
Tipo de Información: Conceptos Básicos de Seguridad Inspirada en los Datos
Introducción
DataSunrise cuenta con seguridad inspirada en datos, ofreciendo capacidades únicas y poderosas para un rápido descubrimiento de datos en cada solicitud de datos para una fuente de datos dada. Si bien este enfoque genera cierta sobrecarga en el tiempo de ejecución, proporciona una protección de base de datos extremadamente flexible.
Los tipos de información se introdujeron por primera vez en DataSunrise con la función Descubrimiento de datos sensibles, que escanea bases de datos y sistemas de almacenamiento como S3 en busca de datos sensibles.
Los tipos de información ofrecen funcionalidad más allá del descubrimiento básico de datos. Permiten la detección de tipos de datos en tiempo real y pueden disparar automáticamente reglas de protección o auditoría a través de seguridad inspirada en datos con cada consulta de la base de datos. Además, facilitan la etiquetación de rastros de auditoría, facilitando el seguimiento de eventos específicos de acceso a datos tanto en rastros transaccionales como en archivos de registro.
Descubriendo tipos de Información
Las propiedades de los datos deben almacenarse en una entidad para su análisis. A veces, estos datos tienen una estructura estricta con nombres de columnas, nombres de tablas y tipos. Otras veces, puede aparecer como archivos JSON, CSV, texto plano o incluso imágenes de documentos escaneados. DataSunrise permite buscar todos estos objetos en busca de datos sensibles.
Esto da lugar a descripciones flexibles de los tipos de información. Por ejemplo, los datos de correo electrónico pueden tener varias propiedades:
- El nombre de la columna contiene “correo electrónico”
- El nombre de la tabla contiene “correo electrónico”
- Los datos coinciden con la expresión regular “.*@.*“
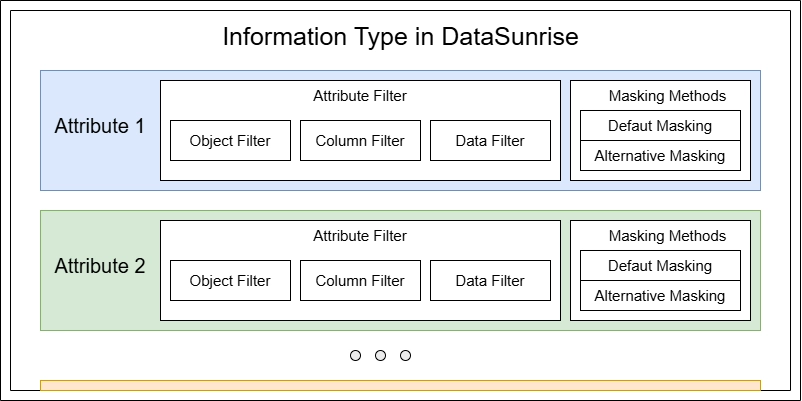
Para ser clasificado como información de correo electrónico, los datos deben cumplir con múltiples requisitos. Esto introduce otra entidad importante de DataSunrise llamada Atributo de información. Un tipo de información es esencialmente una colección de atributos que los datos deben coincidir para ser considerados un tipo específico.
Al buscar datos sensibles en un archivo de texto simple sin columnas y tablas, el conjunto de atributos puede ser diferente. Por ejemplo, el tipo de información de correo electrónico de texto plano podría requerir solo una coincidencia de expresiones regulares, sin necesidad de atributos adicionales.
Tipos de Información disponibles en DataSunrise
DataSunrise incluye numerosos tipos de información incorporados, cada uno asociado con los estándares de seguridad populares (GDPR, HIPAA, SOX y otros). Si bien esta asociación no es obligatoria para los tipos personalizados, ayuda a rastrear la actividad y recopilar datos de uso para las auditorías de cumplimiento.
Los usuarios pueden crear tipos de información personalizados, que van desde simples hasta complejos. El tipo de correo electrónico incorporado, por ejemplo, incluye atributos que coinciden con los nombres de las columnas y coincidencias de patrones complejos para el contenido del correo electrónico.
