
Mejorando la Gestión y el Rendimiento de los Datos con la Segmentación de Datos
Introducción
La explosión de tecnologías digitales, dispositivos del Internet de las Cosas (IoT) e interacciones en línea ha creado vastas cantidades de datos que pueden recogerse y analizarse. En el mundo de hoy, impulsado por los datos, gestionar grandes conjuntos de datos de manera eficiente es crucial tanto para empresas como para investigadores. Una técnica poderosa que ha ganado prominencia en los últimos años es la segmentación de datos. Este artículo se adentrará profundamente en el mundo de la segmentación de datos, explorando sus fundamentos, beneficios y aplicaciones prácticas. También abordaremos algunas herramientas de código abierto y proporcionaremos ejemplos para ayudarle a comenzar con esta esencial técnica de gestión de datos.
¿Qué es la Segmentación de Datos?
La segmentación de datos es el proceso de crear una porción más pequeña y manejable de un conjunto de datos más grande, preservando sus características y relaciones clave. Esta técnica permite a los usuarios trabajar con una muestra representativa de datos, facilitando su manejo, análisis y prueba sin comprometer la integridad del conjunto de datos original.
¿Por Qué Debería Interesarse por la Segmentación?
La segmentación de datos es cada vez más crucial en nuestra era de grandes datos. Aquí le presentamos algunas razones por las que debería prestar atención a esta técnica:
- Manejo de Conjuntos de Datos Masivos: Los conjuntos de datos modernos pueden ser enormes. Por ejemplo, una plataforma de redes sociales podría generar petabytes de datos diariamente. Trabajar con tal cantidad de datos puede ser impráctico o imposible sin segmentación.
- Optimización de Recursos: Procesar conjuntos de datos completos a menudo requiere una cantidad significativa de recursos computacionales. La segmentación permite trabajar solo con una fracción de los datos, ahorrando tiempo y reduciendo los requisitos de hardware.
- Reducción de Costos: Los costos de computación en la nube y almacenamiento están directamente ligados al volumen de datos. Al trabajar con subconjuntos de datos, puede reducir significativamente estos gastos.
- Ciclos de Desarrollo Más Rápidos (pruebas de software): En el desarrollo de software, usar los conjuntos de datos de producción completos para pruebas puede ralentizar el proceso de desarrollo. Los subconjuntos permiten iteraciones más rápidas y una identificación de errores más veloz.
- Cumplimiento de Privacidad de Datos: Con regulaciones como GDPR y CCPA, usar conjuntos de datos completos con información sensible para pruebas o análisis puede ser riesgoso. La segmentación ayuda a crear conjuntos de datos anonimizados y compatibles.
- Mejora de la Calidad de Datos: Los conjuntos de datos más pequeños son más fáciles de limpiar y validar, lo que potencialmente lleva a una mayor calidad de datos para sus análisis o modelos.
¿Qué Tan Grandes Pueden Ser los Conjuntos de Datos? Un Ejemplo del Mundo Real
Para entender la escala de los conjuntos de datos modernos, consideremos algunos ejemplos:
- El Almacén de Datos de Walmart: En 2019, se estimaba que el almacén de datos de Walmart contenía más de 2.5 petabytes de datos. Eso equivale a 167 veces todos los libros en la Biblioteca del Congreso de los EE. UU.
- Datos de Usuarios de Facebook: Facebook procesa más de 500 terabytes de datos diariamente. Esto incluye publicaciones de usuarios, fotos, videos y datos de interacción.
- Colisionador de Hadrones de CERN: El LHC genera enormes cantidades de datos equivalentes a más de 20,000 años de grabación continua en HD.
- Datos Genómicos: El genoma humano consta de aproximadamente 3 mil millones de pares de bases. Secuenciar y almacenar estos datos para millones de individuos crea conjuntos de datos en el rango de los petabytes.
- Ciencia del Clima: El Centro de Simulación Climática de la NASA (NCCS) gestiona más de 32 petabytes de datos de varias misiones científicas sobre la Tierra.
Para poner esto en perspectiva, 1 petabyte equivale a 20 millones de archivadores de cuatro cajones llenos de texto. Ahora imagine intentar analizar o procesar esta cantidad de datos en su totalidad; aquí es donde la segmentación de datos se vuelve invaluable.
Por ejemplo, si usted fuera un científico de datos en Walmart intentando analizar el comportamiento del cliente, trabajar con los 2.5 petabytes completos sería poco práctico. En cambio, podría crear un subconjunto de datos para un período específico, región o categoría de producto, reduciendo tal vez su conjunto de datos de trabajo a unos manejables 50 gigabytes.
¿Por Qué es Útil la Segmentación de Datos?
La segmentación de datos ofrece numerosas ventajas para los profesionales de datos y las organizaciones:
- Mejora del Rendimiento: Trabajar con conjuntos de datos más pequeños reduce el tiempo de procesamiento y los requisitos de recursos.
- Costo-Efectivo: La segmentación puede reducir los costos de almacenamiento y computación asociados con los grandes datos.
- Mejora en las Pruebas: Permite pruebas más rápidas y eficientes de aplicaciones basadas en datos.
