Guía integral sobre cómo buscar datos sensibles en imágenes alojadas en AWS S3
Para proporcionar a nuestros clientes una poderosa herramienta de descubrimiento de datos, hace algún tiempo presentamos la funcionalidad OCR (Reconocimiento Óptico de Caracteres) integrada en nuestro módulo de Descubrimiento de Datos. Esta característica le permite buscar datos sensibles como datos personales, números de tarjetas de crédito, licencias de conducir, etc., contenidos en archivos de imagen. El proceso de descubrimiento se realiza automáticamente sin necesidad de intervención humana. OCR Data Discovery funciona solo con AWS S3 por ahora.
El OCR DD de DataSunrise se basa en el motor Tesseract, el cual utiliza tecnología de red neuronal para el reconocimiento de caracteres. Tesseract usa la biblioteca Leptonica para leer imágenes con uno de estos formatos:
- PNG
- JPEG
- TIFF
- JPEG 2000
- GIF
- WebP (incluyendo WebP animado)
- BMP
- PNM
Cómo funciona
Una vez que se inicia una tarea de OCR Data Discovery, el proceso de descubrimiento pasa por las siguientes fases:
- DataSunrise explora el contenido del bucket S3 especificado en busca de imágenes.
- El preprocesador del motor OCR prepara las imágenes descubiertas para un procesamiento posterior, haciéndolas más contrastadas y nítidas.