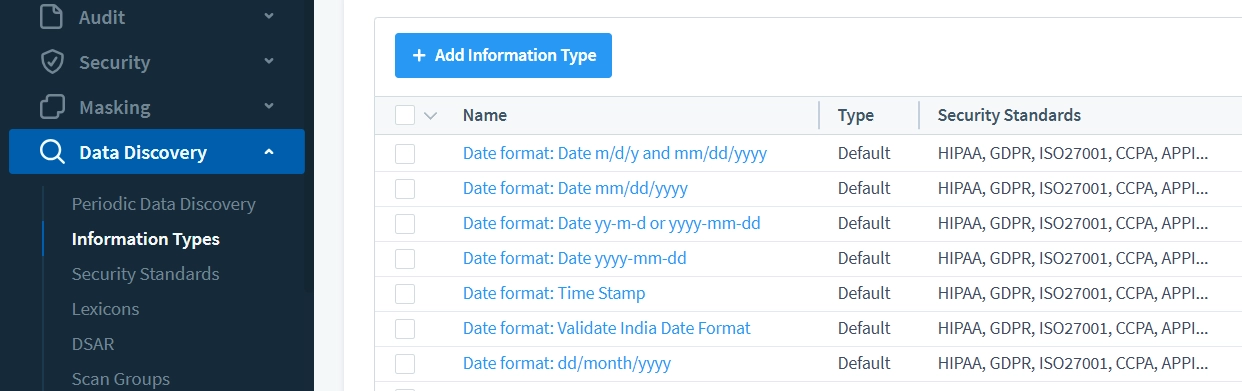
DataSunrise ofrece múltiples tipos de información de fecha para adaptarse a diversas convenciones de formato de fecha. Vale la pena mencionar que se pueden usar diferentes tipos de información para identificar el mismo tipo de datos cuando se almacenan en diferentes formatos.
Para una coincidencia de tipo de información más sencilla, recomendamos crear tipos personalizados con atributos más flexibles. En nuestra práctica, la mayoría de los usuarios crea un tipo de datos de correo electrónico personalizado que solo requiere que el contenido de los datos coincida con un patrón básico de expresión regular como “@.*”.
Los tipos personalizados le permiten agregar nuevos tipos de información para la detección y controlar cuánto coinciden estrictamente estos tipos de información con sus patrones de datos. Puede crear tipos de información que requieran múltiples atributos, cada uno conteniendo nombres de columna y patrones de datos, o alternativamente, crear tipos de información más simples con solo un atributo único que solo verifica el patrón de datos.
Cómo crear un tipo de información personalizado
Paso 1 – Agregar nuevo tipo de información
- Navega a Descubrimiento de datos – Tipos de información
- Presiona el botón “+ Añadir tipo de información” e ingresa un nombre adecuado para tu tipo de información personalizada.
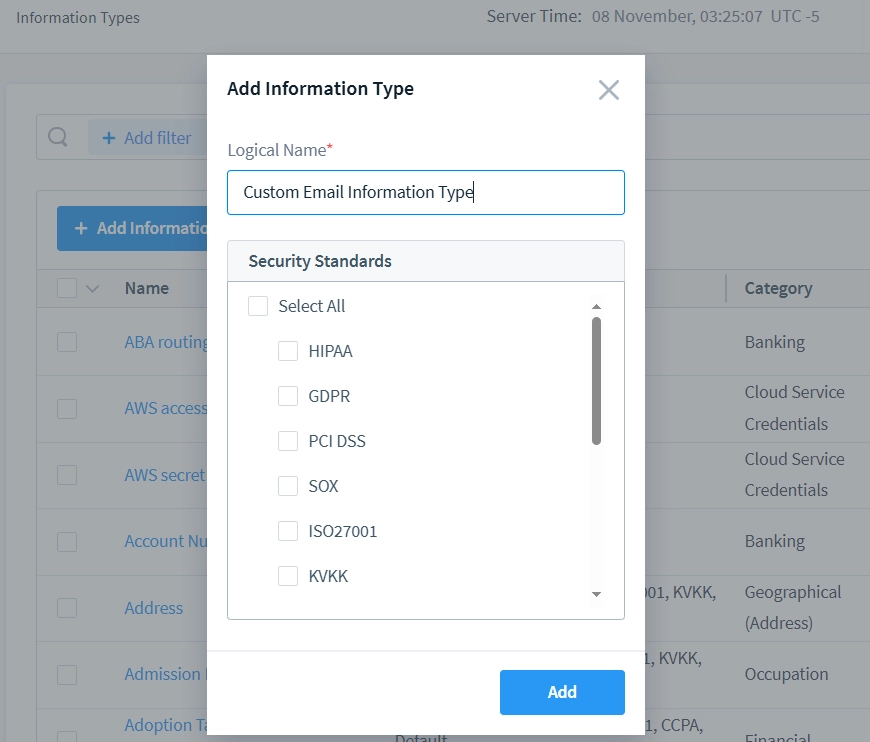
- Después de establecer el nombre del tipo de información, aparecerá en la lista en la página “Tipos de información”. Haz clic en el nuevo tipo de información para editar sus parámetros internos y atributos. Utilicemos el ‘Tipo de información de correo electrónico personalizado’ como ejemplo.
