcional ya que el sistema asigna generadores predeterminados a las columnas seleccionadas.
Si desea crear su propio generador específico (antes de crear la tarea de Generación de Datos Sintéticos), vaya a Configuración – Generadores y haga clic en +Crear Generador. Seleccione un tipo de generador y especifique sus parámetros. Haga clic en Guardar, y podrá aplicar su generador en la Tarea de Generación de Datos Sintéticos.
El ‘Número de filas’ en la parte superior de la tabla se activa cuando se selecciona la columna.
Paso 5: Guardar y ejecutar la tarea
Aquí puede ver las Tareas Periódicas con la Tarea de Generación de Datos Sintéticos junto con algunas tareas periódicas de comportamiento de usuario creadas anteriormente.
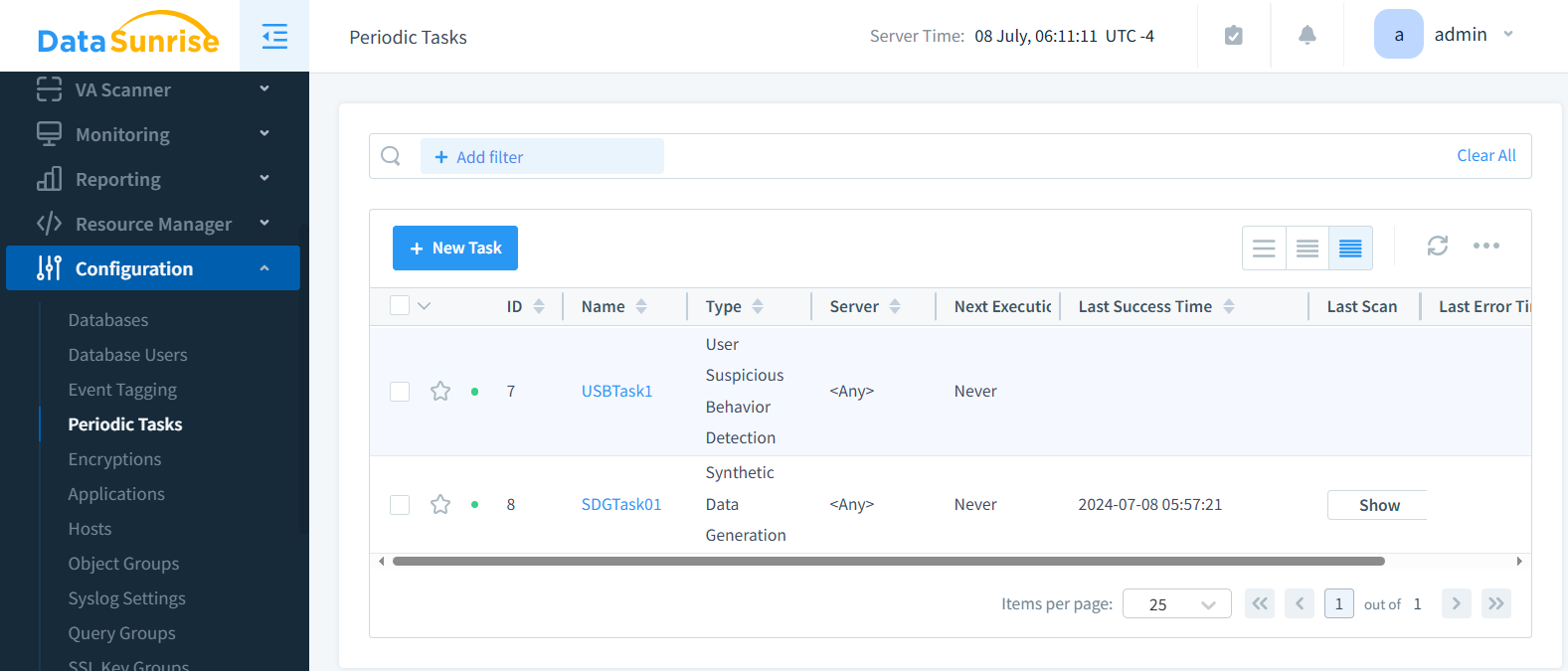
La tarea está lista ahora. Ejecute la tarea según sea necesario o prográmela para que se ejecute periódicamente.