- Con la ayuda de la tecnología Tesseract OCR, DataSunrise reconoce el texto no estructurado en las imágenes y utiliza algoritmos de Descubrimiento de Datos en relación con este texto de acuerdo con la configuración de su tarea de Descubrimiento de Datos.
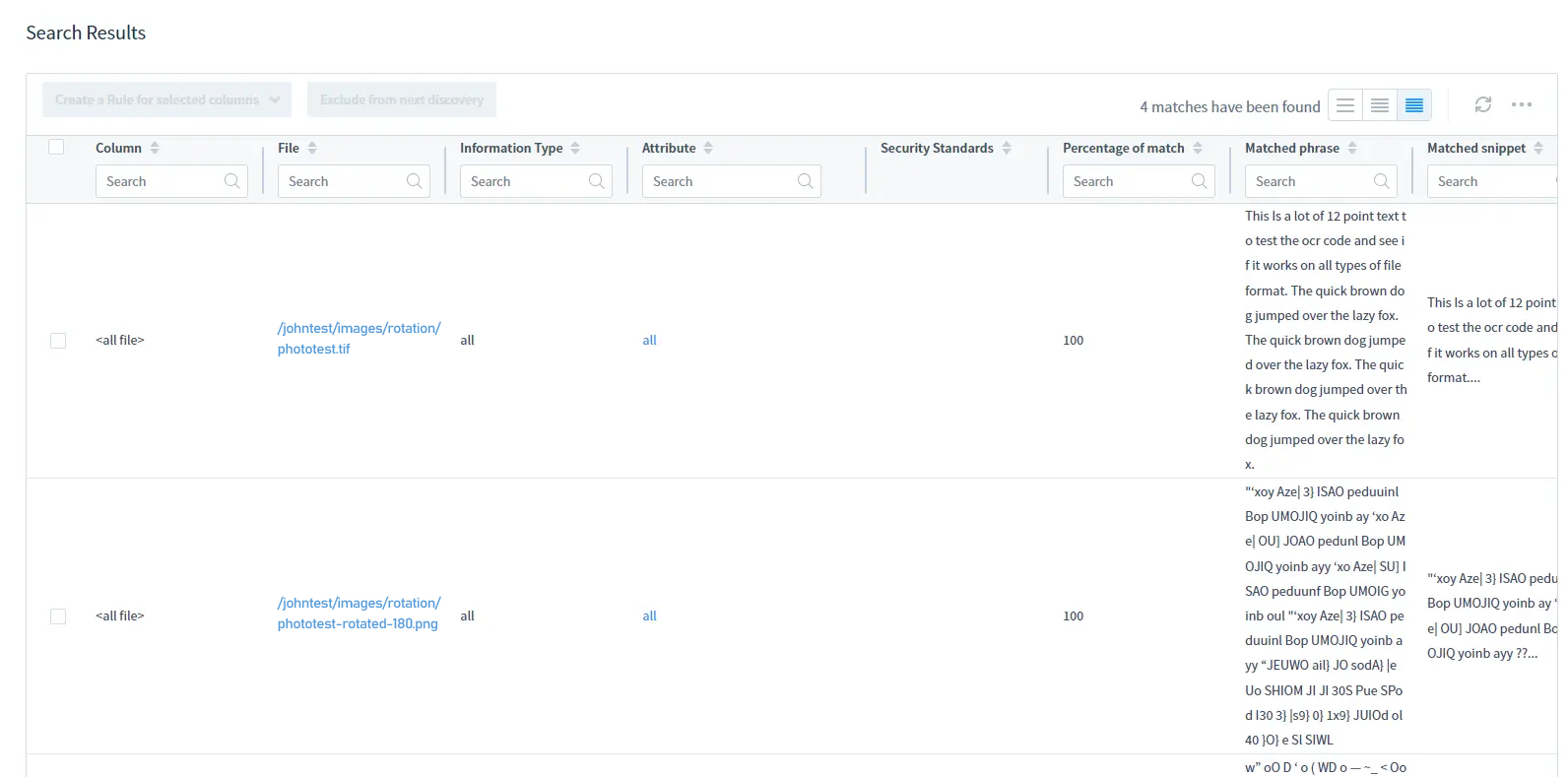
Como resultado, obtiene los nombres y la ubicación de los archivos de imagen que contienen datos sensibles y esos datos en un informe de DD.
Configurando una tarea OCR en DataSunrise
Ahora echemos un vistazo al proceso de creación de una tarea de OCR Data Discovery.
Primero, tenga en cuenta que OCR Data Discovery con NLP Data Discovery requiere Java 1.8+
Para utilizar OCR Data Discovery, debe hacer lo siguiente:
- Antes de proceder al siguiente paso, cree una instancia de S3 DB en DataSunrise (consulte la Guía del usuario de DataSunrise para más detalles).
- Navegue hasta Data Discovery → Periodic Data Discovery
- Cree una tarea de Descubrimiento de Datos para su bucket S3:
Complete la sección de Configuración General:

- Nombre de la tarea
- Seleccione el servidor DS donde iniciar la tarea
- Si desea realizar el Descubrimiento de Datos para múltiples instancias de BD, marque la casilla correspondiente y seleccione las instancias de interés
- Marque la casilla Generar Informes para crear un informe en formato PDF o CSV.
En la sección de Parámetros de Búsqueda:
