
Prueba de Cuello de Botella de Datos

La eficiencia del procesamiento y transferencia de datos es crucial para un rendimiento óptimo del sistema. Una prueba de cuello de botella de datos es una herramienta esencial para identificar y abordar las limitaciones de rendimiento en varios entornos informáticos. Este artículo profundizará en los fundamentos de las pruebas de cuello de botella de datos y explorará métodos para obtener datos de prueba adecuados.
Mientras que el mercado ofrece una gran cantidad de herramientas para la prueba de cuellos de botella en bases de datos y aplicaciones, muchas de estas soluciones requieren una amplia experiencia para implementar eficazmente. Sin embargo, DataSunrise se destaca al proporcionar una plataforma poderosa pero fácil de usar que simplifica el complejo proceso de pruebas de cuello de botella de datos.
Por Qué Importan las Pruebas de Cuello de Botella de Datos
Imagina que estás tratando de verter agua a través de un embudo. El flujo de agua es suave hasta que alcanza la parte estrecha del embudo, donde se ralentiza. Esto es similar a cómo funcionan los cuellos de botella de datos en los sistemas informáticos. Los cuellos de botella de datos pueden afectar significativamente el rendimiento del sistema, llevando a tiempos de procesamiento más lentos y una eficiencia reducida.
Las pruebas de cuello de botella de datos encuentran los puntos débiles del sistema, para que puedas mejorar el rendimiento y la eficiencia. Ya seas un desarrollador de software, administrador de bases de datos o profesional de TI, entender y realizar pruebas de cuello de botella de datos es crucial para mantener sistemas de alto rendimiento.
Entendiendo los Cuellos de Botella de Datos
¿Qué es un Cuello de Botella de Datos?
Un cuello de botella de datos ocurre cuando el flujo de datos en un sistema está restringido, lo que lleva a retrasos y a un rendimiento reducido. Estas restricciones pueden ocurrir en varios puntos: procesamiento de la CPU, acceso a la memoria, E/S de almacenamiento, transmisión de red.
El Impacto de los Cuellos de Botella de Datos
Los cuellos de botella de datos pueden tener consecuencias de gran alcance: tiempos de respuesta de aplicación más lentos, reducción del rendimiento del sistema, aumento en la utilización de recursos, mala experiencia de usuario.
Al identificar y abordar estos cuellos de botella, puedes mejorar significativamente el rendimiento y la fiabilidad de tu sistema.
Realizando una Prueba de Cuello de Botella de Datos
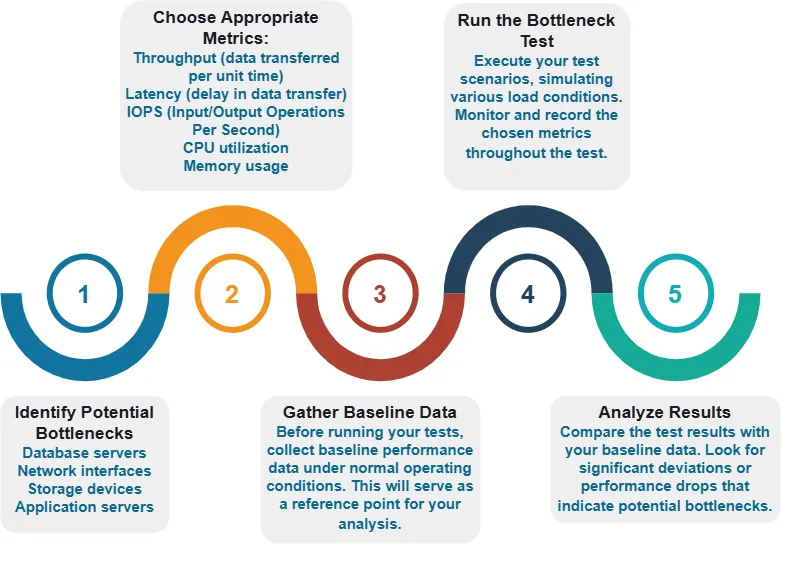
Obtención de Datos de Prueba para las Pruebas de Cuello de Botella
Uno de los desafíos de realizar pruebas de cuello de botella de datos es obtener datos de prueba adecuados. Vamos a explorar algunos métodos para adquirir o generar datos de prueba.