La página de edición del tipo de información contiene tres subsecciones principales:
- La sección Atributos te permite establecer los parámetros de coincidencia reales para el tipo de información. Puedes crear uno o más atributos, y cada atributo puede contener requisitos para el objeto de la base de datos, el nombre de la columna y el patrón de datos. El tipo de información coincide si cualquier atributo único coincide. Para los atributos incluidos, se deben cumplir todas las condiciones (objeto, patrón de nombre de columna y patrón de datos) si se especifican.
- La sección Estándares de seguridad te permite vincular el tipo de información al estándar de seguridad (-s). Esto es utilizado por la función de cumplimiento durante las tareas de descubrimiento, ya que la función de cumplimiento opera en función de los estándares de seguridad.
- La sección Administrar etiquetas te ayuda a encontrar fácilmente las entradas de registro de reglas en registros o informes. Puedes crear etiquetas personalizadas para este propósito.
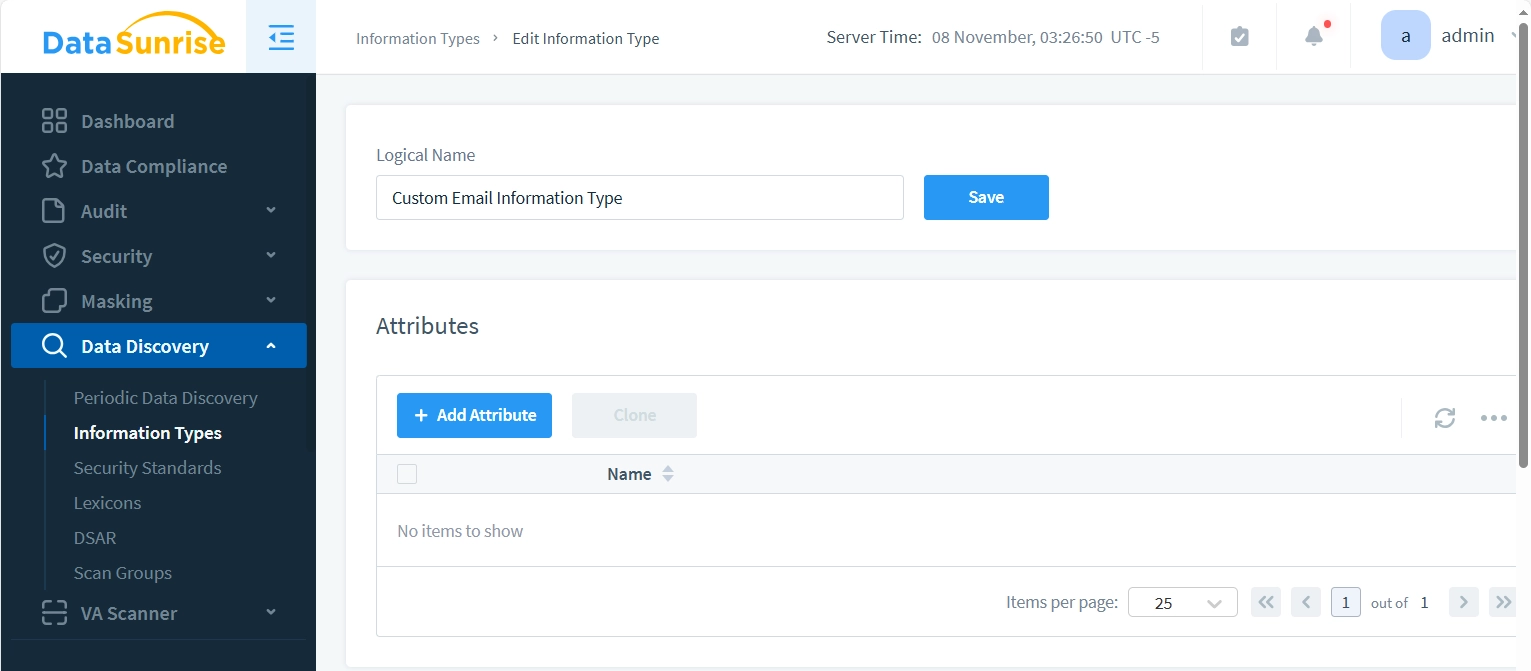
Paso 2 – Agregar Atributo al tipo de información
- Vamos a crear un atributo simple para el “Tipo de información de correo electrónico personalizado”. Presiona el botón “+ Añadir atributo” para comenzar. Lo ajustaremos para que coincida con los datos que siguen un patrón básico de correo electrónico: “.*@.*“
Nota: Este patrón es demasiado simplista e incorrectamente coincidirá con entradas no válidas como “@.” o “!!!@…”. Un patrón de validación de correo electrónico más robusto debería ser utilizado en entornos de producción.
