
Generador de Datos IA

A medida que las perspectivas basadas en datos se han vuelto cruciales para las empresas de todos los tamaños, la demanda de conjuntos de datos de alta calidad y diversos ha aumentado. Sin embargo, obtener datos del mundo real puede ser desafiante, consume tiempo y a menudo plantea preocupaciones de privacidad. Aquí es donde entra en juego el generador de datos de Inteligencia Artificial, ofreciendo una solución poderosa a través de la generación de datos sintéticos. Profundicemos en este fascinante mundo y exploremos cómo la Inteligencia Artificial está transformando el panorama de la creación de datos.
Dado que DataSunrise implementa sus propias capacidades de generación de datos sintéticos, ricas en funciones y fáciles de usar, profundizaremos más en este tema, explorando específicamente las herramientas de código abierto disponibles hoy en día.
Entendiendo los Datos Sintéticos
Los datos sintéticos son información creada artificialmente que imita las características y propiedades estadísticas de los datos del mundo real. Se generan utilizando varios algoritmos y técnicas de IA, sin copiar directamente los puntos de datos actuales. Este enfoque ofrece numerosas ventajas, particularmente en escenarios donde los datos reales son escasos, sensibles o difíciles de obtener.
La Necesidad de Datos Sintéticos
Superando la Escasez de Datos
Una de las razones primordiales para usar datos sintéticos es superar la escasez de datos del mundo real. En muchos campos, especialmente en tecnologías emergentes, reunir suficientes datos para entrenar modelos de aprendizaje automático puede ser desafiante. Los generadores de datos de IA pueden producir grandes cantidades de datos diversos, ayudando a salvar esta brecha.
Protegiendo la Privacidad y Seguridad
Con el aumento de las preocupaciones sobre la privacidad de los datos y la seguridad, los datos sintéticos ofrecen una alternativa segura. Permite a las organizaciones trabajar con datos que se asemejan de cerca a la información real sin arriesgar la exposición de datos personales o empresariales sensibles. Esto es particularmente crucial en industrias como la atención médica y las finanzas, donde la protección de los datos es primordial.
Mejorando la Formación del Modelo
Los datos sintéticos se pueden usar para aumentar los conjuntos de datos existentes, mejorando el rendimiento y robustez de los modelos de aprendizaje automático. Al generar ejemplos adicionales y diversos, los modelos de IA pueden aprender a manejar una gama más amplia de escenarios, lo que lleva a una mejor generalización.
Tipos de Datos Sintéticos
Los generadores de datos de IA pueden producir varios tipos de datos sintéticos:
1. Datos Numéricos
Esto incluye valores continuos como mediciones, cifras financieras o lecturas de sensores. Los generadores de IA pueden crear datos numéricos con propiedades estadísticas específicas, tales como:
- Distribución de densidad de probabilidad
- Promedio
- Varianza
- Correlación entre variables
2. Datos Categóricos
Los datos categóricos representan categorías discretas o etiquetas. Los generadores de IA pueden crear datos categóricos sintéticos mientras mantienen la distribución y las relaciones encontradas en los conjuntos de datos del mundo real.
3. Texto
Desde frases simples hasta documentos complejos, la IA puede generar datos de texto sintético. Esto es particularmente útil para tareas de procesamiento de lenguaje natural y generación de contenido.
4. Imágenes
Las imágenes generadas por IA se están volviendo cada vez más sofisticadas. Estas pueden variar desde formas geométricas simples hasta imágenes fotorrealistas, útiles para aplicaciones de visión por computadora.
Mecanismos para la Generación de Datos Sintéticos
Se utilizan varios enfoques y técnicas en la generación de datos de IA:
Modelado Estadístico
Este enfoque implica crear modelos matemáticos que capturen las propiedades estadísticas de los datos reales. Los datos sintéticos se generan entonces para coincidir con estas propiedades.
Generación Basada en Aprendizaje Automático
Las técnicas avanzadas de aprendizaje automático, particularmente los modelos generativos, se utilizan para crear datos sintéticos altamente realistas. Algunos métodos populares incluyen:
- Redes Generativas Antagónicas (GANs): Estas involucran dos redes neuronales compitiendo entre sí, con una generando datos sintéticos y la otra tratando de distinguirlos de los datos reales.
