Cómo Controlar la Visibilidad de los Nombres de las Tablas
Manejar el acceso a un volumen considerable de datos dentro de una organización presenta desafíos considerables. Particularmente, cuando están involucradas numerosas personas, asegurar un acceso controlado se convierte en una tarea compleja.
Dadas estas circunstancias, la necesidad de protección de datos se vuelve primordial. El acceso y la manipulación no autorizados pueden llevar a consecuencias significativas, resaltando la importancia de implementar fuertes medidas de seguridad.
Entendiendo la importancia de esta preocupación, DataSunrise ofrece una solución conocida como Enmascaramiento de Datos. Al adoptar esta estrategia, las organizaciones pueden proteger sus datos de actividades no autorizadas, fortaleciendo así sus defensas contra riesgos potenciales. El Enmascaramiento de Datos surge como una herramienta crucial entre diversas medidas de protección, permitiendo a las organizaciones mantener la integridad y confidencialidad de los datos en el complicado panorama de las dinámicas de información modernas.
El Enmascaramiento de Datos ofrece más que solo enmascarar datos – también proporciona la opción de ocultar filas enteras de información. Al crear una regla de enmascaramiento, se puede restringir a grupos de usuarios específicos del acceso a ciertas porciones de datos, asegurando que solo la información relevante esté disponible para sus tareas.
Para ilustrar, tomemos el escenario donde queremos ocultar nombres de tablas basándonos en varios departamentos dentro de la organización usando la función “OCULTAR FILAS” dentro de DataSunrise.
Para el propósito de visualización, supongamos que hemos establecido una conexión con una base de datos local PostgreSQL en DataSunrise y hemos integrado también la conexión de proxy.
Primero, crearemos una regla de enmascaramiento ejecutando los siguientes pasos.
Vaya a Enmascaramiento > Regla de Enmascaramiento Dinámico > Crear Nueva Regla.
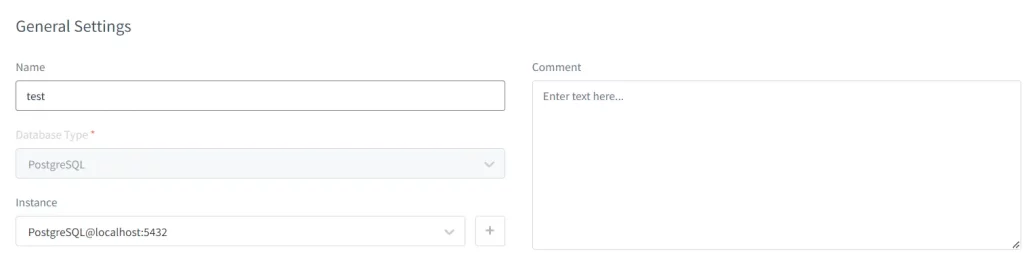
En la Configuración General, dé un nombre apropiado a la regla que va a crear. Elija el tipo de base de datos y la instancia a la que le gustaría aplicar esta regla.
Además, no olvide habilitar la casilla de verificación de Evento de Registro en Almacenamiento para que pueda verificar los eventos de enmascaramiento que ocurren en la sección de Eventos de Enmascaramiento Dinámico. Otros campos son opcionales y pueden dejarse sin completar si no es necesario.
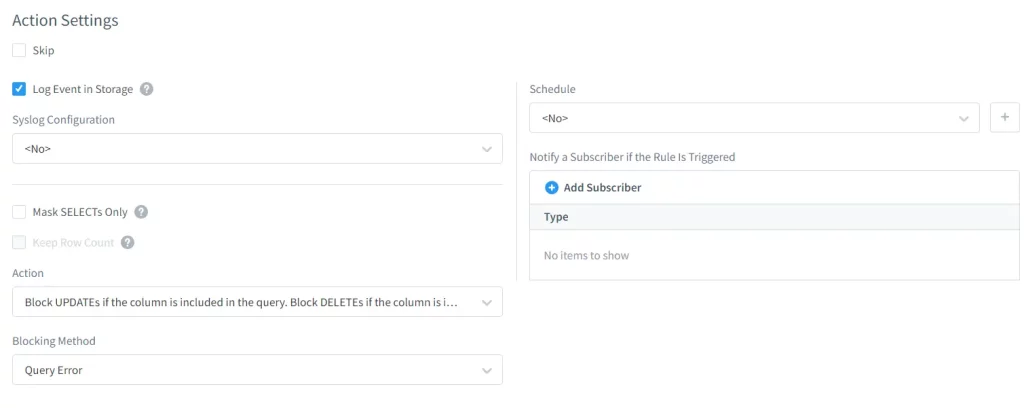
Luego, en la sesión de filtro, podemos configurar las condiciones necesarias. Por ejemplo, podemos determinar que la regla es aplicable para usuarios específicos de la base de datos o Grupo de Usuarios de BD. Aquí, como no quiero que datos no relacionados como los datos del departamento de RRHH estén disponibles para el usuario “developer1”, excluiré a este usuario. Entonces, si alguien ingresa al DBMS con la cuenta de usuario “developer1”, no podrá acceder a los datos restringidos.

