
Procedimiento de Enmascaramiento: Protección de Datos en Dataframes

Introducción
Es posible que hayas encontrado nuestros artículos sobre enmascaramiento de datos desde una perspectiva de almacenamiento de datos, donde discutimos técnicas de enmascaramiento estáticas, dinámicas y en su lugar. Sin embargo, el procedimiento de enmascaramiento en ciencia de datos difiere ligeramente. Aunque todavía necesitamos mantener la privacidad y proteger los datos en dataframes, también buscamos obtener información basada en datos. El desafío radica en mantener la información del dato mientras se garantiza su confidencialidad.
A medida que las organizaciones confían cada vez más en la ciencia de datos para obtener información y tomar decisiones, la necesidad de técnicas robustas de protección de datos nunca ha sido tan grande. Este artículo profundiza en el tema crucial del enmascaramiento de datos en dataframes, explorando cómo este procedimiento protege datos sensibles mientras mantiene su utilidad para el análisis.
Comprensión del Enmascaramiento de Datos en Ciencia de Datos
El enmascaramiento de datos es un proceso crítico en el ámbito de la protección de datos. Aunque no profundizaremos demasiado en sus aspectos generales, es esencial entender su papel en la ciencia de datos.
En el contexto de la ciencia de datos, las técnicas de enmascaramiento juegan un papel vital en la preservación de las características estadísticas de los conjuntos de datos mientras ocultan información sensible. Este equilibrio es crucial para mantener la utilidad de los datos mientras se garantiza la privacidad y el cumplimiento de los requisitos regulatorios.
Enmascaramiento con Preservación de Formato: Equilibrio entre Utilidad y Privacidad
Las técnicas de enmascaramiento con preservación de formato son particularmente valiosas en aplicaciones de ciencia de datos. Estos métodos ayudan a mantener los parámetros estadísticos del conjunto de datos mientras protegen efectivamente la información sensible. Al preservar el formato y la distribución de los datos originales, los investigadores y analistas pueden trabajar con conjuntos de datos enmascarados que se asemejan estrechamente a los datos auténticos, asegurando la validez de sus hallazgos sin comprometer la privacidad.
¿Qué es un Dataframe?
Antes de profundizar en los procedimientos de enmascaramiento, aclaremos qué es un dataframe. En ciencia de datos, un dataframe es una estructura de datos etiquetada en dos dimensiones con columnas de tipos potencialmente diferentes. Es similar a una hoja de cálculo o tabla SQL y es una herramienta fundamental para la manipulación y el análisis de datos en muchos lenguajes de programación, particularmente en Python con bibliotecas como Pandas.
Enmascaramiento de Datos en Dataframes
Cuando se trata de proteger información sensible en dataframes, hay dos enfoques principales:
- Enmascaramiento durante la formación del dataframe
- Aplicación de técnicas de enmascaramiento después de la creación del dataframe
Exploremos ambos métodos en detalle.
Enmascaramiento Durante la Formación del Dataframe
Este enfoque implica aplicar técnicas de enmascaramiento mientras los datos se están cargando en el dataframe. Es particularmente útil cuando se trabaja con conjuntos de datos grandes o cuando deseas asegurarte de que los datos sensibles nunca ingresen a tu entorno de trabajo en su forma original.
Ejemplo: Enmascaramiento Durante la Importación de CSV
He aquí un simple ejemplo usando Python y pandas para enmascarar datos sensibles mientras se importa un archivo CSV:
import pandas as pd
import hashlib
def mask_sensitive_data(value):
return hashlib.md5(str(value).encode()).hexdigest()
# Leer archivo CSV con función de enmascaramiento aplicada a la columna 'ssn'
df = pd.read_csv('employee_data.csv', converters={'ssn': mask_sensitive_data})
print(df.head())En este ejemplo, estamos utilizando una función hash para enmascarar la columna ‘ssn’ (Número de Seguridad Social) mientras se leen los datos en el dataframe. El resultado sería un dataframe donde la columna ‘ssn’ contiene valores encriptados en lugar de los datos sensibles originales.