El diálogo del nuevo atributo aparece con dos paneles: “Atributo” a la izquierda y “Prueba” a la derecha. El panel de Atributos se utiliza para configurar la configuración de su nuevo atributo, mientras que el panel de Prueba le permite verificar estas configuraciones a medida que las crea.
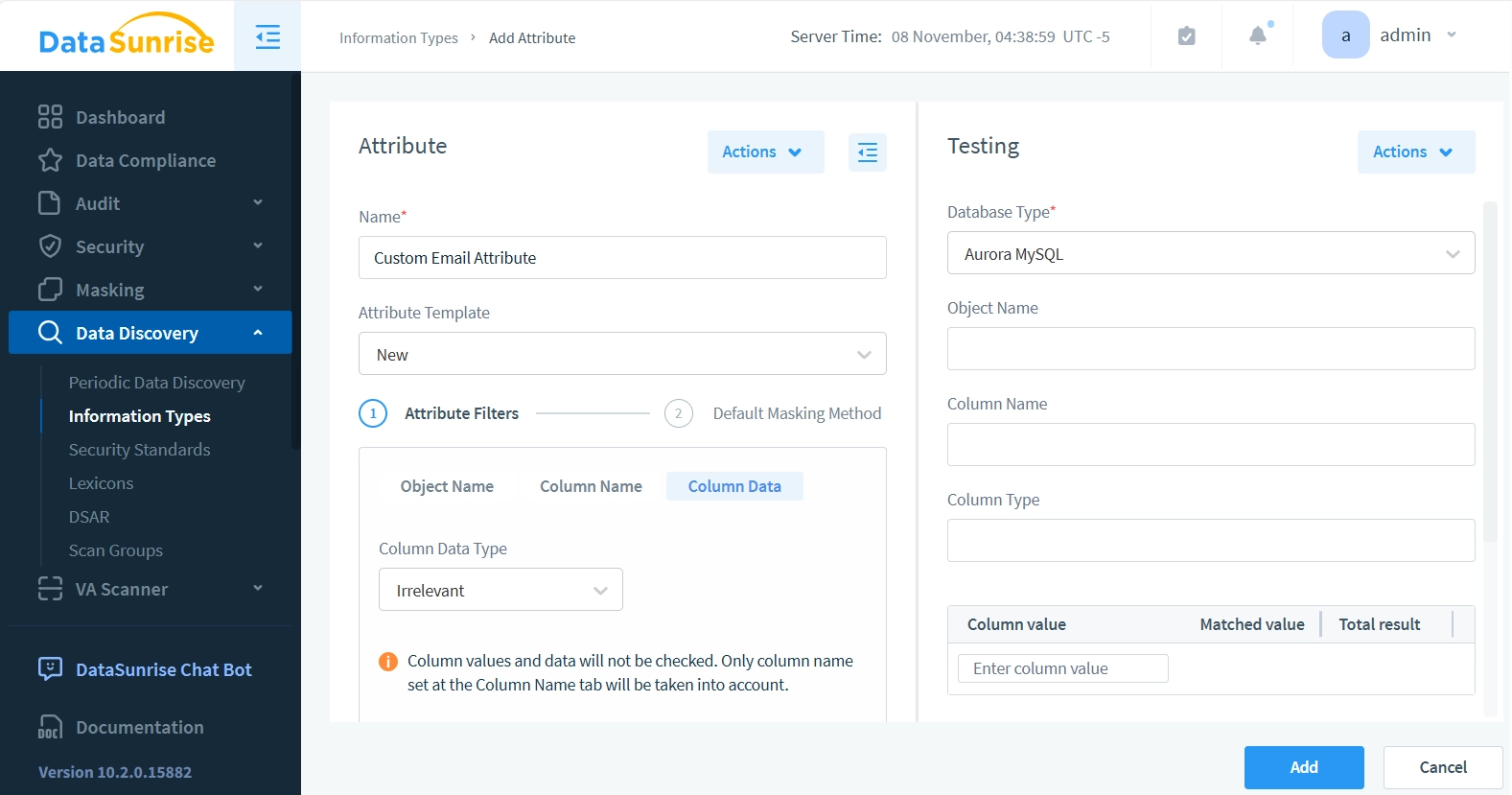
- En el panel “Atributo”, introduce “Atributo de correo electrónico personalizado” en el campo Nombre. Para la plantilla de atributos, dejaremos la opción “Nuevo” predeterminada, ya que todavía no tenemos disponibles otras plantillas.