O si es necesario ocultar los datos de múltiples usuarios (por ejemplo, developer1+developer2 = grupo de “testers”), hay una opción para recolectar los usuarios en grupos asociados.
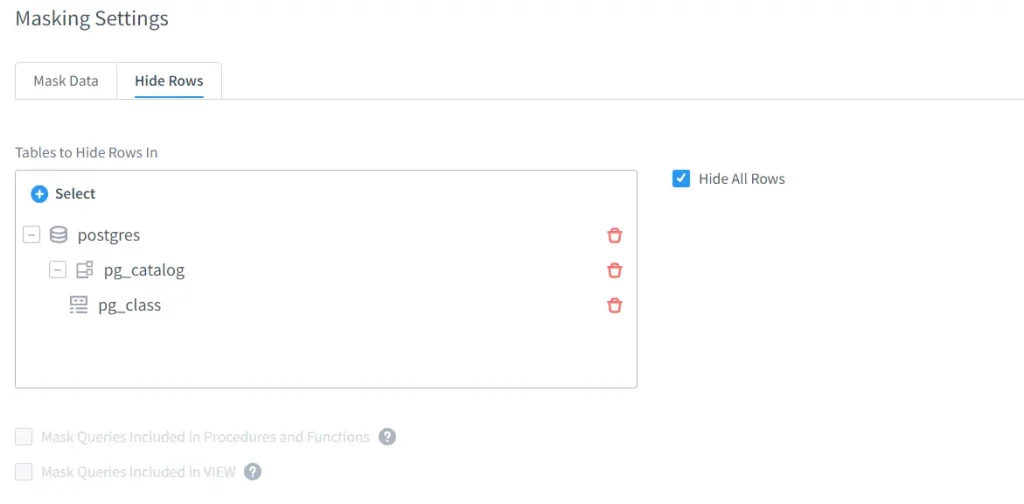
Finalmente, se puede configurar la principal configuración de enmascaramiento. Dado que estamos discutiendo un tema sobre ocultar el nombre de las tablas en este artículo, nos quedaremos con la opción “Ocultar Filas”.
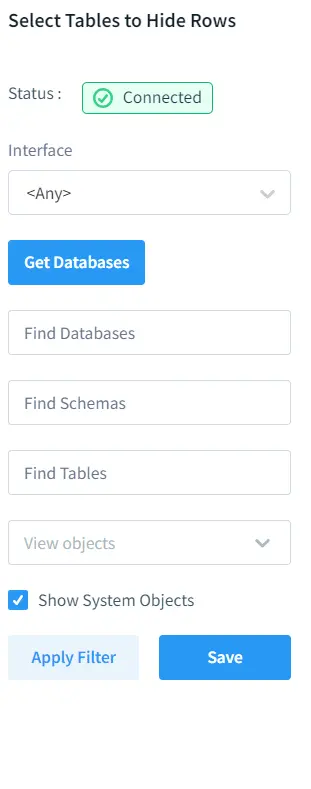
Después de elegir “Ocultar Fila”, se navegará a la configuración necesaria para ocultar las tablas. Aquí, gestionaremos la visibilidad de los nombres de las tablas que se encuentran en la instancia. Por lo tanto, ocultaremos las filas del objeto del sistema que es pg_catalog.pg_class. Para poder seleccionar los objetos del sistema, es importante activar la casilla llamada “Mostrar Objetos del Sistema”.
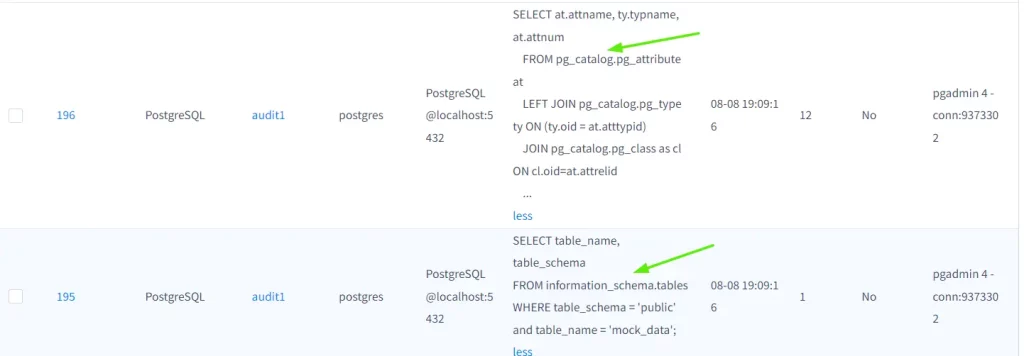
Nota: Si no está seguro sobre qué tabla de objetos del sistema se utiliza en PgAdmin para construir la visualización de la interfaz de usuario, el monitoreo de actividad de datos de DataSunrise (Servicio de Auditoría) es de gran ayuda para usted. Se recomienda activar la configuración a continuación porque es posible que necesite probar múltiples consultas para asegurarse y verificar la sección de seguimiento después de ejecutar las consultas.