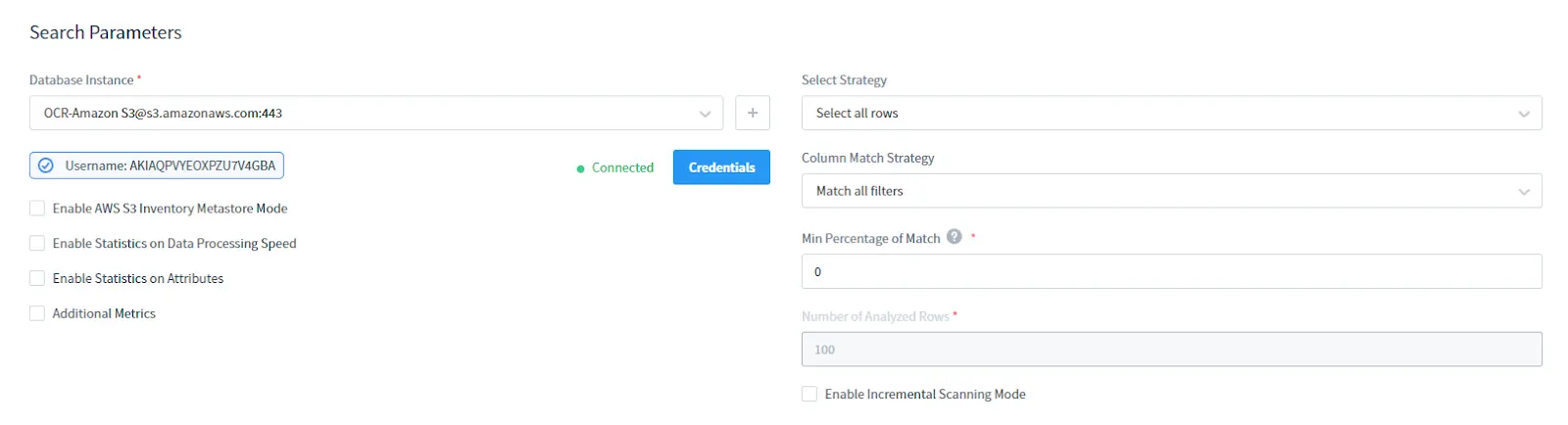
- Seleccione su instancia de S3 DB en AWS. Proporcione credenciales para su S3
- Elija la estrategia de selección: seleccionar todas las filas o solo las filas superiores
- Seleccione la estrategia de coincidencia de columnas: tipo de filtrado de columnas
- Establezca el porcentaje mínimo de coincidencia: es el porcentaje mínimo de filas en una columna que coinciden con las condiciones del filtro de búsqueda para considerar que la columna contiene los datos sensibles requeridos
- Seleccione el número de filas analizadas: número de filas analizadas que se seleccionarán
En Parámetros Multiproceso:

Seleccione la estrategia de ejecución: servidor DS único o múltiples servidores DS para cálculo paralelo
Seleccione los objetos de BD para buscar:

Utilice el árbol de objetos para especificar los objetos que deben ser explorados durante la ejecución de la tarea
Puede excluir ciertos objetos de la búsqueda utilizando el árbol de objetos correspondiente:

En Configuración de Búsqueda:
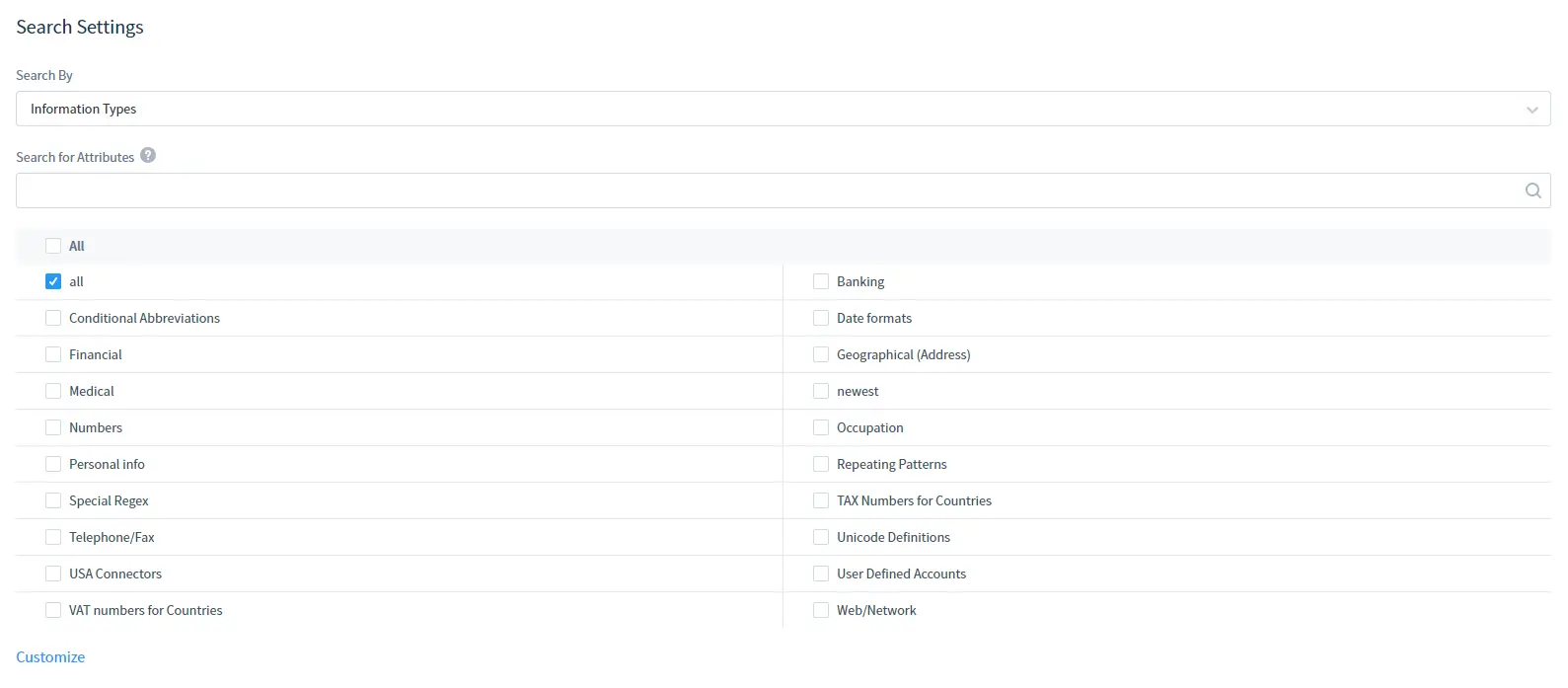
Seleccione el tipo de información o los estándares de seguridad según los cuales buscar. Tenga en cuenta que también puede usar la búsqueda por atributos para encontrar un tipo de información o estándar de seguridad según el atributo.