A continuación, nos centraremos en dos áreas clave: filtros de atributos y método de enmascaramiento predeterminado.
- Para los filtros de atributos, deja los campos de nombre de objeto y de nombre de columna sin cambios. Haz clic solo en la opción de datos de columna. Esto significa que nuestro atributo ignorará los patrones de nombre de objeto y nombre de columna de la base de datos, centrándose únicamente en comprobar si la cadena de datos contiene un patrón similar al correo electrónico (con un carácter @).
- Establece el tipo de datos de columna en ‘Solo cadenas’ y el método de búsqueda en ‘Texto no estructurado’.
- Introduce “.*@.*” en el campo “Plantilla para el contenido de la columna (iniciar cada plantilla desde una nueva línea)”. Antes de guardar el atributo o usarlo en cualquier regla o tarea, podemos probar si coincide correctamente con los patrones de correo electrónico.
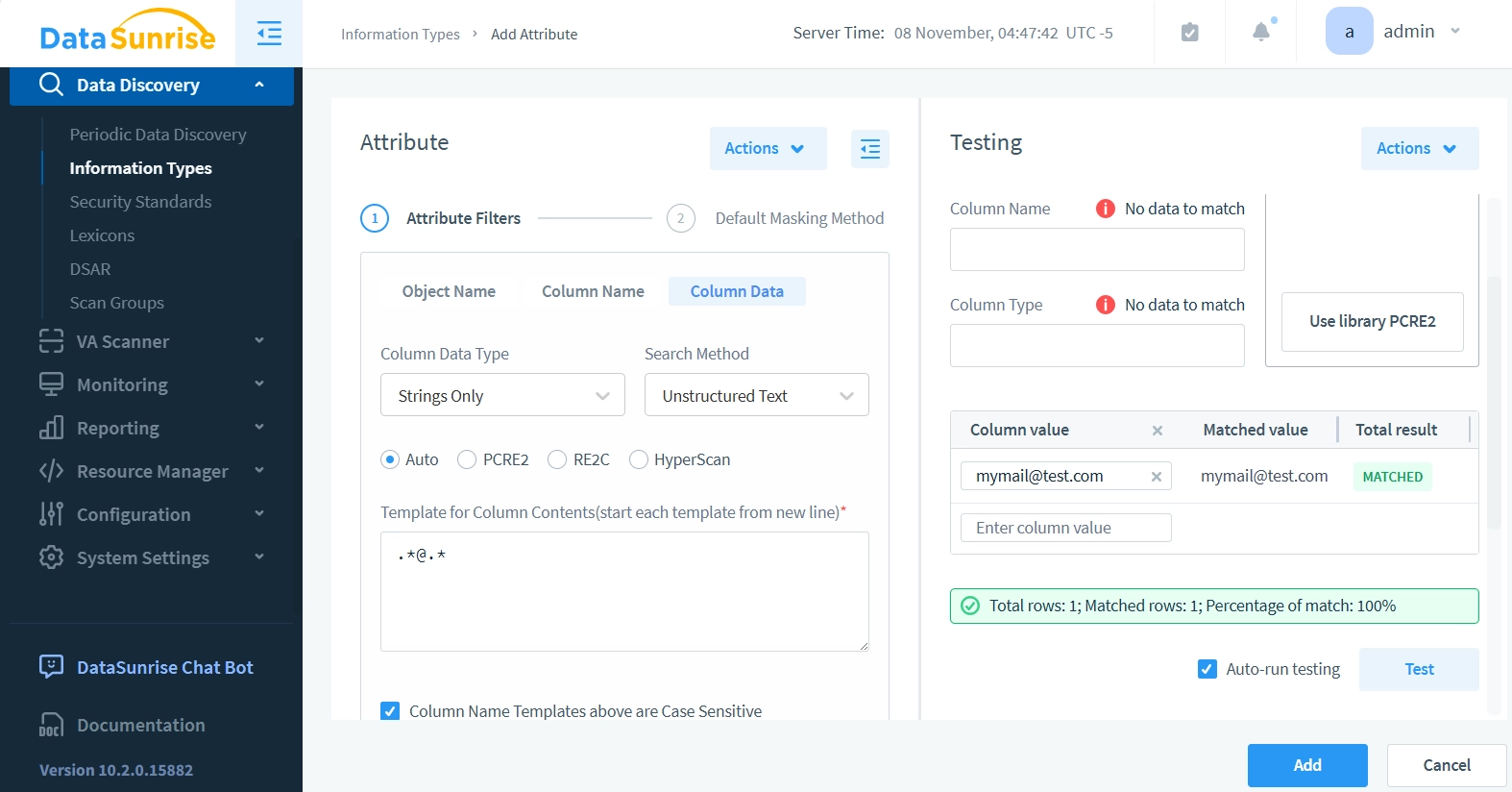
- Ahora utilicemos el panel de pruebas a la derecha. Deja todos los campos anteriores sin cambios e introduce un correo electrónico de muestra como “[email protected]” en el campo Valor de la columna. Haz clic en el botón de prueba – los resultados deberían mostrar que el atributo detecta con éxito los correos electrónicos en los datos de la columna.