- Autoencoders Variacionales (VAEs): Estos modelos aprenden a codificar datos en una representación comprimida y luego a decodificarlos, generando nuevas muestras de datos en el proceso.
- Modelos Transformer: Particularmente efectivos para la generación de texto, estos modelos han revolucionado las tareas de procesamiento de lenguaje natural.
Generación Basada en Reglas
Este método implica crear datos sintéticos basados en reglas y restricciones predefinidas. A menudo se utiliza cuando los datos deben seguir patrones o lógica empresarial específicos.
Herramientas Basadas en IA para la Generación de Datos de Prueba
La IA juega un papel crucial en la generación de datos de prueba para el desarrollo de software y el aseguramiento de la calidad. Estas herramientas pueden crear conjuntos de datos realistas y diversos que cubren varios escenarios de prueba, ayudando a descubrir problemas potenciales y casos límite.
Por ejemplo, un generador de datos de prueba basado en IA para una aplicación de comercio electrónico podría crear:
- Perfiles de usuarios con diversas demografías
- Catálogos de productos con diferentes atributos
- Historiales de pedidos con diversos patrones
Estos datos de prueba sintéticos pueden ayudar a los desarrolladores y a los equipos de QA a garantizar la robustez y fiabilidad de sus aplicaciones sin utilizar datos reales de los clientes.
Generación de Datos con IA Generativa
La IA generativa representa el punto más avanzado de la creación de datos sintéticos. Estos modelos pueden producir conjuntos de datos muy realistas y diversos en varios dominios. Algunas aplicaciones clave incluyen:
- Síntesis de imágenes para la formación de visión por computadora
- Generación de texto para el procesamiento de lenguaje natural
- Síntesis de voz y habla para aplicaciones de audio
- Generación de datos de series temporales para el modelado predictivo
Por ejemplo, un modelo de IA generativa entrenado en imágenes médicas podría crear rayos X sintéticos o resonancias magnéticas, ayudando a los investigadores a desarrollar nuevos algoritmos de diagnóstico sin comprometer la privacidad del paciente.
Herramientas y Librerías para la Generación de Datos Sintéticos
Existen varias herramientas y librerías disponibles para la generación de datos sintéticos. Una opción popular es la librería Python Faker. A diferencia de herramientas más complejas, no se basa en técnicas de aprendizaje automático o relacionadas con la IA. En lugar de eso, Faker utiliza enfoques robustos y clásicos para la generación de datos.
Librería Python Faker
Faker es un paquete de Python que genera datos falsos para varios propósitos. Es particularmente útil para crear datos de prueba que parecen realistas.
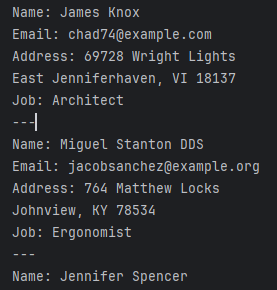
Aquí hay un ejemplo simple de cómo usar Faker para generar datos de usuario sintéticos:
from faker import Faker
fake = Faker()
# Generar 5 perfiles de usuario falsos
for _ in range(5):
print(f"Nombre: {fake.name()}")
print(f"Correo electrónico: {fake.email()}")
print(f"Dirección: {fake.address()}")
print(f"Trabajo: {fake.job()}")
print("---")Este script podría producir una salida como:
Librería CTGAN
CTGAN es una librería de Python específicamente diseñada para generar datos tabulares sintéticos usando Redes Generativas Antagónicas (GANs). Es parte del proyecto Synthetic Data Vault (SDV) y es adecuada para crear versiones sintéticas de conjuntos de datos estructurados. CTGAN funciona mucho más como un generador de datos de IA en comparación con Faker.
