
¿Qué es un archivo CSV?
Introducción: El humilde archivo CSV
¿Sabías que los archivos CSV existen desde los primeros días de la informática? En los años 70 y principios de los 80, el lenguaje Fortran 77 de IBM introdujo el tipo de datos de caracteres, lo que permitió el soporte de entrada y salida separada por comas. Estos archivos, simples pero potentes, han resistido la prueba del tiempo y siguen siendo una opción popular para el intercambio de datos incluso en nuestro mundo moderno impulsado por la tecnología. Sumérgete en el mundo de los archivos separados por comas y descubre por qué continúan siendo un formato preferido tanto para profesionales de datos como para usuarios ocasionales.
Anteriormente describimos las capacidades de DataSunrise para manejar datos semiestructurados en archivos JSON. Consulta esa información para conocer más sobre las características de seguridad de datos de DataSunrise.
Con DataSunrise puedes enmascarar y descubrir datos sensibles en archivos CSV almacenados localmente o en almacenamiento S3. A continuación, un ejemplo de enmascaramiento.
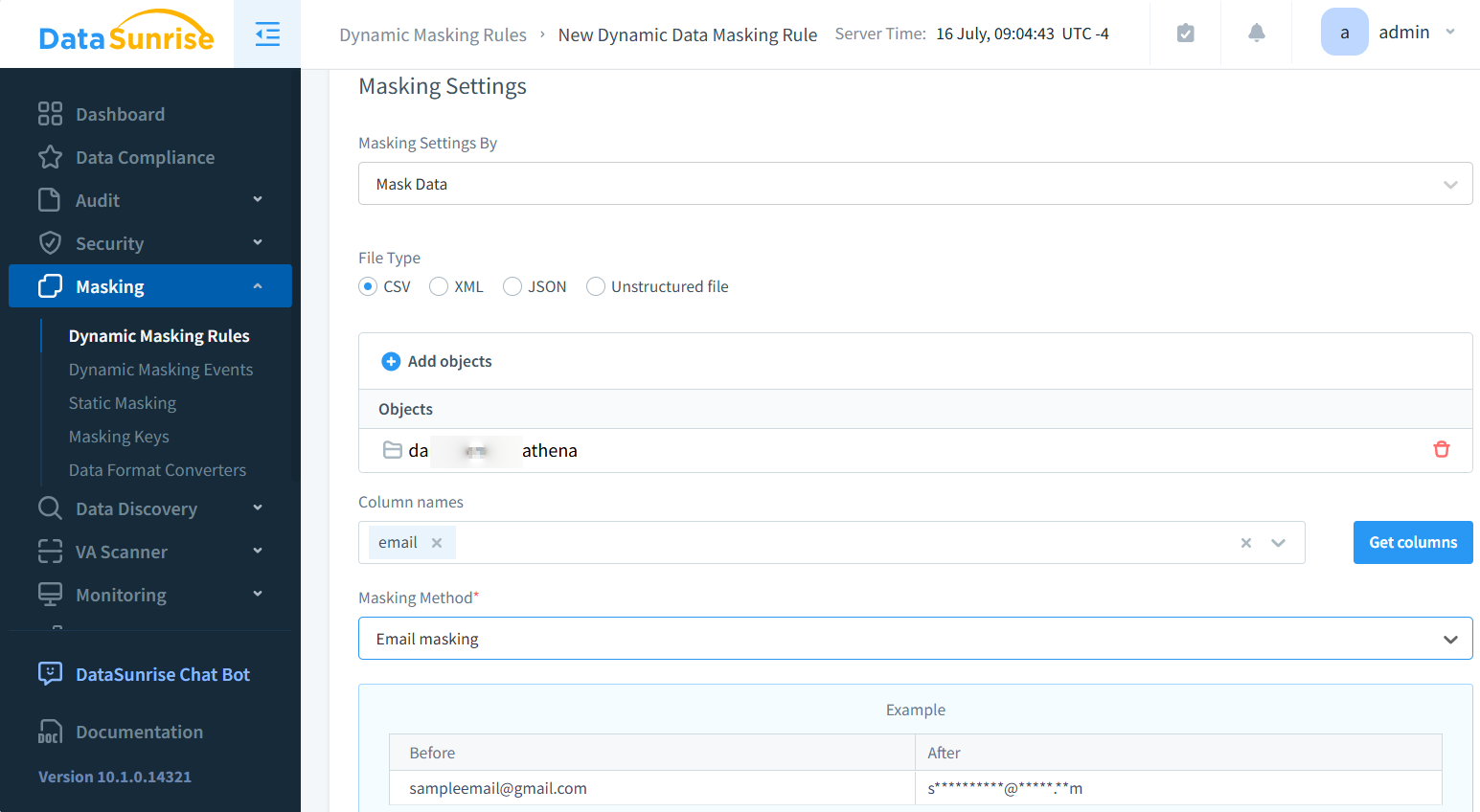
Después de una configuración simple, puedes acceder (descargar) los archivos CSV enmascarados a través del proxy S3 de DataSunrise usando software especializado como S3Browser. Se requiere una configuración adecuada de los ajustes del proxy en el software cliente. El resultado es el siguiente:

En el vasto panorama de formatos de archivo, el CSV destaca por su simplicidad y versatilidad. CSV, abreviatura de Valores Separados por Comas, es un tipo de archivo de texto plano que almacena datos tabulares. Cada línea en el archivo representa una fila de datos, con comas separando valores individuales. Esta estructura sencilla hace que tales archivos sean fáciles de crear, leer y manipular en varias plataformas y aplicaciones.