En Frecuencia de Inicio:
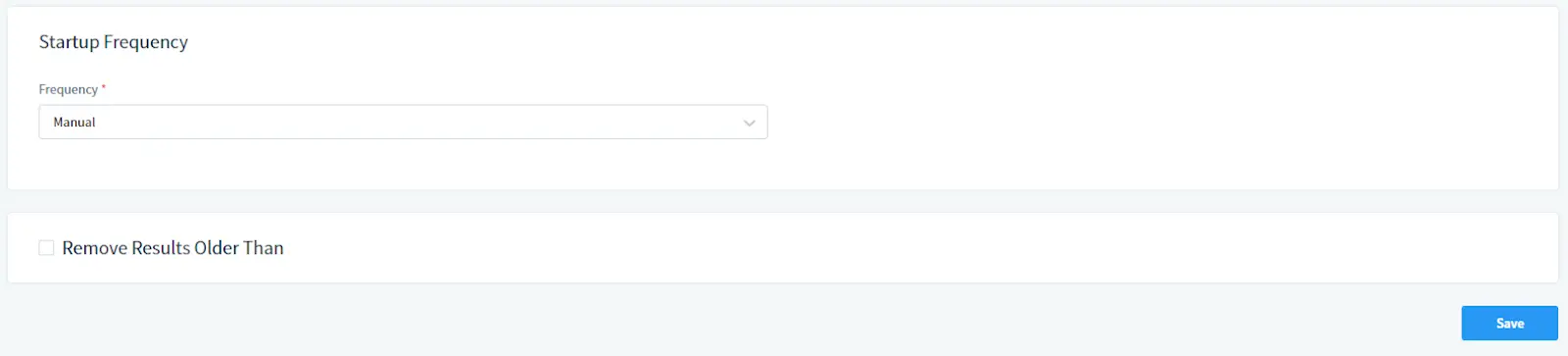
Seleccione la frecuencia de ejecución de la tarea. Seleccione Manual para iniciar manualmente o establezca un horario.
Importante: necesita habilitar el parámetro adicional imageDataDiscovery antes de ejecutar la tarea. Puede hacerlo en Parámetros Adicionales (Configuración del Sistema -> Parámetros Adicionales) o en la subsección de Configuración Adicional Personalizada de la página de tareas.