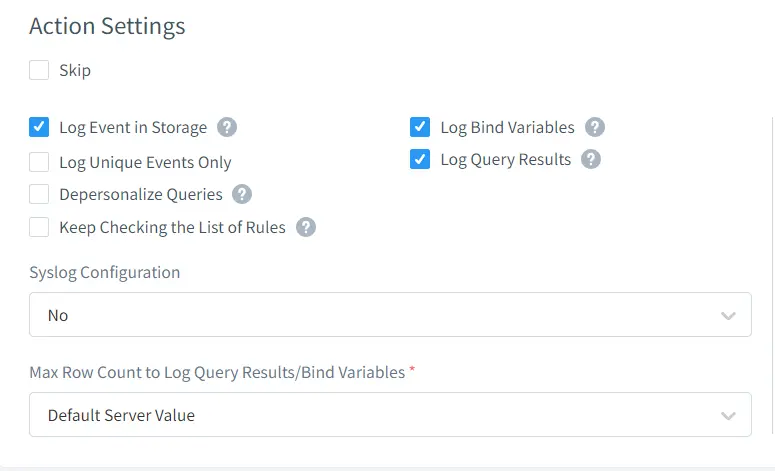
Habrá algunas consultas sobre la consulta real ejecutada. Al ingresar el “ID” de traducción, podrá verificar los detalles de cómo se recopilan y muestran los datos en la interfaz de usuario.
Además de elegir “Ocultar Todas las Filas”, también está disponible ocultar solo las filas relevantes que contienen la palabra clave particular al establecer la condición para el valor de las filas de la columna que deben ocultarse.
Aquí, como mencioné anteriormente, no quiero dar acceso a los datos del departamento de RRHH al usuario “developer1”. Pero, los datos del departamento de TI serán visibles para él. Por lo tanto, filtraré los nombres de las tablas que contienen “it” en ellas para que estas tablas del departamento de TI se muestren al usuario “developer1”.
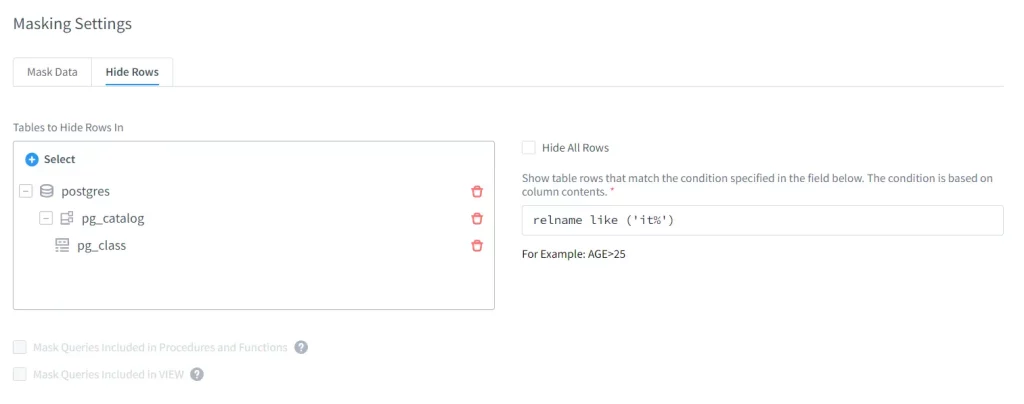
Cuando termine de configurar todas las configuraciones anteriores, haga clic en “guardar” para guardar la regla.
Ahora, todas las configuraciones necesarias para ocultar la tabla han sido configuradas y la regla está lista para aplicarse.
Probemos y verifiquemos si la regla de enmascaramiento creada funciona correctamente.
Para la prueba, demostraremos usando pgadmin. En pgadmin, conéctese a la misma base de datos por proxy. Primero, me conectaré como usuario “postgres”.
Luego, pruebe la regla de enmascaramiento ejecutando la consulta select simple.
SELECT * FROM pg_catalog.pg_class;
Después de la ejecución, aún puede ver la tabla de la base de datos de salida con datos de ambos departamentos, TI y RRHH, dentro de la tabla. Los nombres de las tablas aún son visibles en el panel izquierdo también. Porque, el usuario “postgres” no fue elegido como usuario de la base de datos restringido.