La salida del código debería ser la siguiente:
index name age ssn salary department 0 Tim Hernandez 37 6d528… 144118.53 Marketing 1 Jeff Jones 29 5787e… 73994.32 IT 2 Nathan Watts 64 86975… 45936.64 Sales …
Aplicación de Técnicas de Enmascaramiento Después de la Creación del Dataframe
Este método implica buscar y enmascarar datos sensibles dentro de un dataframe existente. Es útil cuando necesitas trabajar inicialmente con los datos originales pero deseas protegerlos antes de compartir o almacenar los resultados.
Ejemplo: Enmascarar Columnas de un Dataframe Existente
He aquí un ejemplo de cómo enmascarar columnas específicas en un dataframe existente:
import pandas as pd
import numpy as np
# Crear un dataframe de muestra
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'ssn': ['123-45-6789', '987-65-4321', '456-78-9012']
})
# Función para enmascarar SSN
def mask_ssn(ssn):
return 'XXX-XX-' + ssn[-4:]
# Aplicar enmascaramiento a la columna 'ssn'
df['ssn'] = df['ssn'].apply(mask_ssn)
print(df)Este script crea un dataframe de muestra y luego aplica una función de enmascaramiento personalizada a la columna ‘ssn’. El resultado es un dataframe donde solo los últimos cuatro dígitos del SSN son visibles, mientras que el resto está enmascarado con caracteres ‘X’.
La salida es la siguiente:
name age ssn 0 Alice 25 XXX-XX-6789 1 Bob 30 XXX-XX-4321 2 Charlie 35 XXX-XX-9012
Técnicas Avanzadas de Enmascaramiento para Dataframes
A medida que profundizamos en la protección de datos en dataframes, es importante explorar técnicas de enmascaramiento más sofisticadas que se pueden aplicar a varios tipos de datos y escenarios.
Enmascaramiento de Datos Numéricos
Cuando se trata de datos numéricos, preservar las propiedades estadísticas mientras se enmascaran puede ser crucial. He aquí un ejemplo de cómo agregar ruido a los datos numéricos mientras se mantiene su media y desviación estándar:
import pandas as pd
import numpy as np
# Crear un dataframe de muestra con datos numéricos
df = pd.DataFrame({
'id': range(1, 1001),
'salary': np.random.normal(50000, 10000, 1000)
})
# Función para agregar ruido mientras se preserva la media y la desviación estándar
def add_noise(column, noise_level=0.1):
noise = np.random.normal(0, column.std() * noise_level, len(column))
return column + noise
# Aplicar ruido a la columna de salario
df['masked_salary'] = add_noise(df['salary'])
print("Estadísticas de salario original:")
print(df['salary'].describe())
print("\nEstadísticas de salario enmascarado:")
print(df['masked_salary'].describe())Este script crea un dataframe de muestra con datos de salario y luego aplica una función que agrega ruido para enmascarar los salarios. Los datos enmascarados resultantes mantienen propiedades estadísticas similares a las originales, haciéndolos útiles para el análisis mientras se protegen los valores individuales.
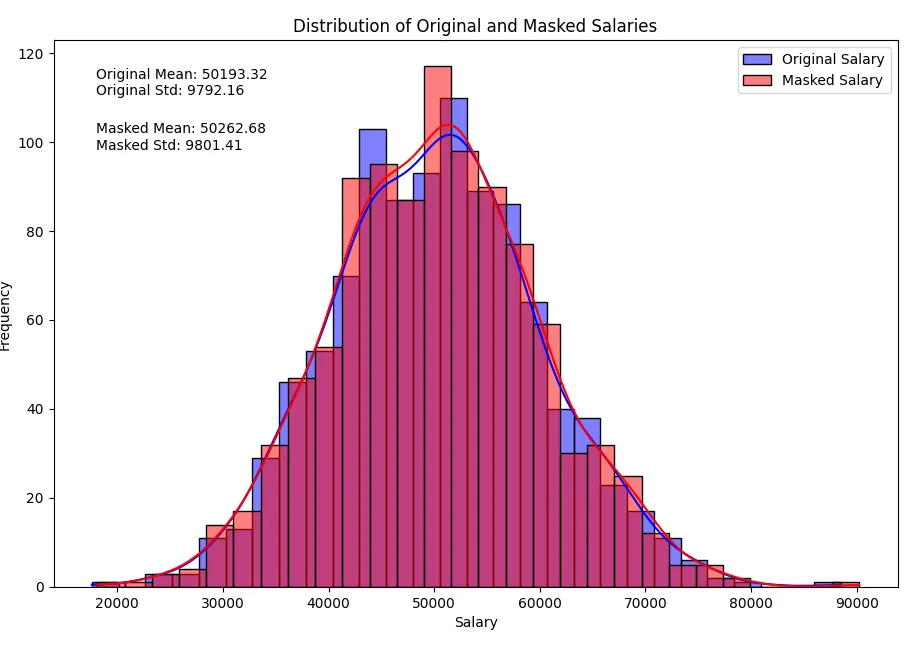
Nota que no hay grandes cambios en los parámetros estadísticos mientras los datos sensibles están preservados debido a que el ruido se añade a los datos.
Estadísticas de salario original: count 1000.000000 mean 49844.607421 std 9941.941468 min 18715.835478 25% 43327.385866 50% 49846.432943 75% 56462.098573 max 85107.367406 Name: salary, dtype: float64 Estadísticas de salario enmascarado: count 1000.000000 mean 49831.697951 std 10035.846618 min 17616.814547 25% 43129.152589 50% 49558.566315 75% 56587.690976 max 83885.686201 Name: masked_salary, dtype: float64
Las distribuciones normales se ven así ahora:
Enmascaramiento de Datos Categóricos
Para datos categóricos, podríamos querer preservar la distribución de categorías mientras enmascaramos valores individuales. Aquí hay un enfoque usando mapeo de valores:
import pandas as pd
import numpy as np
# Crear un dataframe de muestra con datos categóricos
df = pd.DataFrame({
'id': range(1, 1001),
'department': np.random.choice(['HR', 'IT', 'Sales', 'Marketing'], 1000)
})
# Crear un diccionario de mapeo
dept_mapping = {
'HR': 'Dept A',
'IT': 'Dept B',
'Sales': 'Dept C',
'Marketing': 'Dept D'
}
# Aplicar mapeo para enmascarar nombres de departamentos
df['masked_department'] = df['department'].map(dept_mapping)
print(df.head())
print("\nDistribución original de departamentos:")
print(df['department'].value_counts(normalize=True))
print("\nDistribución de departamentos enmascarados:")
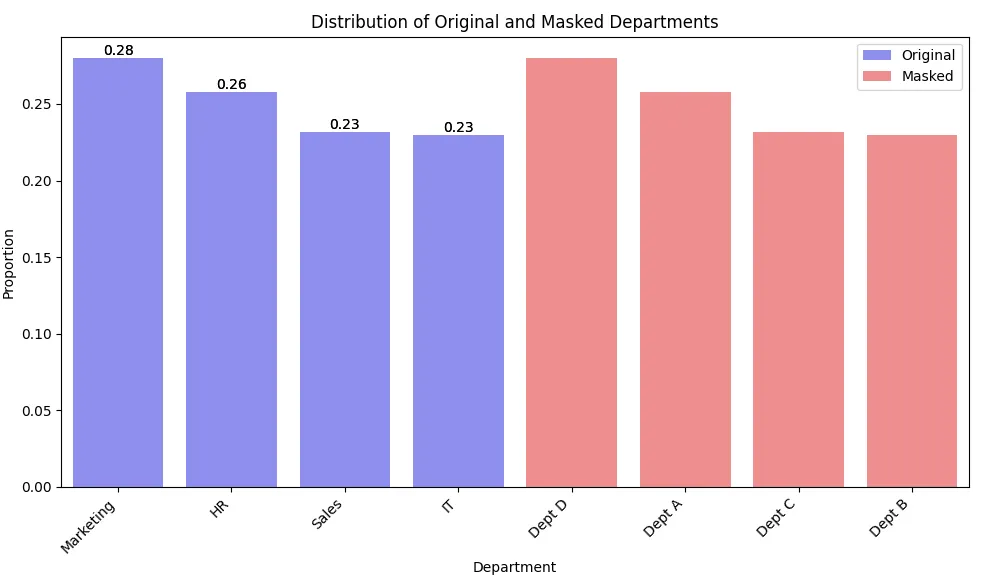
print(df['masked_department'].value_counts(normalize=True))Este ejemplo demuestra cómo enmascarar datos categóricos (nombres de departamentos) mientras se mantiene la distribución original de categorías.