Usando Datos de Producción (con Precaución)
Si bien utilizar datos de producción reales puede proporcionar los resultados más precisos, conlleva riesgos significativos:
- Preocupaciones de privacidad
- Problemas de cumplimiento normativo
- Posibilidad de filtraciones de datos
Si decides usar datos de producción, asegúrate de tener la autorización adecuada e implementar medidas de seguridad robustas.
Generación de Datos Sintéticos
DataSunrise se destaca como líder en soluciones de seguridad de bases de datos y gestión de datos, ofreciendo capacidades avanzadas de generación de datos sintéticos para una amplia gama de bases de datos y almacenes de datos. Nuestras herramientas avanzadas agilizan significativamente el proceso de generación de datos de prueba de alta calidad, ahorrando a las organizaciones tiempo y recursos valiosos.
Con soporte para docenas de plataformas de bases de datos populares, DataSunrise ofrece una flexibilidad y eficiencia sin igual en la creación de conjuntos de datos de prueba realistas y conformes con la privacidad. Esto lo convierte en un activo invaluable para las empresas que buscan realizar pruebas exhaustivas de cuellos de botella de datos sin comprometer información sensible.
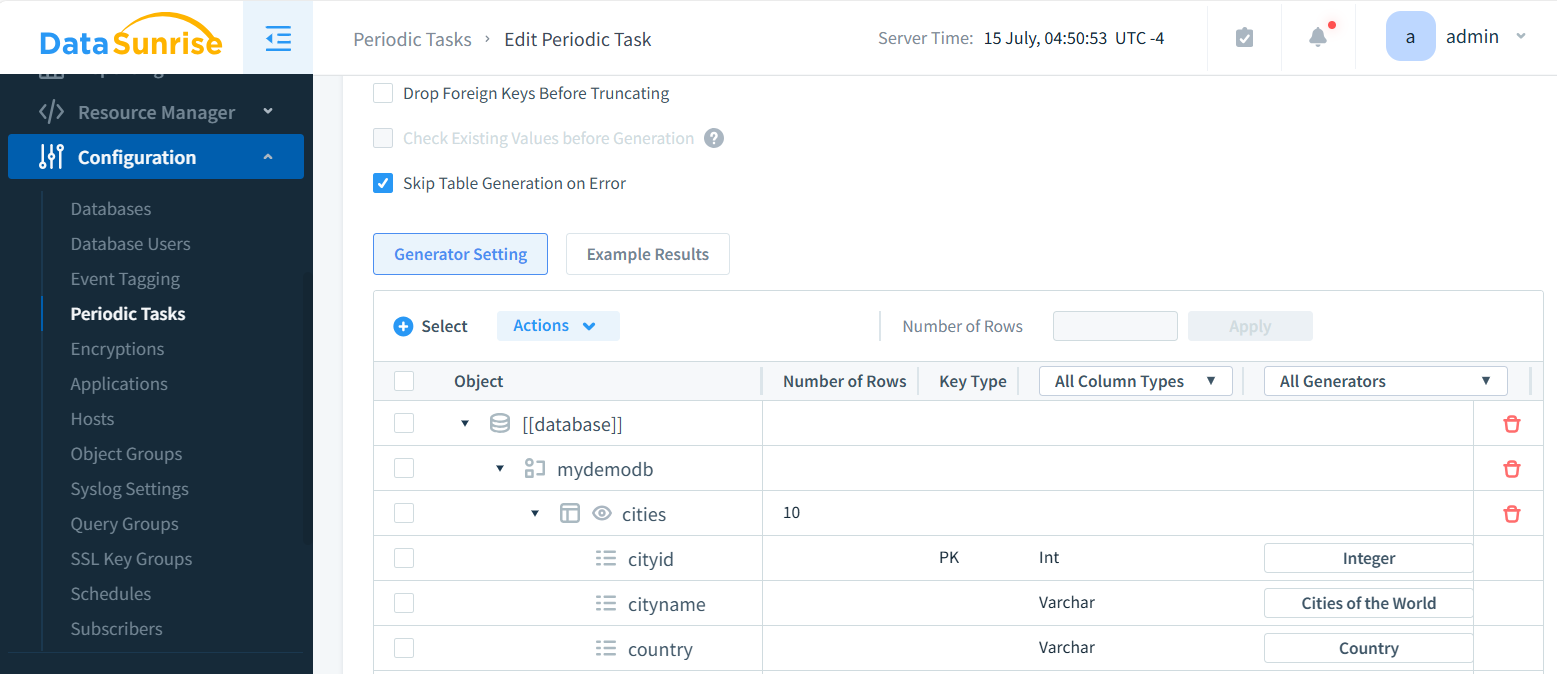
Los datos sintéticos ofrecen una alternativa segura a los datos de producción. Imitan artificialmente las características de los datos reales sin exponer información sensible.