- Cumplimiento de Privacidad: La segmentación ayuda a crear conjuntos de datos anonimizados para cumplir con la regulación.
- Análisis Simplificado: Los conjuntos de datos más pequeños son más fáciles de explorar y analizar, especialmente durante las etapas iniciales de un proyecto.
Aplicaciones Prácticas de la Segmentación
Exploremos algunos escenarios del mundo real donde la segmentación de datos resulta invaluable:
1. Desarrollo y Pruebas de Software
Los desarrolladores a menudo necesitan trabajar con datos realistas para probar aplicaciones. Sin embargo, usar conjuntos de datos de producción completos puede ser impráctico y riesgoso. La segmentación permite la creación de conjuntos de datos de prueba más pequeños y representativos que mantienen la complejidad de los datos del mundo real sin exponer información sensible.
2. Análisis y Exploración de Datos
Cuando se tratan grandes conjuntos de datos, el análisis exploratorio inicial de datos puede ser muy lento. Al crear un subconjunto, los analistas pueden obtener rápidamente información y probar hipótesis antes de escalar al conjunto de datos completo.
3. Desarrollo de Modelos de Aprendizaje Automático
Durante las etapas iniciales de desarrollo de modelos, los científicos de datos pueden usar subconjuntos para iterar rápidamente sobre diferentes algoritmos e hiperparámetros antes de entrenar con el conjunto de datos completo.
4. Optimización de Bases de Datos
Los administradores de bases de datos pueden usar la segmentación para crear versiones más pequeñas de las bases de datos de producción para los entornos de desarrollo y prueba, asegurando un rendimiento óptimo sin la sobrecarga de gestionar réplicas de tamaño completo.
Herramientas y Técnicas para la Segmentación de Datos
Ahora que entendemos la importancia de la segmentación de datos, veamos algunas herramientas y técnicas populares para implementarla de manera efectiva.
SQL para la Segmentación de Datos
SQL es un lenguaje poderoso para la manipulación de datos y es excelente para segmentar bases de datos relacionales. Aquí hay un ejemplo de cómo crear un subconjunto de datos usando SQL:
-- Crear un subconjunto de datos de clientes para el año 2023 CREATE TABLE customer_subset_2023 AS SELECT * FROM customers WHERE EXTRACT(YEAR FROM order_date) = 2023 LIMIT 10000;
Esta consulta crea una nueva tabla customer_subset_2023 que contiene hasta 10,000 registros de clientes del año 2023. El resultado es un conjunto de datos más pequeño y manejable para análisis o propósitos de prueba.
Python para la Segmentación de Datos
Con su rico ecosistema de bibliotecas de manipulación de datos, Python ofrece herramientas poderosas para la segmentación de datos.
Cuenta con un tipo de dato incorporado llamado ‘set’, que es útil para almacenar elementos únicos y realizar operaciones matemáticas de conjuntos. Sin embargo, aunque los sets son eficientes para ciertas tareas, no se utilizan típicamente para operaciones con grandes datos. Para manejar grandes conjuntos de datos en Python, se emplean más comúnmente bibliotecas especializadas como pandas, NumPy o PySpark debido a su rendimiento optimizado y capacidades avanzadas de manipulación de datos.
Veamos un ejemplo usando pandas:
import pandas as pd
import numpy as np
# Cargar el conjunto de datos completo
full_dataset = pd.read_csv('large_dataset.csv')
# Crear un subconjunto basado en una condición y muestreo aleatorio
subset = full_dataset[full_dataset['category'] == 'electronics'].sample(n=1000, random_state=42)
# Guardar el subconjunto en un nuevo archivo CSV
subset.to_csv('electronics_subset.csv', index=False)Este script carga un gran conjunto de datos, lo filtra para incluir solo artículos electrónicos, y luego selecciona aleatoriamente 1,000 filas para crear un subconjunto. El resultado se guarda como un nuevo archivo CSV.
También, en Pandas, puede filtrar datos con declaraciones como la siguiente:
filtered_df_loc = df.loc[df['age'] > 25, ['name', 'city']]
o
filtered_df = df[df['age'] > 25]
Filtrado de Datos Basado en Condiciones en R
R es otro lenguaje poderoso para la manipulación y análisis de datos, ampliamente utilizado en computación estadística y ciencia de datos. Mientras que Python es a menudo preferido para el aprendizaje profundo, R tiene fuertes capacidades en aprendizaje estadístico y aprendizaje automático tradicional. Esto puede ser ventajoso cuando su segmentación de datos implica enfoques basados en modelos o cuando necesita analizar las propiedades estadísticas de sus subconjuntos.
Puede ejecutar este código en la versión Posit Cloud de RStudio con una cuenta gratuita.