Si graficamos los datos, se puede ver como sigue. Nota que las longitudes de las barras son las mismas para los datos enmascarados y no enmascarados, mientras que las etiquetas son diferentes.
Desafíos en la Protección de Datos en Dataframes
Si bien los procedimientos de enmascaramiento ofrecen herramientas poderosas para proteger datos sensibles en dataframes, vienen con su propio conjunto de desafíos:
- Mantener la Utilidad de los Datos: Lograr el equilibrio correcto entre la protección de datos y la utilidad para el análisis puede ser complicado.
- Consistencia entre Conjuntos de Datos: Asegurar que los valores enmascarados sean consistentes entre múltiples dataframes relacionados o tablas de bases de datos es crucial para mantener la integridad de los datos.
- Impacto en el Rendimiento: Algunas técnicas de enmascaramiento pueden ser computacionalmente costosas, especialmente para conjuntos de datos grandes.
- Reversibilidad: En algunos casos, puede ser necesario desenmascarar los datos, lo que requiere una gestión cuidadosa de las claves o algoritmos de enmascaramiento.
Mejores Prácticas de Enmascaramiento de Datos en Ciencia de Datos
Para abordar estos desafíos y asegurar un enmascaramiento efectivo de datos en dataframes, considera las siguientes mejores prácticas:
- Entiende tus Datos: Antes de aplicar cualquier técnica de enmascaramiento, analiza a fondo tus datos para comprender su estructura, relaciones y niveles de sensibilidad.
- Elige Técnicas Apropiadas: Selecciona métodos de enmascaramiento que sean adecuados para tus tipos de datos específicos y requisitos de análisis.
- Preserva la Integridad Referencial: Al enmascarar conjuntos de datos relacionados, asegúrate de que los valores enmascarados mantengan las relaciones necesarias entre tablas o dataframes.
- Auditorías Regulares: Revisa y actualiza periódicamente tus procedimientos de enmascaramiento para asegurarte de que cumplen con los estándares y regulaciones de protección de datos en evolución.
- Documenta tu Proceso: Mantén una documentación clara de tus procedimientos de enmascaramiento para fines de cumplimiento y resolución de problemas.
Conclusión
El enmascaramiento debería preservar la propiedad de los datos de producir conocimientos basados en datos. El enmascaramiento de datos en dataframes es un aspecto crítico de la ciencia de datos moderna, equilibrando la necesidad de un análisis perspicaz con la imperativa de la protección de datos. Comprendiendo las diversas técnicas de enmascaramiento y aplicándolas juiciosamente, los científicos de datos pueden trabajar con información sensible mientras mantienen la privacidad y el cumplimiento.
Como hemos explorado, hay dos enfoques para enmascarar datos en dataframes, cada uno con sus propias fortalezas y consideraciones. Ya sea que estés enmascarando datos durante la importación o aplicando técnicas a dataframes existentes, la clave es elegir métodos que preserven la utilidad de tus datos mientras protegen efectivamente la información sensible.
Recuerda, la protección de datos es un proceso continuo. A medida que las técnicas de ciencia de datos evolucionan y surgen nuevos desafíos de privacidad, mantenerse informado y adaptable en tu enfoque para la protección de datos en dataframes será crucial.