¿Por qué usar archivos CSV?
Los archivos CSV ofrecen varias ventajas que contribuyen a su uso generalizado:
- Simplicidad: El formato es fácil de entender y trabajar, incluso para usuarios no técnicos. Puedes abrirlo en el Bloc de notas o Notepad++ (cualquier editor de texto).
- Compatibilidad: Los archivos pueden abrirse y editarse con una amplia gama de software, desde aplicaciones de hojas de cálculo hasta editores de texto.
- Intercambio de datos: Sirven como un formato universal para transferir datos entre diferentes sistemas y aplicaciones.
- Eficiencia de tamaño: Los archivos suelen ser más pequeños que sus contrapartes binarias, lo que los hace ideales para almacenar y transmitir grandes conjuntos de datos.
A continuación, una tabla comparativa de formatos de datos utilizados en Big Data y Machine Learning, destacando el papel de los archivos separados por comas en el procesamiento de datos.
| Formato | Big Data | Machine Learning | Pros | Contras |
|---|---|---|---|---|
| CSV | Común para intercambio de datos, menos común para almacenamiento | A menudo usado para conjuntos de datos pequeños a medianos | Simple, legible para humanos, ampliamente soportado | No eficiente para grandes conjuntos de datos, sin aplicación de esquemas |
| Parquet | Muy común para almacenamiento y procesamiento | Bueno para grandes conjuntos de datos y almacenes de características | Almacenamiento columnar, compresión eficiente | No legible para humanos, requiere herramientas especiales para visualizar |
| Avro | Común para serialización de datos | Menos común, pero usado en algunas canalizaciones | Evolución de esquemas, formato binario compacto | Más complejo que CSV, no tan eficiente como Parquet para análisis |
| JSON | Común para APIs y almacenes de documentos | Usado para almacenar metadatos y pequeños conjuntos de datos | Flexible, legible para humanos, ampliamente soportado | Almacenamiento menos eficiente que formatos binarios |
| TFRecord | No comúnmente usado | Específico de TensorFlow, común en canalizaciones de ML | Eficiente para grandes conjuntos de datos, bueno con TensorFlow | No ampliamente soportado fuera del ecosistema de TensorFlow |
Ejemplo de CSV
Veamos un simple ejemplo de CSV para ilustrar su estructura:
Nombre, Edad, Ciudad Juan Pérez, 30, Nueva York Ana Gómez, 25, Londres Carlos Sánchez, 35, París
Este ejemplo muestra cómo los datos están organizados en un archivo CSV, con cada línea representando un registro y comas separando los valores.
Trabajando con archivos CSV en Python
Python proporciona herramientas integradas para manejar archivos CSV, lo que lo hace una elección popular para tareas de procesamiento de datos. Exploremos cómo trabajar con archivos CSV usando Python básico y la potente biblioteca pandas.
Usando Python básico
El módulo csv de Python ofrece métodos sencillos para leer y escribir archivos CSV. Aquí hay un ejemplo básico:
import csv
# Leyendo un archivo
with open('datos.csv', 'r') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
# Escribiendo en un archivo
with open('salida.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['Nombre', 'Edad', 'Ciudad'])
csv_writer.writerow(['Ana', '28', Berlín])Este código demuestra cómo leer y escribir archivos CSV usando el módulo csv integrado en Python.
Usando Pandas
Para una manipulación de datos más avanzada, la biblioteca pandas es una excelente opción. Proporciona herramientas poderosas para trabajar con datos semiestructurados, incluidos archivos CSV:
import pandas as pd
# Leyendo un archivo
df = pd.read_csv('datos.csv')
# Mostrando las primeras filas
print(df.head())
# Escribiendo en un archivo
df.to_csv('salida.csv', index=False)Pandas facilita realizar operaciones complejas en datos CSV, como filtrado, clasificación y agregación. Puedes guardar fácilmente los datos nuevamente en CSV más tarde.
Los pros y contras de los archivos separados por comas
Aunque los archivos CSV son ampliamente utilizados, es importante entender sus fortalezas y limitaciones:
Ventajas
- Legible por humanos: Los archivos separados por comas pueden ser fácilmente vistos y editados en editores de texto.