Así es como puedes usar CTGAN en Python:
Este es un ejemplo básico de cómo usar CTGAN (actualmente la guía de lectura recomienda instalar la librería SDV, que proporciona APIs fáciles de usar para acceder a CTGAN):
import pandas as pd
from ctgan import CTGAN
import numpy as np
# Crear un conjunto de datos de muestra
data = pd.DataFrame({
'edad': np.random.randint(18, 90, 1000),
'ingresos': np.random.randint(20000, 200000, 1000),
'educación': np.random.choice(['Secundaria', 'Licenciatura', 'Maestría', 'Doctorado'], 1000),
'empleado': np.random.choice(['Sí', 'No'], 1000)
})
print("Muestra de Datos Originales:")
print(data.head())
print("\nInfo de Datos Originales:")
print(data.describe())
# Inicializar y ajustar el modelo CTGAN
ctgan = CTGAN(epochs=10) # Usando menos épocas para este ejemplo
ctgan.fit(data, discrete_columns=['educación', 'empleado'])
# Generar muestras sintéticas
synthetic_data = ctgan.sample(1000)
print("\nMuestra de Datos Sintéticos:")
print(synthetic_data.head())
print("\nInfo de Datos Sintéticos:")
print(synthetic_data.describe())
# Comparar distribuciones
print("\nDistribuciones de Datos Originales vs Sintéticos:")
for column in data.columns:
if data[column].dtype == 'object':
print(f"\nDistribución de {column}:")
print("Original:")
print(data[column].value_counts(normalize=True))
print("Sintético:")
print(synthetic_data[column].value_counts(normalize=True))
else:
print(f"\nPromedio y desviación estándar de {column}:")
print(f"Original: promedio = {data[column].mean():.2f}, desviación estándar = {data[column].std():.2f}")
print(f"Sintético: promedio = {synthetic_data[column].mean():.2f}, desviación estándar = {synthetic_data[column].std():.2f}")El código produce una salida como esta (observa la diferencia en los parámetros estadísticos):
Muestra de Datos Originales: edad ingresos educación empleado 0 57 25950 Maestría No 1 78 45752 Secundaria No … Info de Datos Originales: edad ingresos count 1000.00000 1000.000000 promedio 53.75300 109588.821000 desviación estándar 21.27013 50957.809301 min 18.00000 20187.000000 25% 35.00000 66175.250000 50% 54.00000 111031.000000 75% 73.00000 152251.500000 max 89.00000 199836.000000 Muestra de Datos Sintéticos: edad ingresos educación empleado 0 94 78302 Licenciatura Sí 1 31 174108 Licenciatura No … Info de Datos Sintéticos: edad ingresos count 1000.000000 1000.000000 promedio 70.618000 117945.021000 desviación estándar 18.906018 55754.598894 min 15.000000 -5471.000000 25% 57.000000 73448.000000 50% 74.000000 112547.500000 75% 86.000000 163881.250000 max 102.000000 241895.000000
En este ejemplo:
- Importamos las librerías necesarias.
- Cargamos nuestros datos reales en un DataFrame de pandas.
- Inicializamos el modelo CTGAN.
- Ajustamos el modelo a nuestros datos, especificando cuáles columnas son discretas.
- Generamos muestras sintéticas usando el modelo entrenado.
CTGAN es particularmente útil cuando necesitas generar datos sintéticos que mantengan relaciones complejas y distribuciones presentes en tu conjunto de datos original. Es más avanzado que los métodos simples de muestreo aleatorio, como los utilizados en Faker.
Algunas características clave de CTGAN incluyen:
- Manejo de columnas numéricas y categóricas
- Preservación de correlaciones de columnas
- Manejo de distribuciones multi-modales
- Muestreo condicional basado en valores de columnas específicas
Otras Herramientas Notables
- SDV (Synthetic Data Vault): Una librería de Python para generar datos sintéticos relacionales multi-tabla.
- Gretel.ai: Una plataforma que ofrece varias técnicas de generación de datos sintéticos, incluyendo privacidad diferencial.

Generación de Datos de Imágenes
Si bien es cierto que Faker, SDV y CTGAN no admiten de manera nativa la generación de datos de imágenes y voz, efectivamente hay herramientas de código abierto disponibles para estos propósitos. Estas herramientas representan la tecnología más cercana a la IA en este campo y actualmente pueden servir como generadores de datos de IA totalmente desarrollados. Sin embargo, suelen ser más especializados y a menudo requieren más configuración y experiencia para usarlos de manera efectiva. He aquí un breve resumen:
Para la generación de imágenes:
- StyleGAN: Una arquitectura GAN avanzada, particularmente buena para imágenes de rostros de alta calidad.