Paso 3 – Configuración de enmascaramiento de atributos
- Haz clic en ‘2. Método de enmascaramiento predeterminado’ para continuar con la configuración del método de enmascaramiento. Esto cambia el panel de atributos a la configuración de enmascaramiento.
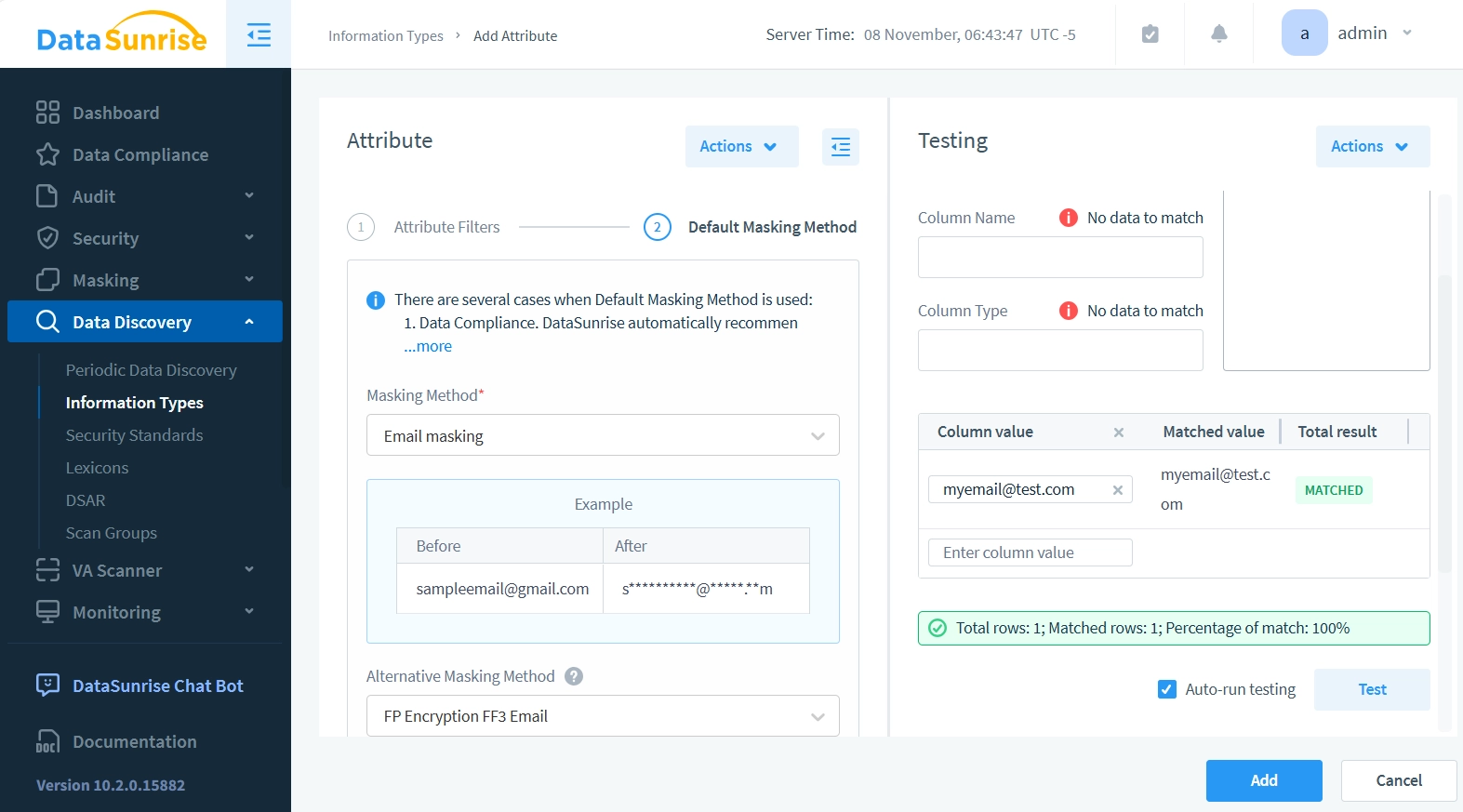
- Establece el desplegable del Método de enmascaramiento en Enmascaramiento de correo electrónico. El Método de enmascaramiento predeterminado se utiliza en la herramienta de cumplimiento de datos, en el enmascaramiento dinámico inspirado en datos y en el enmascaramiento estático. DataSunrise aplica este método de enmascaramiento cuando no hay restricciones clave que deban mantenerse para preservar la integridad de la base de datos enmascarada.
- Establece el desplegable del Método de enmascaramiento alternativo en Encriptación FP FF3 para correo electrónico. Los métodos de enmascaramiento alternativos son necesarios para mantener la integridad referencial de la tabla. No puedes simplemente enmascarar las claves ajenas con cadenas aleatorias, ya que esto rompería las referencias entre las tablas. El enmascaramiento debe asegurar que las referencias de otras tablas todavía apunten a las filas correctas después de que se aplique el enmascaramiento. De manera similar, las claves primarias deben seguir siendo únicas y mantener sus relaciones referenciales con otras tablas incluso después del enmascaramiento.