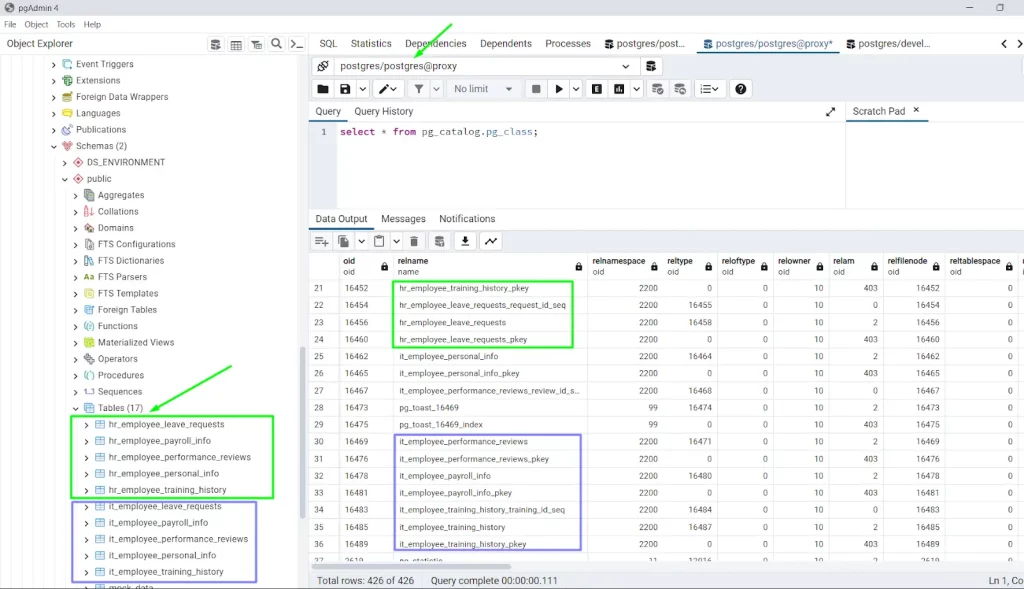
Cuando nos conectamos como usuario de la base de datos “developer1”, no podremos ver las filas relacionadas con RRHH dentro de la tabla “pg_catalog.pg_class” porque este usuario tiene acceso restringido a los datos del departamento de RRHH, pero aún podrá acceder a los datos del departamento de TI. De manera similar, la visualización de la interfaz de usuario en el panel izquierdo cambiará. Las tablas que no sean del departamento de TI desaparecerán.
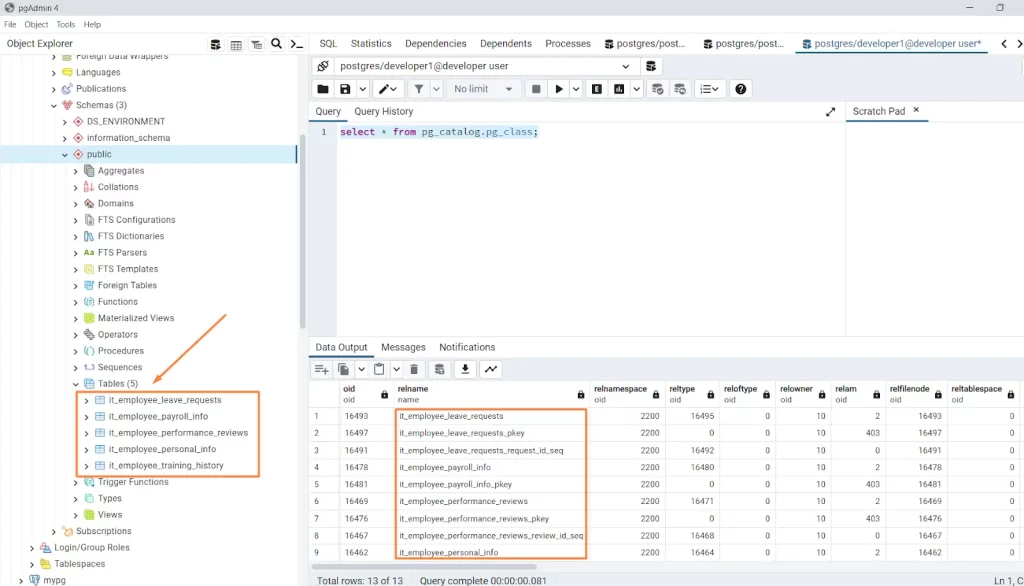
De esta forma, “Ocultar Filas” del Enmascaramiento Dinámico de Datos puede utilizarse para proteger los datos, incluso objetos del sistema como nombres de tablas, de usuarios no deseados de manera eficiente.