# Cargar la librería necesaria
library(dplyr)
# Supongamos que tenemos un gran conjunto de datos llamado 'full_dataset'
# Para este ejemplo, crearemos un conjunto de datos de muestra
set.seed(123) # para reproducibilidad
full_dataset <- data.frame(
id = 1:1000,
category = sample(c("A", "B", "C"), 1000, replace = TRUE),
value = rnorm(1000)
)
# Crear un subconjunto basado en una condición y muestreo aleatorio
subset_data <- full_dataset %>%
filter(category == "A") %>%
sample_n(100)
# Ver las primeras filas del subconjunto
head(subset_data)
# Guardar el subconjunto en un archivo CSV
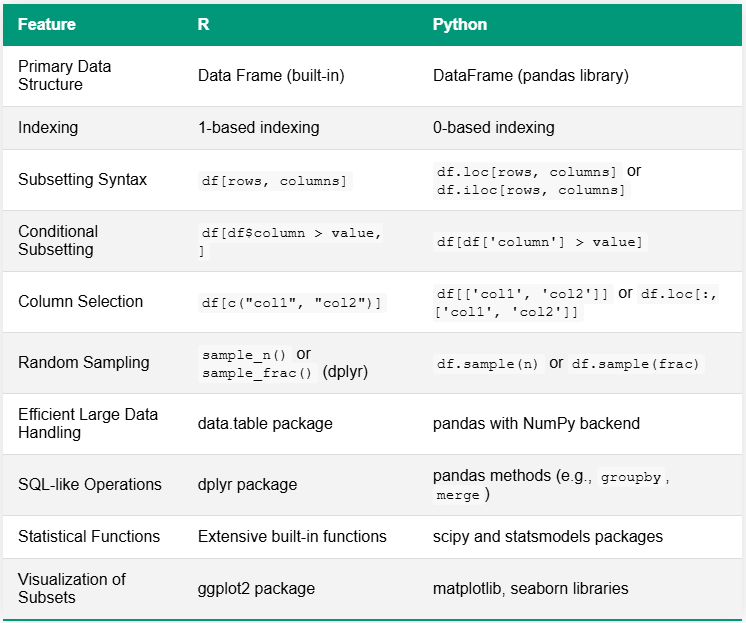
write.csv(subset_data, "category_A_subset.csv", row.names = FALSE)La tabla a continuación compara R y Python para tareas de segmentación de datos, destacando las diferencias clave en sintaxis y funcionalidad. Una distinción notable radica en sus ecosistemas: R a menudo tiene funciones incorporadas o depende de algunos paquetes integrales, mientras que Python generalmente utiliza una variedad de bibliotecas especializadas para capacidades similares.
Herramientas de Código Abierto para la Segmentación de Datos
Hay varias herramientas de código abierto disponibles para necesidades más avanzadas:
- Jailer: Una herramienta de segmentación de bases de datos que preserva la integridad referencial.
- Benerator CE: Un marco de trabajo de código abierto para generar y segmentar datos de prueba.
- Subsetter: Una biblioteca de Python para segmentar bases de datos relacionales manteniendo la integridad referencial.
Estas herramientas ofrecen características más sofisticadas, como mantener relaciones complejas entre tablas y generar datos sintéticos para complementar subconjuntos.
Mejores Prácticas para una Segmentación de Datos Efectiva
Para aprovechar al máximo la segmentación de datos, considere estas mejores prácticas:
- Mantener la Integridad de los Datos: Asegúrese de que su subconjunto preserve las relaciones y restricciones del conjunto de datos original.
- Usar Muestras Representativas: Procure crear subconjuntos que representen con precisión las características del conjunto de datos completo.
- Considerar la Sensibilidad de los Datos: Al segmentar para pruebas o desarrollo, tenga en cuenta la información sensible y aplique técnicas adecuadas de anonimización.
- Documentar su Proceso: Mantenga registros claros de cómo se crearon los subconjuntos para asegurar la reproducibilidad.
- Validar sus Subconjuntos: Revise regularmente que sus subconjuntos representen con precisión el conjunto de datos completo a medida que evoluciona con el tiempo.
Desafíos en la Segmentación de Datos
A pesar de los muchos beneficios que ofrece este procesamiento de datos, no está exento de desafíos:
- Mantenimiento de Relaciones de Datos: En bases de datos complejas, preservar la integridad referencial puede ser difícil.
- Asegurar Muestras Representativas: Puede ser un desafío crear subconjuntos que representen con precisión todos los aspectos del conjunto de datos completo.
- Manejo de Datos de Series Temporales: Segmentar datos de series temporales mientras se mantienen los patrones temporales requiere una consideración cuidadosa.
- Escalado con Grandes Datos: A medida que los conjuntos de datos crecen, incluso la creación de subconjuntos puede volverse intensiva en recursos computacionales.
Conclusión
La segmentación de datos es una técnica poderosa que puede mejorar significativamente sus prácticas de gestión de datos. Al crear conjuntos de datos más pequeños y manejables, puede mejorar el rendimiento, reducir costos y agilizar sus procesos de desarrollo y prueba. Ya sea que esté utilizando SQL, Python o herramientas especializadas, dominar la segmentación de datos es una habilidad esencial para cualquier profesional de datos.
A medida que inicie su viaje en la segmentación de datos, recuerde que la clave del éxito radica en mantener la integridad de los datos, asegurar la representatividad y elegir las herramientas adecuadas para sus necesidades específicas.
