
Simplificación del Flujo de Datos
Para empresas basadas en datos, el procesamiento eficiente de datos es crucial para obtener información y tomar decisiones informadas. Sin embargo, cuando se trata de información sensible, es esencial equilibrar la velocidad y la eficiencia con la privacidad y la seguridad de los datos. Este artículo analiza formas de simplificar los flujos de trabajo de datos utilizando métodos ETL y ELT, al tiempo que se protege la privacidad de los datos.
Comprendiendo los Enfoques para Simplificar el Procesamiento de Datos
Antes de sumergirnos en ETL y ELT, examinemos los enfoques comunes para simplificar el procesamiento de datos:
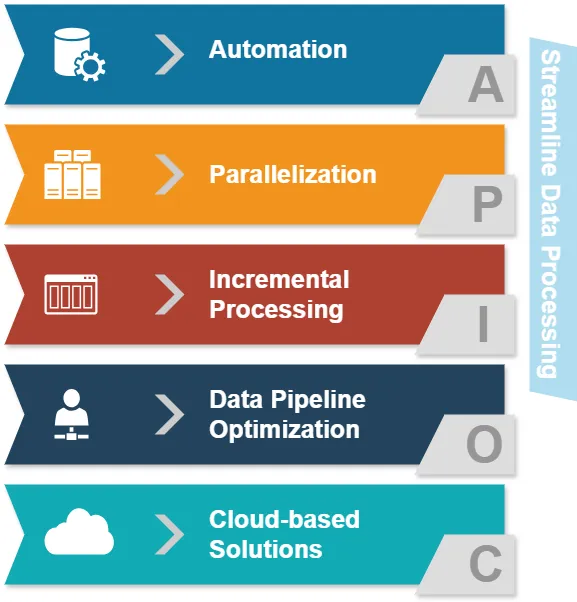
- Automatización: Reducir las intervenciones manuales en las tareas de procesamiento de datos.
- Paralelización: Procesar múltiples flujos de datos simultáneamente.
- Procesamiento incremental: Actualizar solo los datos cambiados en lugar de conjuntos de datos completos.
- Optimización del pipeline de datos: Asegurar un flujo de datos sin problemas entre diferentes etapas.
- Soluciones basadas en la nube: Aprovechar la infraestructura escalable para el procesamiento de datos.
Estos enfoques tienen como objetivo mejorar la eficiencia del procesamiento de datos. Ahora, exploremos cómo encajan ETL y ELT en este panorama.
ETL vs. ELT: Una Comparativa Rápida
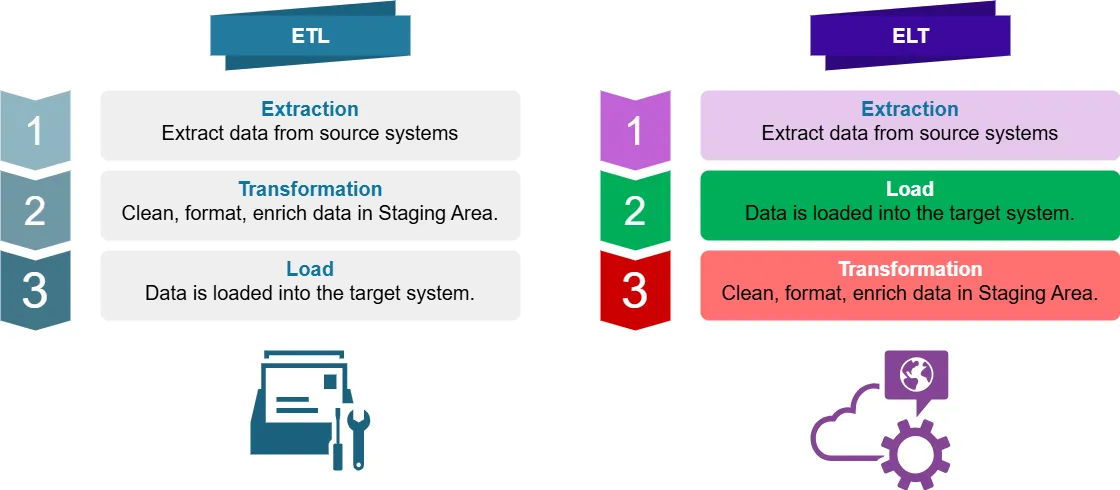
¿Qué es ETL?
ETL significa Extracción, Transformación, Carga. Es un proceso tradicional de integración de datos donde los datos son:
- Extraídos de los sistemas fuente de datos
- Transformados (limpios, formateados, enriquecidos) en un área de staging
- Cargados en el sistema objetivo (por ejemplo, un data warehouse)
¿Qué es ELT?
ELT significa Extracción, Carga, Transformación. Es un enfoque moderno donde los datos son:
- Extraídos de los sistemas fuente
- Cargados directamente en el sistema objetivo
- Transformados dentro del sistema objetivo
Diferencias Clave en el Procesamiento Óptimo de Datos
Para la inteligencia empresarial, la principal diferencia entre ETL y ELT radica en dónde y cuándo ocurre la transformación de datos. Esto influye en el procesamiento óptimo de datos de varias maneras:
- Poder de procesamiento: ETL depende de servidores de transformación separados, mientras que ELT aprovecha el poder del sistema objetivo.
- Flexibilidad de datos: ELT conserva los datos en bruto, permitiendo transformaciones más ágiles.
- Tiempo de procesamiento: ELT puede ser más rápido para conjuntos de datos grandes debido a sus capacidades de procesamiento en paralelo.
- Privacidad de datos: ETL puede ofrecer más control sobre los datos sensibles durante la transformación.
¿Dónde se Aplican ETL y ELT?
ETL se usa comúnmente en:
- Almacenamiento de datos tradicional
- Sistemas con almacenamiento o potencia de procesamiento limitados
- Escenarios que requieren transformaciones complejas de datos antes de la carga
ELT se prefiere a menudo para:
- Almacenes de datos en la nube
- Entornos de big data
- Procesamiento de datos en tiempo real o casi en tiempo real
- Situaciones donde es crucial conservar los datos en bruto
Simplificando los Flujos de Trabajo de Datos: Ejemplos en Python y Pandas
Examinemos algunos ejemplos de procesamiento de datos simplificado y no simplificado utilizando Python y Pandas.
Enfoque No Simplificado
import pandas as pd
# Leer datos desde un CSV
df = pd.read_csv('large_dataset.csv')
# Realizar múltiples transformaciones
df['new_column'] = df['column_a'] + df['column_b']
df = df[df['category'] == 'important']
df['date'] = pd.to_datetime(df['date'])
# Escribir los datos transformados a un nuevo CSV
df.to_csv('transformed_data.csv', index=False)Este enfoque lee todo el conjunto de datos en la memoria, realiza las transformaciones y luego escribe el resultado. Para conjuntos de datos grandes, esto puede ser intensivo en memoria y lento.
Enfoque Simplificado
import pandas as pd
# Usar fragmentos para procesar conjuntos de datos grandes
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
# Realizar transformaciones en cada fragmento
chunk['new_column'] = chunk['column_a'] + chunk['column_b']
chunk = chunk[chunk['category'] == 'important']
chunk['date'] = pd.to_datetime(chunk['date'])
# Añadir el fragmento transformado al archivo de salida
chunk.to_csv('transformed_data.csv', mode='a', header=False, index=False)Este enfoque simplificado procesa los datos en fragmentos, reduciendo el uso de memoria y permitiendo el procesamiento en paralelo. Es más eficiente para conjuntos de datos grandes y puede integrarse fácilmente en flujos de trabajo ETL o ELT.
Privacidad de Datos con ETL y ELT
Cuando se trata de datos sensibles, la privacidad es primordial. Tanto ETL como ELT pueden diseñarse para manejar información sensible de manera segura:
ETL y la Privacidad de Datos
- Enmascaramiento de datos: Aplicar técnicas de enmascaramiento durante la fase de transformación.
- Cifrado: Cifrar los datos sensibles antes de cargarlos en el sistema objetivo.
- Control de acceso: Implementar controles de acceso estrictos en el servidor de transformación.
Ejemplo de enmascaramiento de datos en ETL:
import pandas as pd
def mask_sensitive_data(df):
df['email'] = df['email'].apply(lambda x: x.split('@')[0][:3] + '***@' + x.split('@')[1])
df['phone'] = df['phone'].apply(lambda x: '***-***-' + x[-4:])
return df
# Proceso ETL
df = pd.read_csv('source_data.csv')
df = mask_sensitive_data(df)
# Otras transformaciones...
df.to_csv('masked_data.csv', index=False)ELT y la Privacidad de Datos
- Cifrado a nivel de columna: Cifrar columnas sensibles antes de la carga.
- Enmascaramiento dinámico de datos: Aplicar reglas de enmascaramiento en el sistema objetivo.
- Control de acceso basado en roles: Implementar políticas de acceso detalladas en el data warehouse.
Ejemplo de cifrado a nivel de columna en ELT:
import pandas as pd
from cryptography.fernet import Fernet
def encrypt_column(df, column_name, key):
f = Fernet(key)
df[column_name] = df[column_name].apply(lambda x: f.encrypt(x.encode()).decode())
return df
# Generar clave de cifrado (en la práctica, almacenar y gestionar esta clave de manera segura)
key = Fernet.generate_key()
# Proceso ELT
df = pd.read_csv('source_data.csv')
df = encrypt_column(df, 'sensitive_column', key)
# Cargar los datos en el sistema objetivo
df.to_sql('target_table', engine) # Suponiendo que 'engine' es tu conexión a la base de datos
# Transformar los datos dentro del sistema objetivoOptimizando los Flujos de Trabajo de Datos para Datos Sensibles
Para simplificar los flujos de trabajo de datos manteniendo la privacidad de los datos, considere estas mejores prácticas:
- Clasificación de datos: Identificar y categorizar los datos sensibles al inicio del proceso.
- Minimizar el movimiento de datos: Reducir la cantidad de veces que los datos sensibles se transfieren entre sistemas.
- Usar protocolos seguros: Emplear cifrado para los datos en tránsito y en reposo.
- Implementar gobernanza de datos: Establecer políticas claras para el manejo y acceso a los datos.
- Auditorías regulares: Realizar revisiones periódicas de tus flujos de trabajo de procesamiento de datos.
Conclusión
Es importante simplificar los flujos de trabajo de datos y asegurar que se proteja la información sensible con fuertes medidas de privacidad. Tanto los enfoques ETL como ELT tienen ventajas únicas y las organizaciones pueden optimizarlos para mejorar el rendimiento y la seguridad.
Este artículo trató sobre maneras en las que las organizaciones pueden crear flujos de trabajo de datos seguros. Estos flujos protegen la información sensible y permiten obtener información valiosa. Las organizaciones pueden usar estrategias y mejores prácticas para lograr este objetivo.
Recuerde, la elección entre ETL y ELT depende de su caso específico de uso, volumen de datos y requisitos de privacidad. Es importante revisar y actualizar regularmente sus estrategias de procesamiento de datos. Esto garantizará que se alineen con las necesidades cambiantes de su negocio y que cumplan con las leyes de protección de datos.
Para herramientas fáciles de usar que mejoran la seguridad y el cumplimiento en sus procesos de datos, consulte las opciones de DataSunrise. Visite nuestro sitio web en DataSunrise para ver una demostración y aprender cómo podemos mejorar su procesamiento de datos. Priorizamos mantener sus datos seguros y protegidos.