- DALL-E mini (ahora llamado Craiyon): Una versión de código abierto inspirada en DALL-E de OpenAI, para generar imágenes a partir de descripciones de texto.
- Difusión Estable: Un avance reciente en la generación de texto a imagen, con implementaciones de código abierto disponibles.
Para la generación de datos de voz:
- Librerías TTS (Text-to-Speech) como Mozilla TTS o Coqui TTS: Pueden generar datos de voz sintéticos a partir de entrada de texto.
- WaveNet: Originalmente desarrollado por DeepMind, ahora tiene implementaciones de código abierto para generar habla realista.
- Tacotron 2: Otro modelo popular para generar voz parecida a la humana, con versiones de código abierto disponibles.
Estas herramientas son efectivamente “listas para usar” en el sentido de que están abiertamente disponibles, pero a menudo requieren:
- Más configuración técnica (por ejemplo, recursos de GPU, dependencias específicas)
- Entendimiento de los conceptos de aprendizaje profundo
- Posiblemente, ajuste fino en datos específicos del dominio
Esto contrasta con herramientas como Faker, que son más plug-and-play para tipos de datos más simples. La complejidad de los datos de imagen y voz requiere modelos más sofisticados, que a su vez requieren más experiencia para implementar de manera efectiva.
Mejores Prácticas para Usar Generadores de Datos de IA
- Valida los datos sintéticos: Asegúrate de que mantienen las propiedades estadísticas y relaciones de los datos originales.
- Usa experiencia en el dominio: Incorpora conocimientos del dominio para generar datos sintéticos realistas y significativos.
- Combina con datos reales: Cuando sea posible, usa datos sintéticos para aumentar los conjuntos de datos reales en lugar de reemplazarlos completamente.
- Considera las implicaciones de privacidad: Incluso con los datos sintéticos, ten cuidado con las posibles filtraciones de privacidad, especialmente en dominios sensibles.
- Actualiza regularmente los modelos: A medida que los datos del mundo real cambian, actualiza tus modelos generativos para asegurarte de que los datos sintéticos sigan siendo relevantes.
El Futuro de la Generación de Datos de IA
A medida que la tecnología de IA continúa avanzando, podemos esperar capacidades de generación de datos aún más sofisticadas y versátiles. Algunas tendencias emergentes incluyen:
- Mejora del realismo en los datos generados en todos los dominios
- Técnicas mejoradas para preservar la privacidad integradas en los procesos de generación
- Herramientas más accesibles para usuarios no técnicos para crear conjuntos de datos sintéticos personalizados
- Uso creciente de datos sintéticos en el cumplimiento de las regulaciones y escenarios de prueba
Conclusión
Los generadores de datos de IA están revolucionando la forma en que creamos y trabajamos con datos. Desde superar la escasez de datos hasta mejorar la privacidad y seguridad, los datos sintéticos ofrecen numerosos beneficios en diversas industrias. A medida que la tecnología continúa evolucionando, desempeñará un papel cada vez más crucial en la conducción de la innovación, la mejora de los modelos de aprendizaje automático y la habilitación de nuevas posibilidades en la toma de decisiones basada en datos.
Al aprovechar herramientas como la librería Python Faker y generadores más avanzados basados en IA, las organizaciones pueden crear conjuntos de datos diversos y realistas adaptados a sus necesidades específicas. Sin embargo, es crucial abordar la generación de datos sintéticos con cuidado, asegurando que los datos generados mantengan la integridad y relevancia necesarias para su uso previsto.
Al mirar hacia el futuro, el potencial de los generadores de datos de IA es ilimitado, prometiendo desbloquear nuevas fronteras en ciencia de datos, aprendizaje automático y más allá.
Para aquellos interesados en explorar herramientas fáciles de usar y flexibles para la seguridad de bases de datos, incluyendo capacidades de datos sintéticos, considera consultar DataSunrise. Nuestro conjunto integral de soluciones ofrece protección robusta y características innovadoras para entornos de datos modernos. Visita nuestro sitio web para una demostración en línea y descubre cómo nuestras herramientas pueden mejorar tu estrategia de seguridad de datos.
Siguiente