En el ejemplo de Enmascaramiento estático a continuación, las columnas ‘correo electrónico’ y ‘correo electrónico de contacto’ están enmascaradas utilizando diferentes métodos debido a las restricciones clave. Por ejemplo, la dirección de correo electrónico de John Doe, que tiene una restricción de clave ajena, está enmascarada como ‘[email protected]’. Mientras tanto, su correo electrónico de contacto, que no tiene restricciones, está enmascarado utilizando el método predeterminado, apareciendo como ‘j***.***@.**m’.
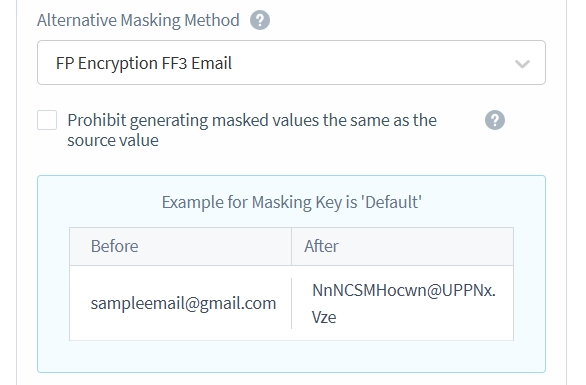
Importante: Mientras que esta configuración es compatible con las bases de datos tradicionales, algunos sistemas de almacenamiento como Amazon S3 y archivos de texto no estructurados no siguen la organización típica de la base de datos con columnas y objetos. Para estos tipos de almacenamiento, ten cuidado al usar los filtros de nombre de objeto y nombre de columna, ya que pueden impedir la correcta coincidencia de datos.
- Haz clic en el botón ‘Añadir’ para vincular el Atributo al Tipo de Información.