Beneficios de los Datos Sintéticos:
- Sin riesgos de privacidad
- Personalizables para escenarios de prueba específicos
- Escalables a grandes volúmenes
Métodos para Generar Datos Sintéticos:
- Generación de Datos Aleatorios: Crear datos usando generadores de números aleatorios y reglas predefinidas.
- Generación Basada en Patrones: Generar datos que sigan patrones específicos o distribuciones observadas en los datos reales.
- Generación Basada en Modelos: Usar modelos de aprendizaje automático para crear datos que se asemejen estrechamente a conjuntos de datos del mundo real.
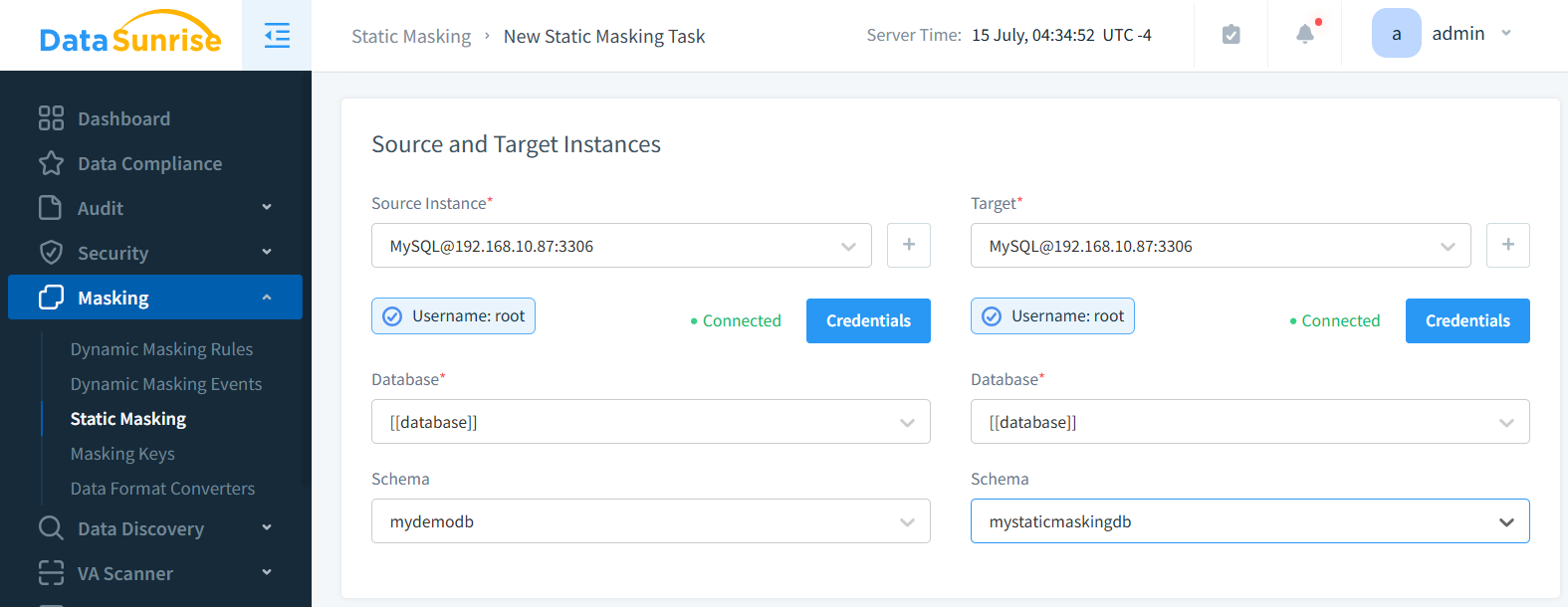
Enmascaramiento de Datos
El enmascaramiento de datos implica modificar información sensible en un conjunto de datos mientras se mantiene su formato y propiedades estadísticas. Este método permite utilizar datos similares a los de producción sin exponer información confidencial.
La solución de enmascaramiento de datos de DataSunrise se destaca como una herramienta poderosa y versátil en el ámbito de la privacidad y seguridad de datos. Esta implementación rica en funciones ofrece a las organizaciones una forma robusta de proteger información sensible mientras se mantiene la utilidad de los datos para pruebas, desarrollo y análisis.
Técnicas Comunes de Enmascaramiento de Datos:
- Sustitución: Reemplaza valores sensibles con alternativas ficticias pero realistas.
- Mezcla: Reorganiza datos dentro de una columna para romper la asociación entre registros.
- Encriptación: Transforma los datos usando algoritmos de encriptación.
Conjuntos de Datos de Código Abierto
Muchas organizaciones e instituciones proporcionan conjuntos de datos de código abierto que pueden ser utilizados para propósitos de prueba. Estos conjuntos de datos a menudo provienen de escenarios del mundo real pero han sido anonimizados y autorizados para uso público.
Fuentes de Conjuntos de Datos de Código Abierto:
- Portales de datos gubernamentales
- Repositorios de investigación académica
- Plataformas de competencia de ciencia de datos (por ejemplo, Kaggle)
Creación de Datos de Prueba Personalizados
Usando Python y la biblioteca Faker library, puede generar fácilmente datos aleatorios con llamadas a funciones como estas:
fake.name()
fake.email()
Puedes encontrar algunos ejemplos sobre generación de datos en nuestros artículos sobre datos sintéticos y generadores de datos AI.
Mejores Prácticas para las Pruebas de Cuello de Botella de Datos
Para garantizar la efectividad de tus pruebas de cuello de botella de datos, considera estas mejores prácticas:
- Comienza en Pequeño: Empieza con escenarios de prueba simples y aumenta gradualmente la complejidad.
- Aísla Componentes: Prueba componentes individuales del sistema antes de realizar pruebas de extremo a extremo.
- Usa Volúmenes de Datos Realistas: Asegúrate de que tus datos de prueba reflejen patrones de uso del mundo real.
- Monitorea la Utilización de Recursos: Mantén un ojo en el uso de la CPU, la memoria y la E/S durante las pruebas.
- Repite Pruebas: Realiza múltiples iteraciones para contar con la variabilidad y confirmar los resultados.
- Documenta Todo: Mantén registros detallados de las configuraciones de las pruebas, resultados y observaciones.
Herramientas para las Pruebas de Cuello de Botella de Datos y DataSunrise
Varias herramientas pueden ayudar en la realización de pruebas de cuello de botella de datos:
- Apache JMeter: Herramienta de código abierto para pruebas de carga y medición de rendimiento.
- Gatling: Herramienta de pruebas de carga basada en Scala para analizar y medir el rendimiento del sistema.
- Locust: Herramienta basada en Python para pruebas de carga distribuidas.
- iperf3: Herramienta de medición de rendimiento de red.
Solución DataSunrise
Las ventajas clave del enfoque de DataSunrise sobre las pruebas de cuello de botella incluyen:
- Interfaz Intuitiva: Diseñada con la experiencia del usuario en mente, permitiendo que incluso los no expertos configuren y ejecuten pruebas sofisticadas.
- Altamente Personalizable: Ofrece una amplia gama de parámetros y escenarios que pueden ajustarse fácilmente para cumplir con requisitos de prueba específicos.
- Cobertura Integral: Capaz de probar varios aspectos del rendimiento de la base de datos, desde la ejecución de consultas hasta las tasas de transferencia de datos.
- Generación Automática de Pruebas: Crea inteligentemente escenarios de prueba basados en patrones reales de uso de la base de datos, reduciendo el tiempo de configuración manual.
- Monitoreo en Tiempo Real: Proporciona información en vivo durante la ejecución de la prueba, permitiendo la identificación inmediata de cuellos de botella.
- Informes Detallados: Genera informes profundos y fáciles de entender que destacan problemas de rendimiento y sugieren optimizaciones.
- Capacidades de Integración: Funciona perfectamente con varios sistemas de bases de datos y puede integrarse en los flujos de trabajo de desarrollo y prueba existentes.
- Escalabilidad: Maneja pruebas para bases de datos de todos los tamaños, desde aplicaciones pequeñas hasta grandes sistemas empresariales.
Interpretando los Resultados de las Pruebas
Después de realizar tus pruebas de cuello de botella de datos, un análisis cuidadoso es crucial. Busca:
- Picos inesperados en la utilización de recursos
- Degradación constante del rendimiento bajo condiciones específicas
- Diferencias entre componentes que deberían tener un rendimiento similar
Recuerda, el objetivo no es solo identificar cuellos de botella, sino entender sus causas fundamentales y desarrollar soluciones efectivas.
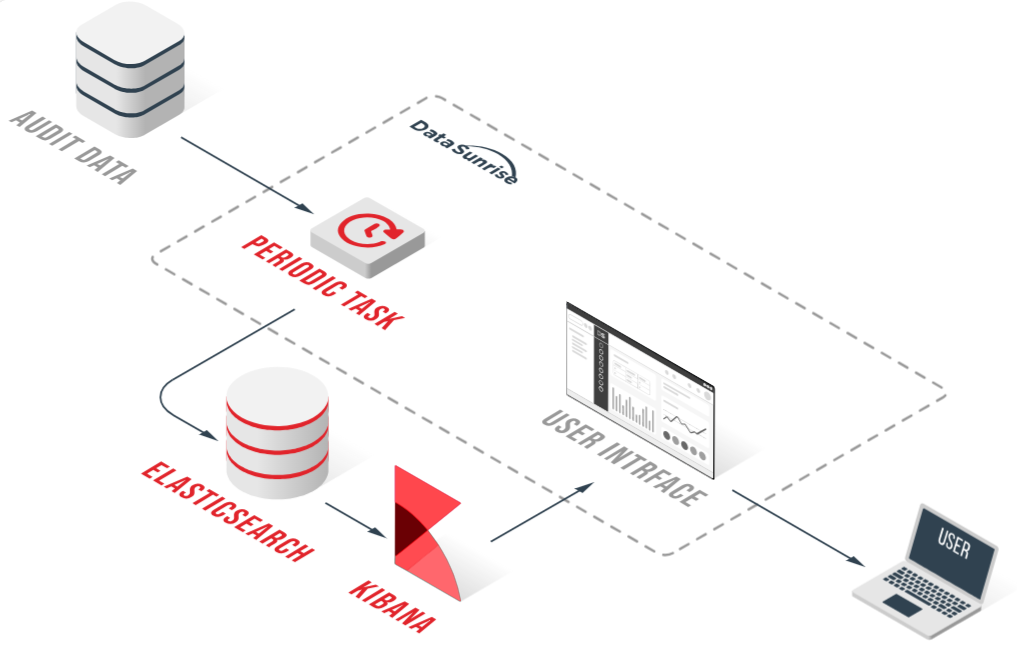
Al aprovechar la integración de auditoría de DataSunrise, las organizaciones pueden obtener información profunda y práctica sobre el rendimiento de su base de datos, permitiendo una optimización proactiva e identificación eficiente de cuellos de botella.
Conclusión
Las pruebas de cuello de botella de datos son herramientas invaluables para optimizar el rendimiento del sistema. Aprende los conceptos básicos de las pruebas y encuentra los datos adecuados para identificar y solucionar eficazmente los problemas de rendimiento en tus sistemas. Al realizar pruebas, asegúrate de que los datos reflejen con precisión las situaciones de la vida real y se mantengan seguros.
Puedes usar datos sintéticos, datos de producción enmascarados o conjuntos de datos generados personalizados para este propósito. Puedes usar datos sintéticos, datos de producción enmascarados o conjuntos de datos generados personalizados para este propósito.
Al embarcarte en tu viaje de pruebas de cuello de botella de datos, recuerda que es un proceso iterativo. Las pruebas y optimizaciones continuas te ayudarán a mantener un rendimiento óptimo del sistema frente a las demandas evolucionadas de procesamiento de datos.
Para aquellos que buscan herramientas flexibles y fáciles de usar para la seguridad de bases de datos, incluyendo capacidades altamente útiles de datos sintéticos y enmascaramiento de datos, considera explorar las ofertas de DataSunrise. Nuestra suite integral de herramientas puede simplificar enormemente el proceso de generación y gestión de datos de prueba para tus pruebas de cuello de botella mientras asegura la privacidad y el cumplimiento de datos. Visita el sitio web de DataSunrise para ver una demostración. También puedes aprender cómo nuestras soluciones pueden ayudarte con la gestión y prueba de datos.