- Ligeros: Tienen un tamaño de archivo pequeño en comparación con muchos otros formatos.
- Ampliamente soportados: La mayoría de las herramientas de procesamiento de datos y lenguajes de programación pueden trabajar con archivos CSV.
Desventajas
- Tipos de datos limitados: Los archivos de texto no soportan de manera inherente tipos de datos o estructuras complejas.
- Sin estandarización: No existe un estándar oficial para los archivos CSV, lo que puede llevar a problemas de compatibilidad. No hay columnas requeridas ni delimitadores obligatorios.
- Integridad de los datos: Los archivos separados por comas no tienen mecanismos integrados de verificación de errores o validación de datos. Los formatos de Big Data (como Parquet) incluyen sumas de verificación integradas para bloques de datos.
Formatos binarios: cuándo y por qué son mejores
Aunque los archivos CSV sobresalen en muchos escenarios, los formatos binarios pueden ser ventajosos en ciertas situaciones:
- Rendimiento: Los formatos binarios a menudo son más rápidos de leer y escribir, especialmente para grandes conjuntos de datos.
- Tipos de datos: Pueden preservar más exactamente los tipos y estructuras de datos complejos.
- Compresión: Los formatos binarios típicamente ofrecen mejores ratios de compresión, ahorrando espacio de almacenamiento.
- Seguridad: Algunos formatos binarios proporcionan opciones para cifrado y control de acceso.
Ejemplos de formatos binarios incluyen HDF5, Parquet y Avro. Estos formatos son particularmente útiles en entornos de big data donde el rendimiento y la integridad de los datos son cruciales.
Archivos CSV en el intercambio de datos
Los archivos CSV juegan un papel vital en el intercambio de datos a través de diversas industrias y aplicaciones:
- Inteligencia empresarial: Las empresas a menudo usan archivos de texto para transferir datos entre diferentes herramientas de BI y bases de datos.
- Investigación científica: Los investigadores frecuentemente comparten conjuntos de datos en este formato para análisis fácil y colaboración.
- Aplicaciones web: Muchos servicios web permiten a los usuarios exportar datos en formato separado por comas para análisis fuera de línea o propósitos de respaldo.
- Datos de IoT y sensores: Los archivos de texto separados por comas se usan comúnmente para registrar y transmitir datos de dispositivos IoT y sensores.
La simplicidad y naturaleza universal de los archivos de texto los convierten en una opción ideal para estos escenarios de intercambio de datos.
Campo de Big Data
Los archivos de Valores Separados por Comas tienen una relación algo compleja con el Big Data. Déjame desglosarlo para ti:
- Popularidad en ciertos contextos:
- El formato de archivo separado por comas todavía es ampliamente usado para intercambio de datos y como formato intermedio en ecosistemas de Big Data.
- A menudo se usa para importar datos en sistemas de Big Data o exportar resultados para análisis adicional.
- Limitaciones para Big Data:
- Los archivos CSV no se comprimen bien, lo cual puede ser un problema cuando se trata de conjuntos de datos muy grandes.
- No tienen definiciones de esquema integradas, lo que puede llevar a inconsistencias de datos en operaciones a gran escala.
- El análisis de grandes archivos de texto puede ser más lento en comparación con algunos formatos binarios.
- Alternativas preferidas:
- Para operaciones de Big Data, a menudo se prefieren formatos como Parquet, Avro o ORC.
- Estos formatos ofrecen mejor compresión, evolución de esquema y velocidades de procesamiento más rápidas.
- Casos de uso donde los archivos separados por comas siguen siendo relevantes:
- Ingesta de datos: Muchos sistemas aún aceptan valores separados por comas como un formato de entrada.
- Sistemas heredados: Algunos sistemas más antiguos pueden seguir dependiendo de estos archivos para el intercambio de datos.
- Conjuntos de datos simples: Para conjuntos de datos más pequeños o menos complejos dentro de un ecosistema de Big Data, aún pueden usarse archivos CSV.
- Enfoques híbridos:
- Algunos flujos de trabajo de Big Data pueden usar CSV para la ingestión inicial de datos o la salida final, mientras usan formatos más optimizados para pasos de procesamiento intermedios.
Conclusión: El valor perdurable de los archivos CSV
Los archivos CSV continúan siendo una herramienta valiosa en el kit de herramientas del profesional de datos. Su simplicidad, versatilidad y soporte generalizado los convierten en una excelente opción para muchos escenarios de intercambio y almacenamiento de datos. Mientras que los formatos binarios ofrecen ventajas en ciertas situaciones, el humilde archivo de texto sigue siendo una solución preferida para el intercambio de datos rápido y fácil a través de plataformas y aplicaciones.
Como hemos explorado, trabajar con archivos separados por comas en Python es sencillo