Prueba de los tipos de información con métodos de enmascaramiento alternativo
El siguiente ejemplo demuestra cómo DataSunrise implementa tanto los métodos de enmascaramiento predeterminados como los alternativos. Examinemos esto a través de la creación de tablas de muestra:
-- Creando la tabla de correos electrónicos (tabla principal)
CREATE TABLE correos_electronicos (
correo VARCHAR(50) PRIMARY KEY,
tipo_correo VARCHAR(20),
fecha_creacion DATE
);
-- Creando la tabla de empleados con correo de contacto adicional
CREATE TABLE empleados (
id_empleado INT PRIMARY KEY,
primer_nombre VARCHAR(30),
apellidos VARCHAR(30),
correo VARCHAR(50),
correo_contacto VARCHAR(50),
fecha_contratacion DATE,
FOREIGN KEY (correo) REFERENCES correos_electronicos(correo)
);
-- Insertando datos en la tabla correos
INSERT INTO correos_electronicos VALUES
('[email protected]', 'corporativo', '2023-01-15'),
('[email protected]', 'corporativo', '2023-02-20'),
…
('[email protected]', 'corporativo', '2023-05-01');
-- Insertando datos en la tabla empleados con correos de contacto
INSERT INTO empleados VALUES
(1, 'John', 'Doe', '[email protected]', '[email protected]', '2023-01-16'),
(2, 'Sarah', 'Smith', '[email protected]', '[email protected]', '2023-02-21'),
…
(5, 'Peter', 'Jones', '[email protected]', '[email protected]', '2023-05-02');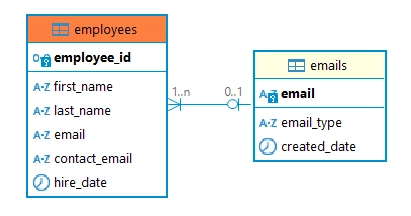
Enmascaramiento estático con enmascaramiento predeterminado y alternativo
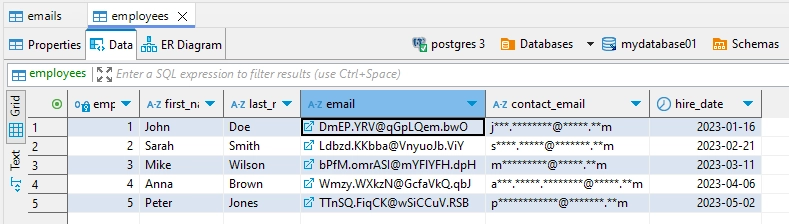
El enmascaramiento estático permite a los usuarios enmascarar automáticamente los datos sensibles identificados durante el proceso de descubrimiento. Este enfoque automatizado, conocido como Modo automático, determina qué tablas de origen transferir y qué columnas enmascarar. El sistema implementa dos estrategias de enmascaramiento distintas: una para los campos de datos estándar y otra para los elementos de datos relacionales (como claves ajenas y primarias). Este enfoque dual garantiza la coherencia de los datos mientras se mantiene la integridad referencial a través de las relaciones de la base de datos.
Durante la ejecución de la tarea de enmascaramiento estático en la tabla ’empleados’, se aplicaron diferentes métodos de enmascaramiento a los campos de correo electrónico. La columna restringida ‘correo electrónico’, que sirve como clave externa, mantuvo su formato a través de enmascaramiento preservado de formato. Mientras tanto, la columna ‘correo de contacto’ sin restricciones experimentó un enmascaramiento de caracteres simples, donde solo se oscureció la porción media de las direcciones de correo electrónico.
Conclusión
Este artículo proporcionó una exploración en profundidad de los tipos de información de DataSunrise. Te guiámos a través de los pasos principales para crear tipos de información y definir sus atributos. Los tipos de información se utilizan principalmente en el Descubrimiento de datos para identificar datos sensibles basados en propiedades específicas definidas por sus atributos. Además, estos tipos de información se utilizan activamente durante el acceso a datos a través de una función llamada Seguridad inspirada en los datos, que permite el enmascaramiento de datos, el bloqueo y la etiquetación de eventos de registro.
También examinamos casos de uso para el enmascaramiento predeterminado y discutimos cómo se pueden aplicar métodos de enmascaramiento alternativos cuando las tareas de enmascaramiento estático encuentran restricciones clave en la base de datos enmascarada.