Herramientas Online y Soluciones de Código Abierto
DataSunrise ofrece un control altamente flexible y robusto sobre la generación de datos aleatorios, junto con soluciones de seguridad de bases de datos de primera clase que brindan la mayor cobertura de bases de datos y almacenes en la nube disponibles en el mercado. Sin embargo, ¿qué pasa con las opciones gratuitas? Existen varias herramientas en línea y bibliotecas de código abierto disponibles para generar datos falsos sin costo. Exploremos algunas opciones populares:
SDV (Synthetic Data Vault)
Mencionamos brevemente este tema en nuestro artículo anterior sobre la generación de datos con IA. Allí mencionamos que CTGAN es un componente de SDV (Synthetic Data Vault). Para resumir, SDV es una biblioteca de Python de código abierto para generar datos relacionales de múltiples tablas. Utiliza el aprendizaje automático para crear datos artificiales que mantienen las propiedades estadísticas del conjunto de datos original. Para instalar usando pip, use el siguiente comando:
pip install sdv
Ejemplo de uso:
from sdv.datasets.demo import download_demo from sdv.single_table import GaussianCopulaSynthesizer # Descargar el conjunto de datos de demostración real_data, metadata = download_demo( modality='single_table', dataset_name='fake_hotel_guests' ) # Crear y ajustar el sintetizador synthesizer = GaussianCopulaSynthesizer(metadata) synthesizer.fit(real_data) # Generar datos falsos synthetic_data = synthesizer.sample(num_rows=500) # Mostrar las primeras filas de los datos generados print(synthetic_data.head())
Este script utiliza el sintetizador GaussianCopula de SDV para generar datos sintéticos basados en las propiedades estadísticas de un conjunto de datos real.
El resultado puede verse así:
CTGAN (Conditional Tabular GAN)
CTGAN es un modelo basado en GAN diseñado específicamente para generar datos tabulares sintéticos. Es particularmente útil para conjuntos de datos complejos con tipos de datos mixtos.
Consulte nuestro artículo anterior sobre herramientas relacionadas con IA para la generación de datos sintéticos para un ejemplo de código de CTGAN.
Mockaroo
Mockaroo es una herramienta web escrita en Ruby que le permite generar datos aleatorios realistas en varios formatos (CSV, JSON, SQL, etc.) sin necesidad de programar. Ofrece una interfaz fácil de usar y admite esquemas de datos personalizados. El acceso gratuito está limitado a 1000 filas de datos.
Mejores Prácticas para la Generación de Datos Falsos
Para garantizar datos de alta calidad:
- Comprenda sus requisitos de datos y su caso de uso
- Elija el método de generación adecuado según sus necesidades
- Valide los datos generados con su conjunto de datos original o requisitos
- Asegure la privacidad de los datos evitando la inclusión de información sensible
- Refine continuamente su proceso de generación basado en comentarios y resultados
Conclusión
La generación de datos sintéticos proporciona una solución valiosa para las organizaciones que buscan trabajar con datos realistas mientras protegen las preocupaciones de privacidad y seguridad. DataSunrise simplifica este proceso, facilitando la integración de datos artificiales en varios flujos de trabajo. Sin embargo, es esencial validar la efectividad y la fiabilidad de los datos sintéticos. Las organizaciones deben asegurarse de que los datos generados representen con precisión la distribución de datos reales y mantengan las relaciones y dependencias necesarias.
En resumen, la generación de datos ofrece numerosas ventajas, desde mejorar la privacidad y seguridad de los datos hasta mejorar los modelos de aprendizaje automático y las pruebas de software. Con la función de Generación de Datos Sintéticos de DataSunrise, las organizaciones pueden navegar con confianza en el panorama de los datos y aprovechar el poder de los datos generados para sus necesidades comerciales.
Para más información, visite nuestro sitio web o solicite una demostración en línea.
Siguiente