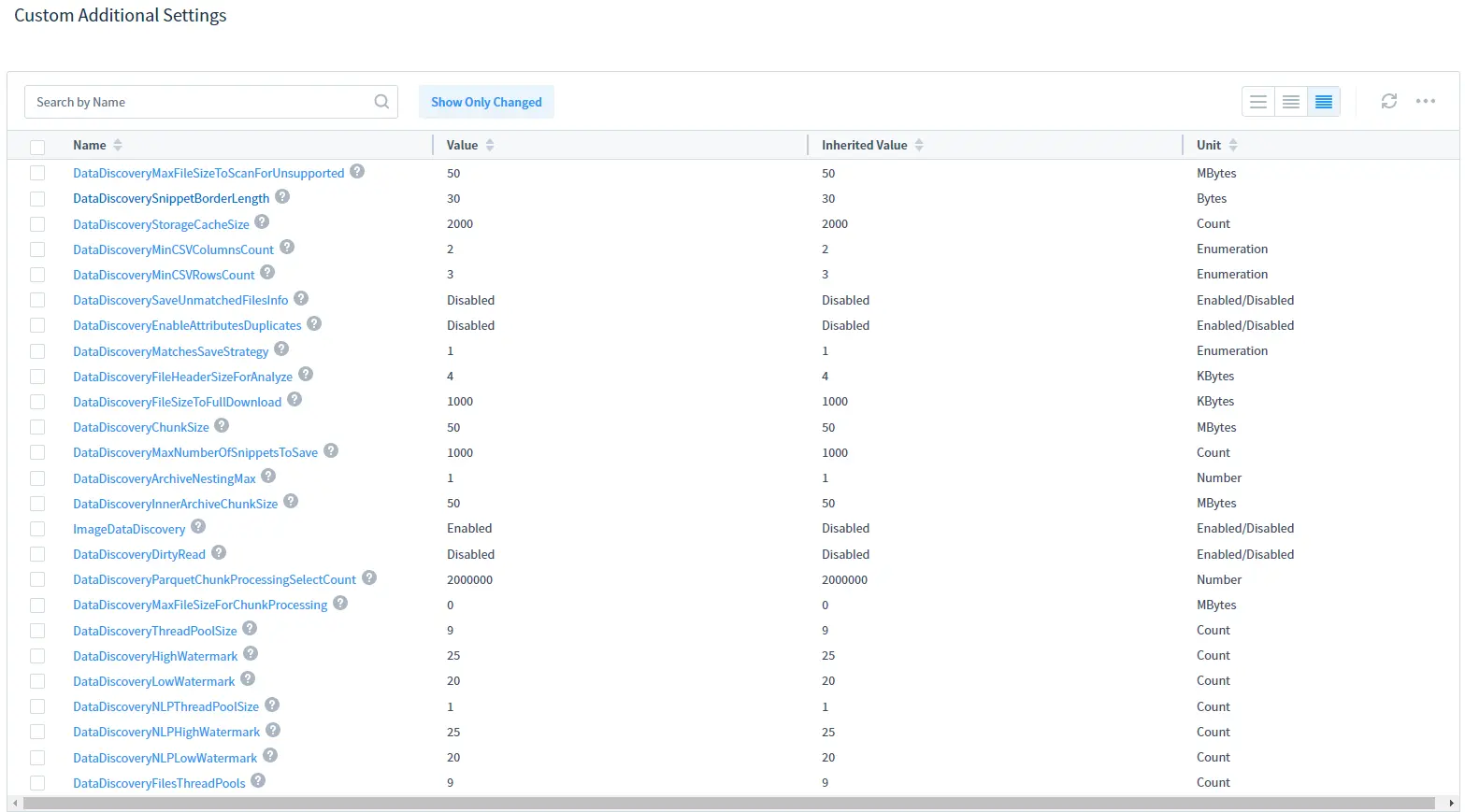
Seleccione imageDataDiscovery en la lista y actívelo como se muestra a continuación:
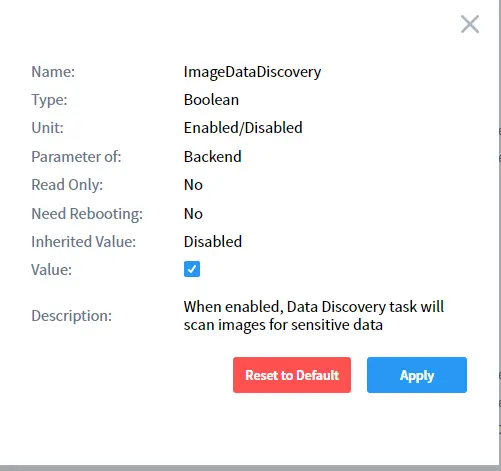
Ejecute la tarea manualmente o según lo programado y DataSunrise realizará el descubrimiento OCR automáticamente:
{kind=link}
Para los resultados de búsqueda, consulte la tabla de Resultados de Búsqueda: